Eu vou ser minucioso sobre a escolha de palavras por um momento:
- Mesmo que fosse um fator de desempenho significativo, isso não o torna semanticamente correto usar um valor em vez de NULL. No SQL, NULL tem uma função semântica, para denotar um valor ausente ou inaplicável. As características de desempenho de NULL em uma determinada implementação de RDBMS são independentes disso. O desempenho pode variar de marca para marca ou de versão para versão, mas o objetivo de NULL no idioma é consistente.
De qualquer forma, não ouvi falar de nenhuma evidência de que NULL tenha um desempenho ruim. Eu estaria interessado em quaisquer referências a medições de desempenho que mostrem que as colunas anuláveis têm um desempenho pior do que as colunas não anuláveis.
Não estou dizendo que não estou errado ou que não pode ser verdade em alguns casos - apenas que não faz sentido fazer suposições ociosas. A ciência não é feita de conjecturas; é preciso mostrar evidências com medições repetíveis.
As métricas também informam por quanto o desempenho é diferente, então você pode fazer um julgamento sobre se vale a pena se preocupar. Ou seja, o impacto pode ser mensurável e diferente de zero, mas ainda insignificante em comparação com fatores de desempenho maiores, como indexar corretamente as tabelas ou dimensionar o cache do banco de dados.
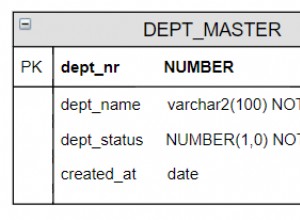
No MySQL, as pesquisas por NULL podem se beneficiar de um índice:
mysql> CREATE TABLE foo (
i INT NOT NULL,
j INT DEFAULT NULL,
PRIMARY KEY (i),
UNIQUE KEY j_index (j)
);
mysql> INSERT INTO foo (i, j) VALUES
(1, 1), (2, 2), (3, NULL), (4, NULL), (5, 5);
mysql> EXPLAIN SELECT * FROM foo WHERE i = 3;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | foo | const | PRIMARY | PRIMARY | 4 | const | 1 | |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
mysql> EXPLAIN SELECT * FROM foo WHERE j IS NULL;
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | foo | ref | j_index | j_index | 5 | const | 2 | Using where |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
Observe que ainda não é uma medida de desempenho. Mostrei apenas que você pode usar um índice enquanto procura por NULL. Vou afirmar (reconhecidamente sem ter medido, mas ei, isso é apenas StackOverflow) que o benefício de um índice ofusca qualquer penalidade possível ao procurar por NULL versus uma string em branco.
Não é uma decisão de projeto correta escolher zero ou branco ou qualquer outro valor para substituir NULL. Pode ser necessário usar esses valores como significativos na coluna. É por isso que NULL existe, como um valor que está, por definição, fora do domínio de valores de qualquer tipo de dados, então você pode usar todo o intervalo de valores de inteiros ou strings ou qualquer outra coisa e ainda ter algo para significar "nenhum dos valores acima. "