Todos vocês já ouviram falar sobre dimensionamento - sua arquitetura deve ser dimensionável, você deve ser capaz de dimensionar para atender à demanda, e assim por diante. O que significa quando falamos de bancos de dados? Como é o dimensionamento nos bastidores? Este tópico é vasto e não há como cobrir todos os aspectos. Esta série de duas postagens de blog é uma tentativa de fornecer uma visão sobre o tópico de escalabilidade de banco de dados.
Por que escalamos?
Primeiro, vamos dar uma olhada no que é escalabilidade. Em suma, estamos falando da capacidade de lidar com cargas mais altas por seus sistemas de banco de dados. Pode ser uma questão de lidar com picos de curta duração na atividade, pode ser uma questão de lidar com uma carga de trabalho gradualmente aumentada em seu ambiente de banco de dados. Pode haver inúmeras razões para considerar o dimensionamento. A maioria deles vem com seus próprios desafios. Podemos passar algum tempo analisando exemplos da situação em que podemos querer expandir.
Aumento do consumo de recursos
Este é o mais genérico - sua carga aumentou até o ponto em que seus recursos existentes não são mais capazes de lidar com isso. Pode ser qualquer coisa. A carga da CPU aumentou e seu cluster de banco de dados não consegue mais fornecer dados com tempo de execução de consulta razoável e estável. A utilização da memória aumentou a ponto de o banco de dados não estar mais vinculado à CPU, mas se tornar vinculado a E/S e, como tal, o desempenho dos nós do banco de dados foi reduzido significativamente. A rede também pode ser um bootle-neck. Você pode se surpreender ao ver quais limites relacionados à rede têm suas instâncias de nuvem atribuídas. Na verdade, esse pode se tornar o limite mais comum com o qual você precisa lidar, pois a rede é tudo na nuvem - não apenas os dados enviados entre o aplicativo e o banco de dados, mas também o armazenamento conectado à rede. Também pode ser o uso do disco - você está apenas ficando sem espaço em disco ou, mais provavelmente, dado que podemos ter discos bastante grandes hoje em dia, o tamanho do banco de dados superou o tamanho "gerenciável". A manutenção como a mudança de esquema se torna um desafio, o desempenho é reduzido devido ao tamanho dos dados, os backups estão demorando muito para serem concluídos. Todos esses casos podem ser um caso válido para a necessidade de expansão.
Aumento repentino na carga de trabalho
Outro caso de exemplo em que o dimensionamento é necessário é um aumento repentino na carga de trabalho. Por algum motivo (seja esforços de marketing, conteúdo viralizando, emergência ou situação semelhante), sua infraestrutura sofre um aumento significativo na carga no cluster de banco de dados. A carga da CPU ultrapassa o teto, a E/S do disco está diminuindo a velocidade das consultas, etc. Praticamente todos os recursos que mencionamos na seção anterior podem ser sobrecarregados e começar a causar problemas.
Operação planejada
O terceiro motivo que gostaríamos de destacar é o mais genérico - algum tipo de operação planejada. Pode ser uma atividade de marketing planejada que você espera trazer mais tráfego, Black Friday, testes de carga ou praticamente qualquer coisa que você saiba com antecedência.
Cada uma dessas razões tem suas próprias características. Se você puder planejar com antecedência, poderá preparar o processo em detalhes, testá-lo e executá-lo sempre que quiser. Você provavelmente gostará de fazer isso em um período de “baixo tráfego”, desde que algo assim exista em suas cargas de trabalho (não precisa existir). Por outro lado, picos repentinos na carga, especialmente se forem significativos o suficiente para impactar a produção, forçarão uma reação imediata, não importa o quão preparado você esteja e quão seguro seja - se seus serviços já foram impactados, você pode simplesmente ir para ele em vez de esperar.
Tipos de dimensionamento de banco de dados
Existem dois tipos principais de dimensionamento:vertical e horizontal. Ambos têm prós e contras, ambos são úteis em diferentes situações. Vamos dar uma olhada neles e discutir casos de uso para ambos os cenários.
Escala vertical
Este método de dimensionamento é provavelmente o mais antigo:se o seu hardware não for robusto o suficiente para lidar com a carga de trabalho, reforce-o. Estamos falando aqui simplesmente sobre adicionar recursos aos nós existentes com a intenção de torná-los capazes o suficiente para lidar com as tarefas dadas. Isso tem algumas repercussões que gostaríamos de analisar.
Vantagens do dimensionamento vertical
A parte mais importante é que tudo permanece igual. Você tinha três nós em um cluster de banco de dados, você ainda tem três nós, apenas mais capazes. Não há necessidade de reprojetar seu ambiente, alterar como o aplicativo deve acessar o banco de dados - tudo permanece exatamente o mesmo porque, em termos de configuração, nada realmente mudou.
Outra vantagem significativa do dimensionamento vertical é que ele pode ser muito rápido, especialmente em ambientes de nuvem. Todo o processo é, basicamente, parar o nó existente, fazer a alteração no hardware, iniciar o nó novamente. Para configurações clássicas no local, sem qualquer virtualização, isso pode ser complicado - você pode não ter CPUs mais rápidas disponíveis para troca, atualizar discos para maiores ou mais rápidos também pode ser demorado, mas para ambientes de nuvem, seja público ou privado, isso pode ser tão fácil quanto executar três comandos:parar a instância, atualizar a instância para um tamanho maior, iniciar a instância. Os IPs virtuais e os volumes reanexáveis facilitam a movimentação de dados entre instâncias.
Desvantagens do dimensionamento vertical
A principal desvantagem do dimensionamento vertical é que, simplesmente, ele tem seus limites. Se você estiver executando no maior tamanho de instância disponível, com os volumes de disco mais rápidos, não há muito mais o que fazer. Também não é tão fácil aumentar significativamente o desempenho de seu cluster de banco de dados. Depende principalmente do tamanho inicial da instância, mas se você já estiver executando nós com bom desempenho, talvez não seja possível atingir a escalabilidade horizontal de 10 vezes usando a escala vertical. Nós que seriam 10x mais rápidos podem, simplesmente, não existir.
Escala horizontal
A escala horizontal é uma fera diferente. Em vez de aumentar o tamanho da instância, permanecemos no mesmo nível, mas expandimos horizontalmente adicionando mais nós. Novamente, existem prós e contras desse método.
Prós do dimensionamento horizontal
A principal vantagem da escala horizontal é que, teoricamente, o céu é o limite. Não há limite rígido artificial de dimensionamento, embora existam limites, principalmente devido à comunicação entre clusters sendo uma sobrecarga cada vez maior a cada novo nó adicionado ao cluster.
Outra vantagem significativa seria que você pode expandir o cluster sem a necessidade de tempo de inatividade. Se você deseja atualizar o hardware, precisa interromper a instância, atualizá-la e iniciar novamente. Se você quiser adicionar mais nós ao cluster, tudo o que você precisa fazer é provisionar esses nós, instalar qualquer software necessário, incluindo o banco de dados, e deixá-lo ingressar no cluster. Opcionalmente (dependendo se o cluster tiver métodos internos para provisionar novos nós com os dados), talvez seja necessário provisioná-lo com dados por conta própria. Normalmente, porém, é um processo automatizado.
Contras do dimensionamento horizontal
O principal problema com o qual você precisa lidar é que adicionar mais e mais nós dificulta o gerenciamento de todo o ambiente. Você precisa saber quais nós estão disponíveis, essa lista deve ser mantida e atualizada a cada novo nó criado. Você pode precisar de soluções externas como serviço de diretório (Consul ou Etcd) para acompanhar os nós e seu estado. Isso, obviamente, aumenta a complexidade de todo o ambiente.
Outro problema potencial é que o processo de expansão leva tempo. Adicionar novos nós e provisioná-los com software e, principalmente, dados requer tempo. Quanto, depende do hardware (principalmente E/S e taxa de transferência da rede) e do tamanho dos dados. Para configurações grandes, isso pode levar uma quantidade significativa de tempo e pode ser um bloqueador para situações em que a expansão precisa acontecer imediatamente. Esperar horas para adicionar novos nós pode não ser aceitável se o cluster de banco de dados for afetado na medida em que as operações não estiverem sendo executadas corretamente.
Pré-requisitos de dimensionamento
Replicação de dados
Antes que qualquer tentativa de dimensionamento possa ser feita, seu ambiente deve atender a alguns requisitos. Para começar, seu aplicativo deve ser capaz de tirar proveito de mais de um nó. Se ele puder usar apenas um nó, suas opções serão praticamente limitadas ao dimensionamento vertical. Você pode aumentar o tamanho de tal nó ou adicionar alguns recursos de hardware ao servidor bare metal e torná-lo mais eficiente, mas isso é o melhor que você pode fazer:você sempre será limitado pela disponibilidade de hardware com melhor desempenho e, eventualmente, encontrará você mesmo sem uma opção para aumentar ainda mais.
Por outro lado, se você tiver meios de utilizar vários nós de banco de dados por seu aplicativo, poderá se beneficiar do dimensionamento horizontal. Vamos parar por aqui e discutir o que você precisa para realmente usar vários nós em todo o seu potencial.
Para começar, a capacidade de dividir leituras de gravações. Tradicionalmente, o aplicativo se conecta a apenas um nó. Esse nó é usado para lidar com todas as gravações e todas as leituras executadas pelo aplicativo.

Adicionar um segundo nó ao cluster, do ponto de vista de dimensionamento, não muda nada . Você deve ter em mente que, se um nó falhar, o outro terá que lidar com o tráfego; portanto, em nenhum momento a soma da carga em ambos os nós deve ser muito alta para um único nó.

Com três nós disponíveis, você pode utilizar totalmente dois nós. Isso nos permite dimensionar parte do tráfego de leitura:se um nó tem 100% da capacidade (e preferimos executar no máximo 70%), então dois nós representam 200%. Três nós:300%. Se um nó estiver inativo e levarmos os nós restantes quase ao limite, podemos dizer que podemos trabalhar com 170 a 180% da capacidade de um único nó se o cluster estiver degradado. Isso nos dá uma boa carga de 60% em cada nó se todos os três nós estiverem disponíveis.
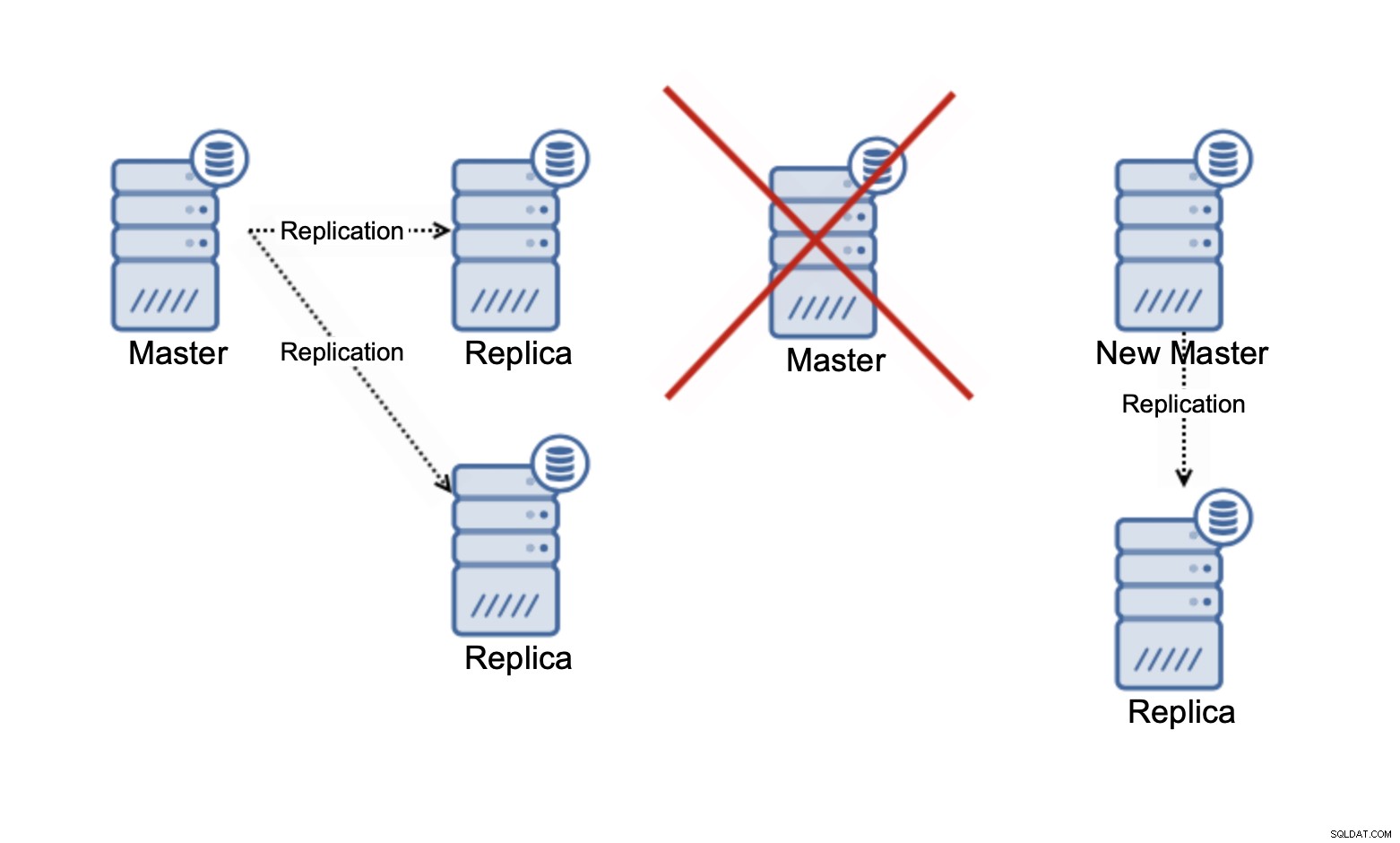
Por favor, tenha em mente que estamos falando apenas sobre escalar leituras neste momento . Em nenhum momento a replicação pode melhorar sua capacidade de gravação. Na replicação assíncrona, você tem apenas um gravador (mestre), e para a replicação síncrona, como Galera, onde o conjunto de dados é compartilhado em todos os nós, cada gravação que está acontecendo em um nó terá que ser realizada nos nós restantes da cacho.
Em um cluster Galera de três nós, se você escrever uma linha, na verdade você escreverá três linhas, uma para cada nó. Adicionar mais nós ou réplicas não fará diferença. Em vez de escrever a mesma linha em três nós, você a escreverá em cinco. É por isso que dividir suas gravações em um cluster multi-master, onde o conjunto de dados é compartilhado em todos os nós (há clusters multi-master onde os dados são fragmentados, por exemplo MySQL NDB Cluster - aqui a história de escalabilidade de gravação é totalmente diferente), não faz muito sentido. Ele adiciona sobrecarga de lidar com possíveis conflitos de gravação em todos os nós, enquanto não está realmente alterando nada em relação à capacidade total de gravação.
Balanceamento de carga e divisão de leitura/gravação
A capacidade de dividir leituras de gravações é essencial se você deseja dimensionar suas leituras em configurações de replicação assíncrona. Você precisa ser capaz de enviar tráfego de gravação para um nó e, em seguida, enviar as leituras para todos os nós na topologia de replicação. Como mencionamos anteriormente, essa funcionalidade também é bastante útil nos clusters multimestre, pois nos permite remover os conflitos de gravação que podem ocorrer se você tentar distribuir as gravações em vários nós do cluster. Como podemos executar a divisão de leitura/gravação? Existem vários métodos que você pode usar para fazer isso. Vamos nos aprofundar um pouco neste tópico.
Divisão R/W do nível de aplicativo
O cenário mais simples, o menos frequente também:sua aplicação pode configurar quais nós devem receber escritas e quais nós devem receber leituras. Essa funcionalidade pode ser configurada de duas maneiras, sendo a mais simples a lista codificada dos nós, mas também pode ser algo como o inventário de nós dinâmico atualizado por threads em segundo plano. O principal problema com essa abordagem é que toda a lógica deve ser escrita como parte do aplicativo. Com uma lista de nós codificada, o cenário mais simples exigiria alterações no código do aplicativo para cada alteração na topologia de replicação. Por outro lado, soluções mais avançadas, como implementar uma descoberta de serviço, seriam mais complexas de manter a longo prazo.
R/W dividido no conector
Outra opção seria usar um conector para realizar uma divisão de leitura/gravação. Nem todos têm essa opção, mas alguns têm. Um exemplo seria php-mysqlnd ou Connector/J. Como ele é integrado ao aplicativo, pode diferir com base no próprio conector. Em alguns casos, a configuração deve ser feita no aplicativo, em alguns casos, em um arquivo de configuração separado para o conector. A vantagem dessa abordagem é que, mesmo que você precise estender seu aplicativo, a maior parte do novo código estará pronta para uso e mantida por fontes externas. Isso torna mais fácil lidar com essa configuração e você precisa escrever menos código (se houver).
Divisão de R/W no balanceador de carga
Finalmente, uma das melhores soluções:balanceadores de carga. A ideia é simples - passe seus dados por um balanceador de carga que será capaz de distinguir entre leituras e gravações e enviá-los para um local adequado. Esta é uma grande melhoria do ponto de vista de usabilidade, pois podemos separar a descoberta de banco de dados e o roteamento de consulta do aplicativo. A única coisa que o aplicativo precisa fazer é enviar o tráfego do banco de dados para um único endpoint que consiste em um nome de host e uma porta. O resto acontece em segundo plano. Os balanceadores de carga estão trabalhando para rotear as consultas para nós de banco de dados de back-end. Os balanceadores de carga também podem fazer a descoberta de topologia de replicação ou você pode implementar um inventário de serviço adequado usando etcd ou consul e atualizá-lo por meio de suas ferramentas de orquestração de infraestrutura, como o Ansible.
Isso conclui a primeira parte deste blog. Na segunda, discutiremos os desafios que enfrentamos ao dimensionar a camada do banco de dados. Também discutiremos algumas maneiras pelas quais podemos dimensionar nossos clusters de banco de dados.



