No meu post anterior eu expliquei como fazer um backup lógico usando os utilitários do shell mysql. Neste post, vamos comparar a velocidade do processo de backup e restauração.
Teste de velocidade do MySQL Shell
Faremos uma comparação da velocidade de backup e recuperação das ferramentas de utilitário shell mysqldump e MySQL.
As ferramentas abaixo são usadas para comparação de velocidade:
- mysqldump
- util.dumpInstance
- util.loadDump
Configuração de hardware
Dois servidores autônomos com configurações idênticas.
Servidor 1
* IP:192.168.33.14
* CPU:2 núcleos
* RAM:4 GB
* DISCO:SSD de 200 GB
Servidor 2
* IP:192.168.33.15
* CPU:2 núcleos
* RAM:4 GB
* DISCO:SSD de 200 GB
Preparação da carga de trabalho
No servidor 1 (192.168.33.14), carregamos aproximadamente 10 GB de dados.
Agora, queremos restaurar os dados do Servidor 1 (192.168.33.14) para o Servidor 2 (192.168.33.15).
Configuração do MySQL
Versão do MySQL:8.0.22
Tamanho do pool de buffers do InnoDB:1 GB
Tamanho do arquivo de log do InnoDB:16 MB
Registro binário:ativado
Carregamos 50 milhões de registros usando o sysbench.
[example@sqldat.com sysbench]# sysbench oltp_insert.lua --table-size=5000000 --num-threads=8 --rand-type=uniform --db-driver=mysql --mysql-db=sbtest --tables=10 --mysql-user=root --mysql-password=****** prepare
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest3'...
Creating table 'sbtest4'...
Creating table 'sbtest7'...
Creating table 'sbtest1'...
Creating table 'sbtest2'...
Creating table 'sbtest8'...
Creating table 'sbtest5'...
Creating table 'sbtest6'...
Inserting 5000000 records into 'sbtest1'
Inserting 5000000 records into 'sbtest3'
Inserting 5000000 records into 'sbtest7
.
.
.
Creating a secondary index on 'sbtest9'...
Creating a secondary index on 'sbtest10'...Caso de Teste Um
Neste caso vamos fazer um backup lógico usando o comando mysqldump.
Exemplo
[example@sqldat.com vagrant]# time /usr/bin/mysqldump --defaults-file=/etc/my.cnf --flush-privileges --hex-blob --opt --master-data=2 --single-transaction --triggers --routines --events --set-gtid-purged=OFF --all-databases |gzip -6 -c > /home/vagrant/test/mysqldump_schemaanddata.sql.gzstart_time =2020-11-09 17:40:02
horário_final =09/11/2020 37:19:08
Levou quase 20 minutos e 19 segundos para fazer um dump de todos os bancos de dados com um tamanho total de cerca de 10 GB.
Caso de Teste Dois
Agora vamos tentar com o utilitário shell do MySQL. Vamos usar dumpInstance para fazer um backup completo.
Exemplo
MySQL localhost:33060+ ssl JS > util.dumpInstance("/home/vagrant/production_backup", {threads: 2, ocimds: true,compatibility: ["strip_restricted_grants"]})
Acquiring global read lock
Global read lock acquired
All transactions have been started
Locking instance for backup
Global read lock has been released
Checking for compatibility with MySQL Database Service 8.0.22
NOTE: Progress information uses estimated values and may not be accurate.
Data dump for table `sbtest`.`sbtest1` will be written to 38 files
Data dump for table `sbtest`.`sbtest10` will be written to 38 files
Data dump for table `sbtest`.`sbtest3` will be written to 38 files
Data dump for table `sbtest`.`sbtest2` will be written to 38 files
Data dump for table `sbtest`.`sbtest4` will be written to 38 files
Data dump for table `sbtest`.`sbtest5` will be written to 38 files
Data dump for table `sbtest`.`sbtest6` will be written to 38 files
Data dump for table `sbtest`.`sbtest7` will be written to 38 files
Data dump for table `sbtest`.`sbtest8` will be written to 38 files
Data dump for table `sbtest`.`sbtest9` will be written to 38 files
2 thds dumping - 36% (17.74M rows / ~48.14M rows), 570.93K rows/s, 111.78 MB/s uncompressed, 50.32 MB/s compressed
1 thds dumping - 100% (50.00M rows / ~48.14M rows), 587.61K rows/s, 115.04 MB/s uncompressed, 51.79 MB/s compressed
Duration: 00:01:27s
Schemas dumped: 3
Tables dumped: 10
Uncompressed data size: 9.78 GB
Compressed data size: 4.41 GB
Compression ratio: 2.2
Rows written: 50000000
Bytes written: 4.41 GB
Average uncompressed throughput: 111.86 MB/s
Average compressed throughput: 50.44 MB/s Levou um total de 1 minuto e 27 segundos para fazer um dump de todo o banco de dados (os mesmos dados usados para mysqldump) e também mostra seu progresso, o que será realmente útil para saber quanto do backup foi concluído. Dá o tempo que levou para realizar o backup.
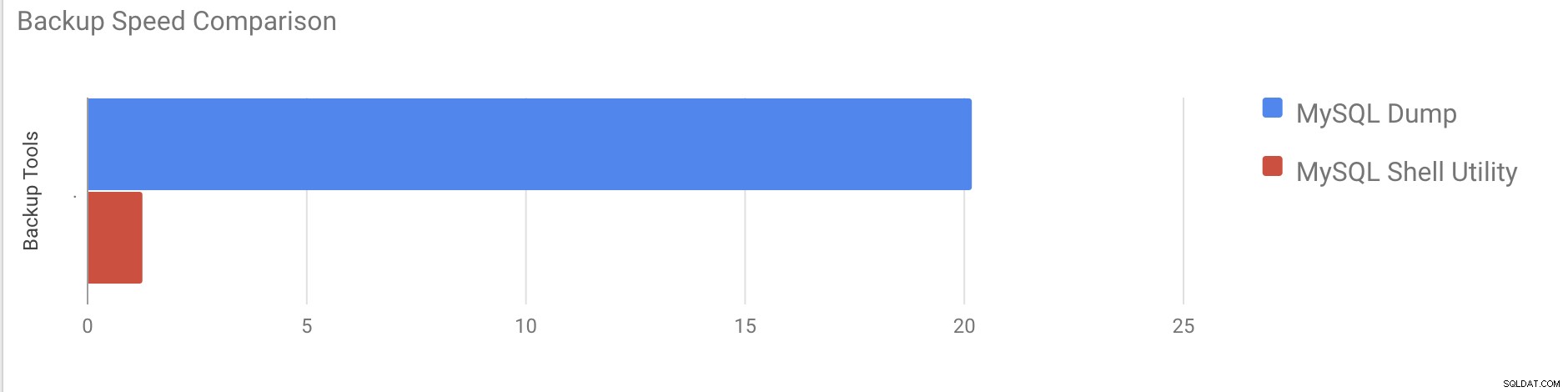
O paralelismo depende do número de núcleos no servidor. Aumentar aproximadamente o valor não será útil no meu caso. (Minha máquina tem 2 núcleos).
Teste de velocidade de restauração
Na parte de restauração, vamos restaurar o backup do mysqldump em outro servidor autônomo. O arquivo de backup já foi movido para o servidor de destino usando rsync.
Caso de teste 1
Exemplo
[example@sqldat.com vagrant]#time gunzip < /mnt/mysqldump_schemaanddata.sql.gz | mysql -u root -pDemorou cerca de 16 minutos e 26 segundos para restaurar os 10 GB de dados.
Caso de teste 2
Neste caso, estamos usando o utilitário shell mysql para carregar o arquivo de backup em outro host autônomo. Já movemos o arquivo de backup para o servidor de destino. Vamos iniciar o processo de restauração.
Exemplo
MySQL localhost:33060+ ssl JS > util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
Executing DDL script for schema `cluster_control`
Executing DDL script for schema `proxydemo`
Executing DDL script for schema `sbtest`
.
.
.
2 thds loading \ 1% (150.66 MB / 9.78 GB), 6.74 MB/s, 4 / 10 tables done
2 thds loading / 100% (9.79 GB / 9.79 GB), 1.29 MB/s, 10 / 10 tables done
[Worker001] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
[Worker002] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
Executing common postamble SQL
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 2 schemas were loaded in 40 min 6 sec (avg throughput 4.06 MB/s)Demorou cerca de 40 minutos e 6 segundos para restaurar os 10 GB de dados.
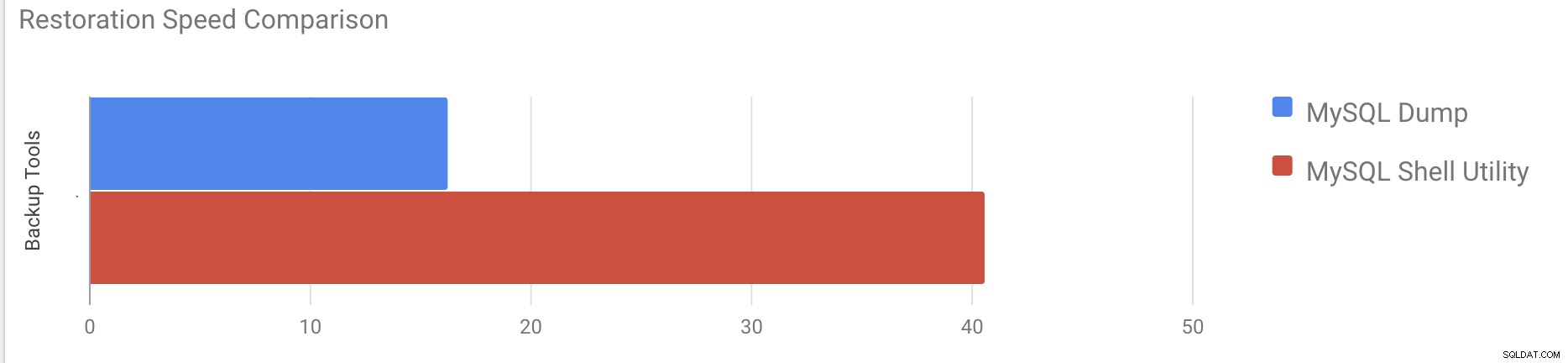
Agora vamos tentar desabilitar o redo log e iniciar a importação de dados usando mysql utilitário de concha.
mysql> alter instance disable innodb redo_log;
Query OK, 0 rows affected (0.00 sec)
MySQL localhost:33060+ ssl JS >util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
.
.
.
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 3 schemas were loaded in 19 min 56 sec (avg throughput 8.19 MB/s)
0 warnings were reported during the load.Após desabilitar o redo log, a taxa de transferência média foi aumentada em até 2x.
Observação:não desative o log de redo em um sistema de produção. Ele permite o desligamento e a reinicialização do servidor enquanto o redo logging está desabilitado, mas uma interrupção inesperada do servidor enquanto o redo logging está desabilitado pode causar perda de dados e corrupção de instância.
Backups físicos
Como você deve ter notado, os métodos lógicos de backup, mesmo se multithread, consomem bastante tempo, mesmo para um pequeno conjunto de dados com o qual os testamos. Esta é uma das razões pelas quais o ClusterControl fornece um método de backup físico baseado na cópia dos arquivos - nesse caso não estamos limitados pela camada SQL que processa o backup lógico, mas sim pelo hardware - a rapidez com que o disco pode ler os arquivos e quão rápido a rede pode transferir dados entre o nó do banco de dados e o servidor de backup.
ClusterControl vem com diferentes maneiras de implementar backups físicos, o método disponível dependerá do tipo de cluster e às vezes até do fornecedor. Vamos dar uma olhada no Xtrabackup executado pelo ClusterControl que irá criar um backup completo dos dados em nosso ambiente de teste.
Vamos criar um backup ad-hoc desta vez, mas o ClusterControl permite você também cria um agendamento de backup completo.
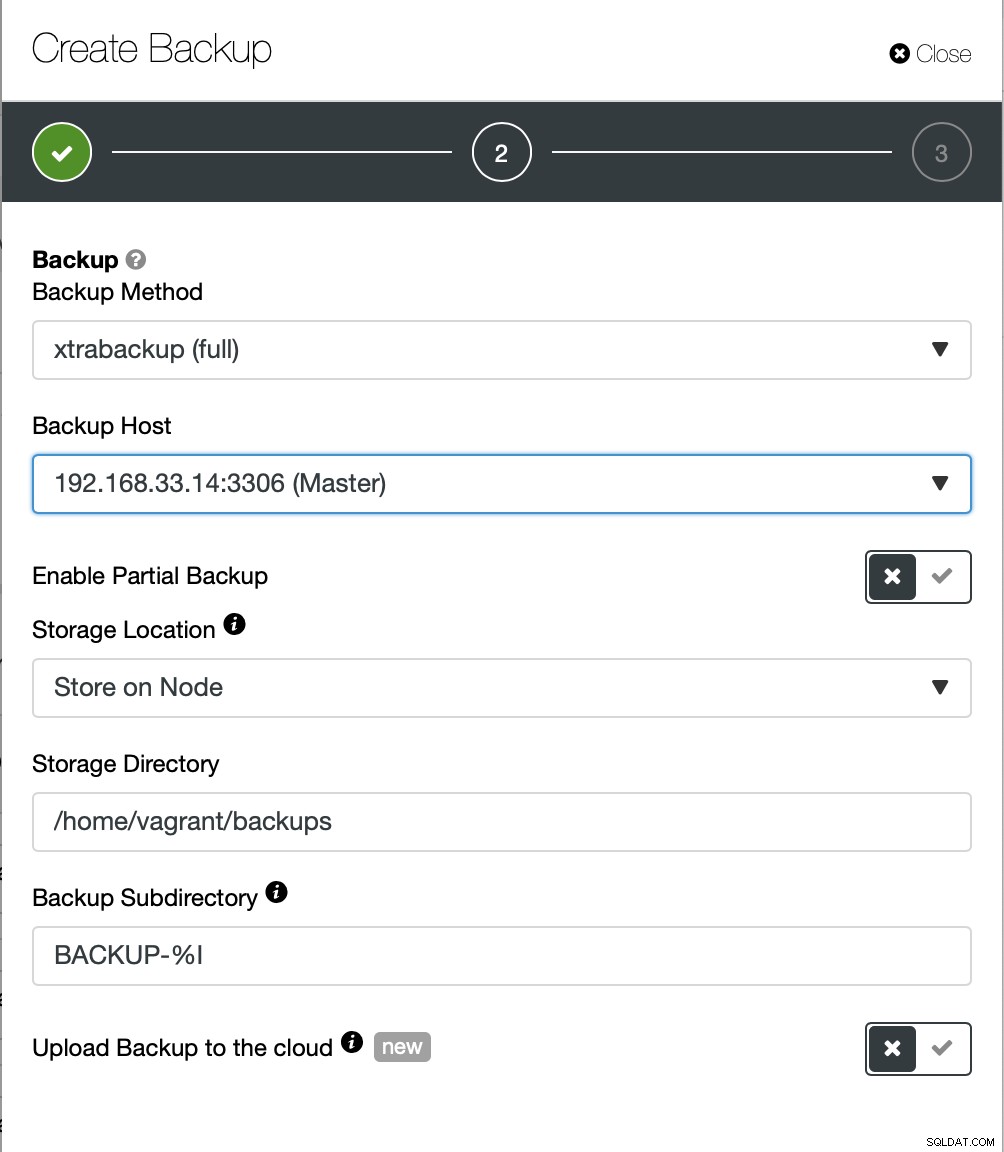
Aqui escolhemos o método de backup (xtrabackup), bem como o host que vão tirar o backup de. Também podemos armazená-lo localmente no nó ou pode ser transmitido para uma instância do ClusterControl. Além disso, você pode fazer upload do backup para a nuvem (AWS, Google Cloud e Azure são compatíveis).
O backup levou cerca de 10 minutos para ser concluído. Aqui os logs do arquivo cmon_backup.metadata.
[example@sqldat.com BACKUP-9]# cat cmon_backup.metadata
{
"class_name": "CmonBackupRecord",
"backup_host": "192.168.33.14",
"backup_tool_version": "2.4.21",
"compressed": true,
"created": "2020-11-17T23:37:15.000Z",
"created_by": "",
"db_vendor": "oracle",
"description": "",
"encrypted": false,
"encryption_md5": "",
"finished": "2020-11-17T23:47:47.681Z"
}Agora vamos tentar o mesmo para restaurar usando o ClusterControl. ClusterControl> Backup>
Restaurar Backup
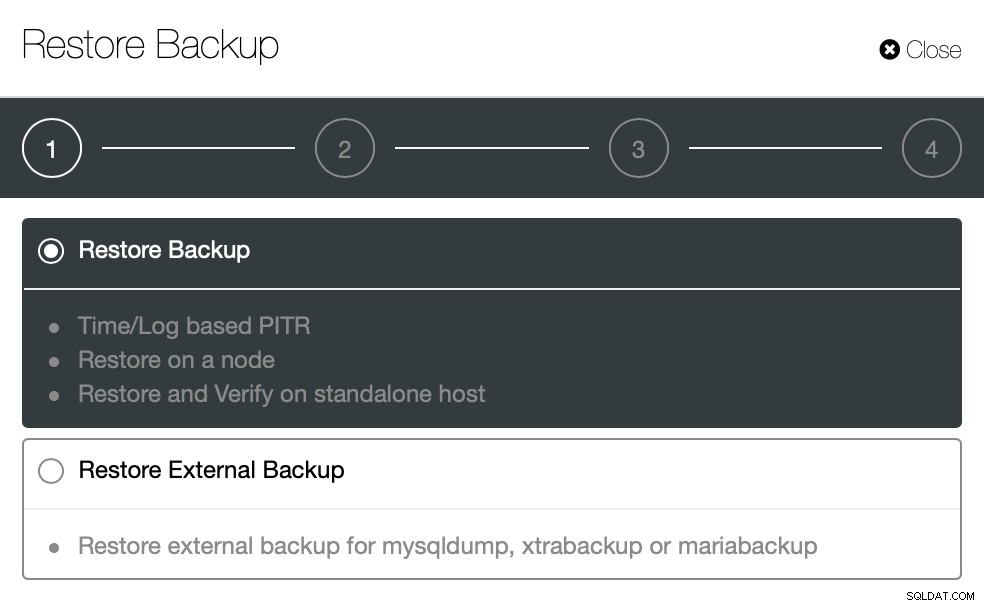
Aqui escolhemos a opção de backup de restauração, ela suportará tempo e log recuperação também.
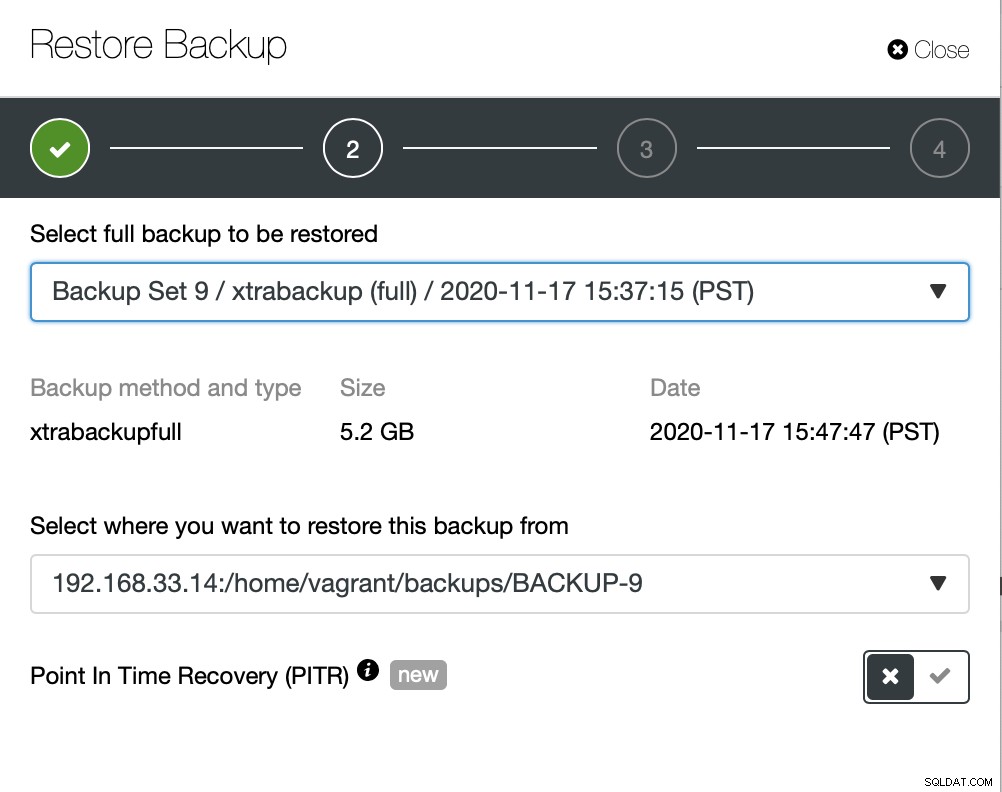
Aqui escolhemos o caminho de origem do arquivo de backup e depois o servidor de destino. Você também deve certificar-se de que esse host pode ser acessado a partir do nó ClusterControl usando SSH.
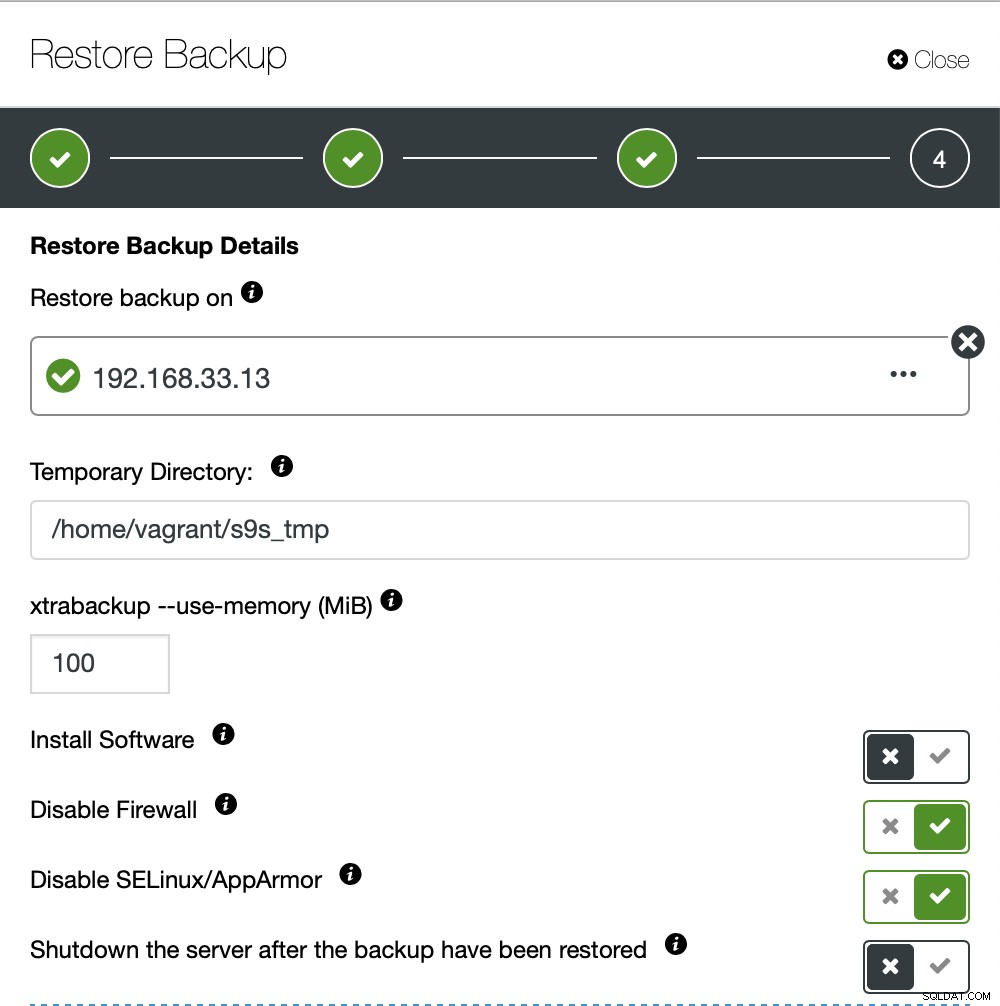
Não queremos que o ClusterControl configure o software, então desabilitamos essa opção. Após a restauração, ele manterá o servidor funcionando.
Demorou cerca de 4 minutos e 18 segundos para restaurar os 10 GB de dados. O Xtrabackup não bloqueia seu banco de dados durante o processo de backup. Para bancos de dados grandes (100+ GB), ele oferece um tempo de restauração muito melhor em comparação com o utilitário mysqldump/shell. Além disso, o lusterControl suporta backup e restauração parciais, como um dos meus colegas explicou em seu blog:Backup e restauração parcial.
Conclusão
Cada método tem seus prós e contras. Como vimos, não existe um método que funcione melhor para tudo o que você precisa fazer. Precisamos escolher nossa ferramenta com base em nosso ambiente de produção e tempo de destino para recuperação.