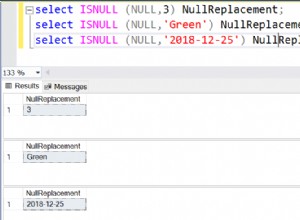
Eu acredito que isso fará isso, usando a chave duplicada + ifnull():
create table tmp like yourtable;
alter table tmp add unique (text1, text2);
insert into tmp select * from yourtable
on duplicate key update text3=ifnull(text3, values(text3));
rename table yourtable to deleteme, tmp to yourtable;
drop table deleteme;
Deve ser muito mais rápido do que qualquer coisa que exija group by ou distinct ou uma subconsulta, ou mesmo ordenar por. Isso nem requer um filesort, que vai matar o desempenho em uma grande tabela temporária. Ainda exigirá uma varredura completa sobre a mesa original, mas não há como evitar isso.