O gerenciamento do desempenho do banco de dados é uma área para a qual as empresas, quando os administradores, geralmente contribuem com mais tempo do que esperavam.
Monitorar e reagir aos problemas de desempenho do banco de dados de produção é uma das tarefas mais críticas em um trabalho de administrador de banco de dados. É um processo contínuo que requer cuidados constantes. Os bancos de dados de aplicativos e subjacentes geralmente evoluem com o tempo; crescer em tamanho, número de usuários, carga de trabalho, alterações de esquema que acompanham as alterações de código.
Consultas de longa duração raramente são inevitáveis em um banco de dados MySQL. Em algumas circunstâncias, uma consulta de longa duração pode ser um evento prejudicial. Se você se preocupa com seu banco de dados, a otimização do desempenho da consulta e a detecção de consultas de longa duração devem ser realizadas regularmente.
Neste blog, vamos dar uma olhada mais detalhada na carga de trabalho real do banco de dados, especialmente no lado das consultas em execução. Vamos verificar como rastrear consultas, que tipo de informação podemos encontrar nos metadados do MySQL, quais ferramentas usar para analisar tais consultas.
Lidando com as consultas de longa duração
Vamos começar verificando as consultas de longa duração. Em primeiro lugar, temos que conhecer a natureza da consulta, se espera-se que seja uma consulta de longa ou curta execução. Algumas operações analíticas e em lote devem ser consultas de longa duração, portanto, podemos ignorá-las por enquanto. Além disso, dependendo do tamanho da tabela, modificar a estrutura da tabela com o comando ALTER pode ser uma operação de longa duração (especialmente em MySQL Galera Clusters).
- Bloqueio de tabela - A tabela é bloqueada por um bloqueio global ou bloqueio de tabela explícito quando a consulta está tentando acessá-la.
- Consulta ineficiente - Use colunas não indexadas durante a pesquisa ou junção, portanto, o MySQL leva mais tempo para corresponder à condição.
- Deadlock - Uma consulta está aguardando para acessar as mesmas linhas bloqueadas por outra solicitação.
- O conjunto de dados não cabe na RAM - Se os dados do conjunto de trabalho caberem nesse cache, as consultas SELECT geralmente serão relativamente rápidas.
- Recursos de hardware abaixo do ideal - Isso pode ser discos lentos, reconstrução de RAID, rede saturada etc.
Se você perceber que uma consulta demora mais do que o normal para ser executada, investigue-a.
Usando a lista de processos de exibição do MySQL
MYSQL> SHOW PROCESSLIST;Esta é geralmente a primeira coisa que você executa no caso de problemas de desempenho. SHOW PROCESSLIST é um comando interno do mysql que mostra quais threads estão sendo executadas. Você também pode ver essas informações na tabela information_schema.PROCESSLIST ou no comando mysqladmin process list. Se você tiver o privilégio PROCESS, poderá ver todos os encadeamentos. Você pode ver informações como Query Id, tempo de execução, quem a executa, o host do cliente, etc. As informações com um pouco de cautela dependendo do sabor e distribuição do MySQL (Oracle, MariaDB, Percona)
SHOW PROCESSLIST;
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+
| Id | User | Host | db | Command | Time | State | Info | Progress |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+
| 2 | event_scheduler | localhost | NULL | Daemon | 2693 | Waiting on empty queue | NULL | 0.000 |
| 4 | root | localhost | NULL | Query | 0 | Table lock | SHOW PROCESSLIST | 0.000 |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+podemos ver imediatamente a consulta ofensiva logo na saída. No exemplo acima, isso poderia ser um bloqueio de tabela. Mas com que frequência olhamos para esses processos? Isso só é útil se você estiver ciente da transação de longa duração. Caso contrário, você não saberá até que algo aconteça - como as conexões estão se acumulando ou o servidor está ficando mais lento do que o normal.
Usando MySQL Pt-query-digest
Se você quiser ver mais informações sobre uma carga de trabalho específica, use pt-query-digest. O pt-query-digest é uma ferramenta Linux da Percona para analisar consultas do MySQL. Faz parte do Percona Toolkit que você pode encontrar aqui. Ele suporta as distribuições Linux de 64 bits mais populares, como Debian, Ubuntu e Redhat.
Para instalá-lo você deve configurar os repositórios Percona e então instalar o pacote perona-toolkit.
Instale o Percona Toolkit usando seu gerenciador de pacotes:
Debian ou Ubuntu:
sudo apt-get install percona-toolkitRHEL ou CentOS:
sudo yum install percona-toolkitPt-query-digest aceita dados da lista de processos, log geral, log binário, log lento ou tcpdump Além disso, é possível pesquisar a lista de processos do MySQL em um intervalo definido - um processo que pode ser intensivo em recursos e longe do ideal, mas ainda pode ser usado como uma alternativa.
A fonte mais comum para pt-query-digest é um log de consulta lento. Você pode controlar quantos dados irão para lá com o parâmetro log_slow_verbosity.
Há várias coisas que podem fazer com que uma consulta demore mais para ser executada:
- microtime - consultas com precisão de microssegundos.
- query_plan - informações sobre o plano de execução da consulta.
- innodb - estatísticas do InnoDB.
- mínimo - Equivalente a ativar apenas o microtempo.
- padrão - Equivalente a habilitar microtime,innodb.
- completo - Equivalente a todos os outros valores OU juntos sem as opções de criação de perfil e profiling_use_getrusage.
- criação de perfil - permite a criação de perfil de todas as consultas em todas as conexões.
- profiling_use_getrusage - Ativa o uso da função getrusage.
fonte:documentação do Percona
Para completar, use log_slow_verbosity=full, que é um caso comum.
Registro de consulta lenta
O log de consultas lentas pode ser usado para localizar consultas que levam muito tempo para serem executadas e, portanto, são candidatas à otimização. O log de consultas lentas captura consultas lentas (instruções SQL que levam mais de long_query_time segundos para serem executadas) ou consultas que não usam índices para pesquisas (log_queries_not_using_indexes). Este recurso não está habilitado por padrão e para habilitá-lo basta configurar as seguintes linhas e reiniciar o servidor MySQL:
[mysqld]
slow_query_log=1
log_queries_not_using_indexes=1
long_query_time=0.1O log de consultas lentas pode ser usado para localizar consultas que levam muito tempo para serem executadas e, portanto, são candidatas à otimização. No entanto, examinar um log de consulta longo e lento pode ser uma tarefa demorada. Existem ferramentas para analisar arquivos de log de consultas lentas do MySQL e resumir seu conteúdo como mysqldumpslow, pt-query-digest.
Esquema de desempenho
Performance Schema é uma ótima ferramenta disponível para monitoramento interno do MySQL Server e detalhes de execução em um nível inferior. Ele tinha uma má reputação em uma versão inicial (5.6) porque ativá-lo muitas vezes causava problemas de desempenho, no entanto, as versões recentes não prejudicam o desempenho. As seguintes tabelas no Performance Schema podem ser usadas para localizar consultas lentas:
- events_statements_current
- eventos_statements_history
- eventos_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
O MySQL 5.7.7 e superior incluem o esquema sys, um conjunto de objetos que ajuda DBAs e desenvolvedores a interpretar os dados coletados pelo Performance Schema em uma forma mais fácil de entender. Os objetos de esquema Sys podem ser usados para casos de uso típicos de ajuste e diagnóstico.
Rastreamento de rede
E se não tivermos acesso ao log de consulta ou aos logs diretos do aplicativo. Nesse caso, poderíamos usar uma combinação de tcpdump e pt-query digest que poderia ajudar a capturar consultas.
$ tcpdump -s 65535 -x -nn -q -tttt -i any port 3306 > mysql.tcp.txtQuando o processo de captura terminar, podemos prosseguir com o processamento dos dados:
$ pt-query-digest --limit=100% --type tcpdump mysql.tcp.txt > ptqd_tcp.outMonitor de consulta de controle de cluster
ClusterControl Query Monitor é um módulo em um controle de cluster que fornece informações combinadas sobre a atividade do banco de dados. Ele pode coletar informações de várias fontes, como lista de processos de exibição ou log de consultas lentas, e apresentá-las de maneira pré-agregada.
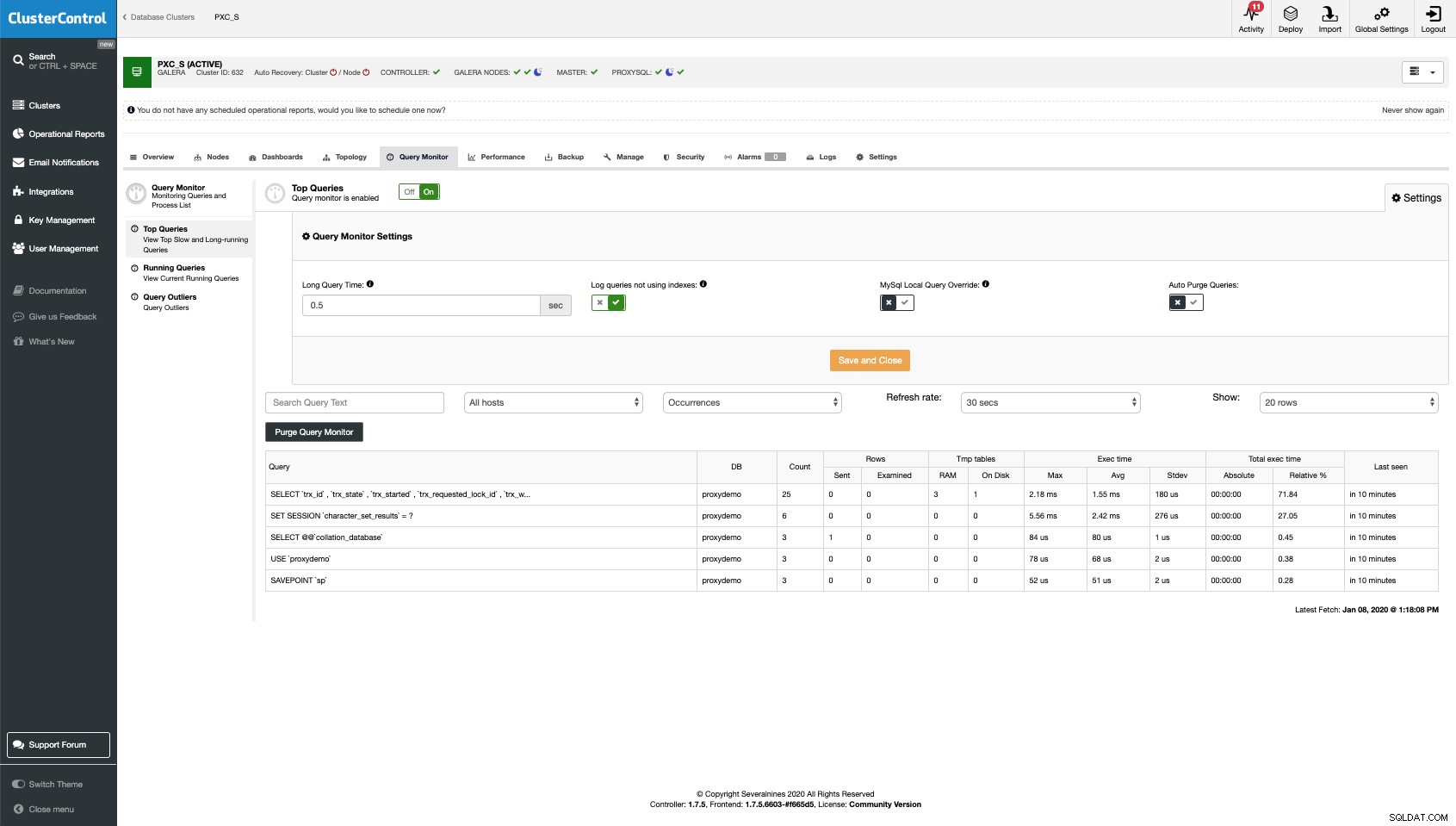
O monitoramento de SQL é dividido em três seções.
Principais consultas
apresenta as informações sobre consultas que consomem uma parte significativa dos recursos.
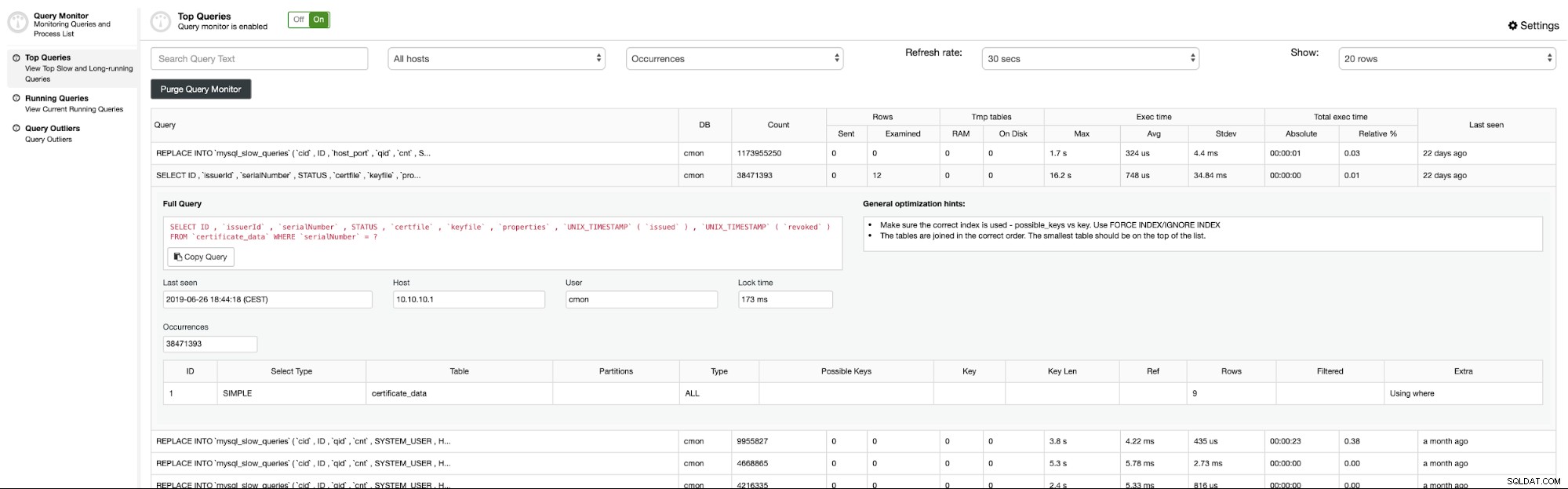
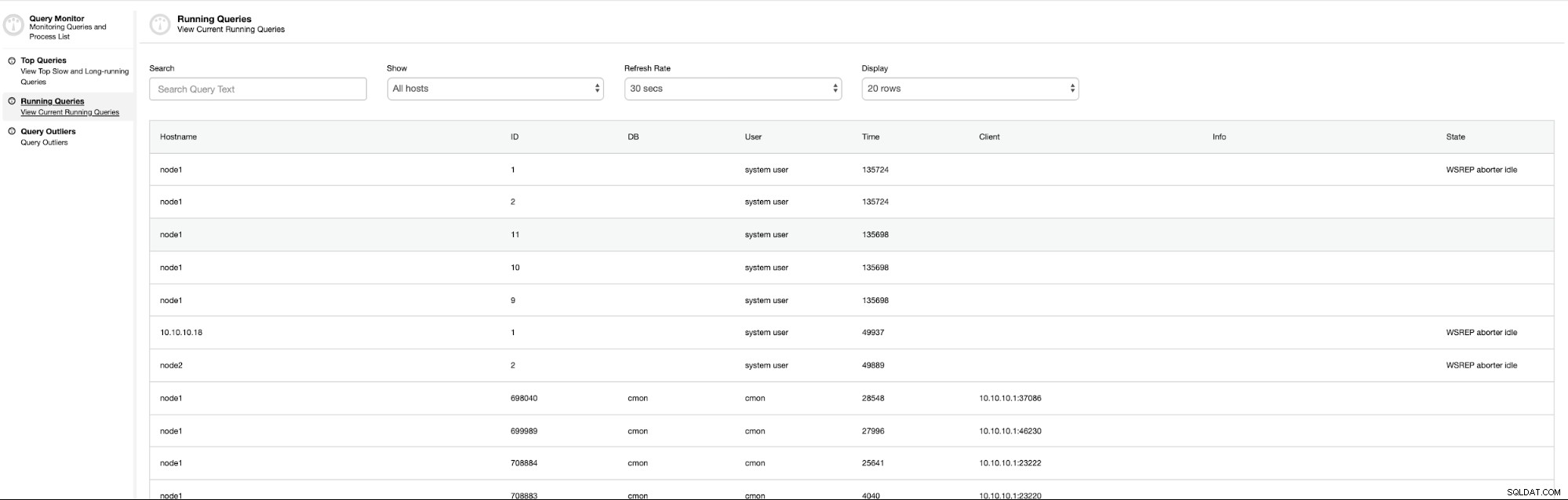
Executando consultas
é uma lista de processos de informações combinadas de todos os nós do cluster de banco de dados em uma visualização. Você pode usar isso para eliminar consultas que afetam suas operações de banco de dados.
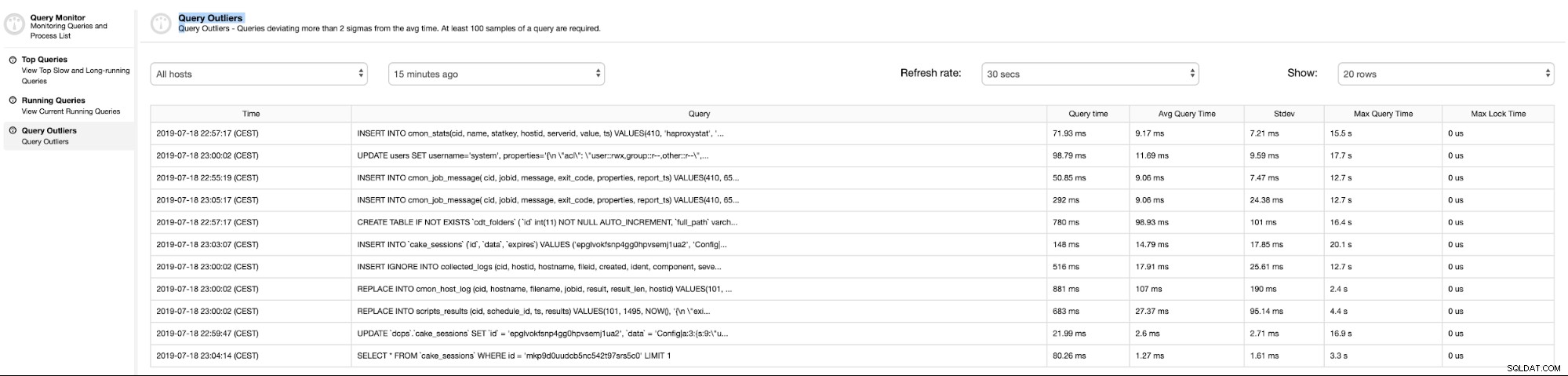
Consultas atípicas
apresenta a lista de consultas com tempo de execução maior que a média.
Conclusão
Isso é tudo para a parte dois. Este blog não pretende ser um guia exaustivo sobre como melhorar o desempenho do banco de dados, mas esperamos que dê uma visão mais clara de quais coisas podem se tornar essenciais e alguns dos parâmetros básicos que podem ser configurados. Não hesite em nos informar se perdemos algum importante nos comentários abaixo.



