Como as tabelas MySQL são corrompidas? Há muitas maneiras de estragar arquivos de dados. Muitas vezes, a corrupção é devido a defeitos na plataforma subjacente, na qual o MySQL depende para armazenar e recuperar dados - subsistema de disco, controladores, canais de comunicação, drivers, firmware ou outras falhas de hardware. A corrupção de dados também pode ocorrer se o daemon do servidor MySQL reiniciar repentinamente ou se o servidor for reinicializado devido a uma falha de outros componentes do sistema operacional. Se a instância do banco de dados estiver no meio da gravação de dados no disco, ela poderá gravar os dados parcialmente, o que pode resultar em uma soma de verificação de página diferente do esperado. Também houve bugs no MySQL, portanto, mesmo que o hardware do servidor esteja ok, o próprio MySQL pode causar corrupção.
Normalmente, quando os dados do MySQL são corrompidos, a recomendação é restaurá-los a partir do último backup, alternar para o servidor DR ou derrubar o nó afetado se você tiver o cluster Galera para fornecer dados imediatamente de outros nós. Em alguns casos, você não pode - se o backup não estiver lá, o cluster nunca foi configurado, sua replicação está inativa por muito tempo ou o procedimento de recuperação de desastres nunca foi testado. Mesmo se você tiver um backup, você ainda pode querer realizar algumas ações para tentar a recuperação, pois pode levar menos tempo para voltar a ficar online.
MyISAM, o mau e o feio
O InnoDB é mais tolerante a falhas do que o MyISAM. O InnoDB possui recursos de auto_recovery e é muito mais seguro em comparação com o mecanismo MyISAM mais antigo.
As tabelas MyISAM podem ser facilmente corrompidas quando ocorrem muitas gravações e muitos bloqueios nessa tabela. O mecanismo de armazenamento "grava" dados no cache do sistema de arquivos, o que pode levar algum tempo antes de ser liberado para o disco. Portanto, se o servidor reiniciar repentinamente, uma quantidade desconhecida de dados no cache será perdida. Essa é uma maneira comum para os dados do MyISAM serem corrompidos. A recomendação é migrar do MyISAM para o InnoDB, mas pode haver casos em que isso não seja possível.
Primum non nocere, o backup
Antes de tentar reparar tabelas corrompidas, você deve fazer backup dos arquivos do banco de dados primeiro. Sim, já está quebrado, mas isso é para minimizar o risco de possíveis danos adicionais que podem ser causados por uma operação de recuperação. Não há garantia de que qualquer ação que você tomar não prejudicará os blocos de dados intocados. Forçar a recuperação do InnoDB com valores maiores que 4 pode corromper os arquivos de dados, portanto, certifique-se de fazer isso com backup prévio e, idealmente, em uma cópia física separada do banco de dados.
Para fazer backup de todos os arquivos de todos os bancos de dados, siga estas etapas:
Pare o servidor MySQL
service mysqld stopDigite o seguinte comando para seu datadir.
cp -r /var/lib/mysql /var/lib/mysql_bkpDepois de ter uma cópia de backup do diretório de dados, estamos prontos para iniciar a solução de problemas.
Identificação de corrupção de dados
O log de erros é seu melhor amigo. Normalmente, quando ocorre corrupção de dados, você encontrará informações relevantes (incluindo links para documentação) no log de erros. Se você não sabe onde está localizado, verifique my.cnf e a variável log_error, para mais detalhes consulte este artigo https://dev.mysql.com/doc/refman/8.0/en/error-log-destination-configuration. html. O que você também deve saber é o tipo de mecanismo de armazenamento. Você pode encontrar essas informações no log de erros ou em information_schema.
mysql> select table_name,engine from information_schema.tables where table_name = '<TABLE>' and table_schema = '<DATABASE>';As principais ferramentas/comandos para diagnosticar problemas com corrupção de dados são CHECK TABLE, REPAIR TABLE e myisamchk. O cliente mysqlcheck realiza manutenção de tabelas:Verifica, repara (MyISAM), otimiza ou analisa tabelas enquanto o MySQL está rodando.
mysqlcheck -uroot -p <DATABASE>Substitua DATABASE pelo nome do banco de dados e substitua TABLE pelo nome da tabela que você deseja verificar:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck verifica o banco de dados e tabelas especificados. Se uma tabela passar na verificação, mysqlcheck exibirá OK para a tabela.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKProblemas de corrupção de dados também podem estar relacionados a problemas de permissão. Em alguns casos, o SO pode alternar o ponto de montagem para o modo somente leitura devido a problemas de R/W ou isso pode ser causado por um usuário que acidentalmente alterou a propriedade dos arquivos de dados. Nesses casos, você encontrará informações relevantes no log de erros.
[example@sqldat.com employees]# ls -rtla
...
-rw-rw----. 1 mysql mysql 28311552 05-10 06:24 titles.ibd
-rw-r-----. 1 root root 109051904 05-10 07:09 salaries.ibd
drwxr-xr-x. 7 mysql mysql 4096 05-10 07:12 ..
drwx------. 2 mysql mysql 4096 05-10 07:17 .Cliente MySQL
MariaDB [employees]> select count(*) from salaries;
ERROR 1932 (42S02): Table 'employees.salaries' doesn't exist in engineErro na entrada do log
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Failed to find tablespace for table `employees`.`salaries` in the cache. Attempting to load the tablespace with space id 9
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Cannot open datafile for read-only: './employees/salaries.ibd' OS error: 81
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Could not find a valid tablespace file for `employees/salaries`. Please refer to https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting-datadict.html for how to resolve the issue.Recuperando a tabela InnoDB
Se você estiver usando o mecanismo de armazenamento InnoDB para uma tabela de banco de dados, poderá executar o processo de recuperação do InnoDB.
Para habilitar a recuperação automática, o MySQL precisa que a opção innodb_force_recovery esteja habilitada. Innodb_force_recovery força o InnoDB a inicializar enquanto impede a execução de operações em segundo plano, para que você possa despejar suas tabelas.
Para fazer isso, abra my.cnf e adicione a seguinte linha à seção [mysqld]:
[mysqld]
innodb_force_recovery=1
service mysql restartVocê deve iniciar em innodb_force_recovery=1, salvar as alterações no arquivo my.cnf e, em seguida, reiniciar o servidor MySQL usando o comando apropriado para seu sistema operacional. Se você conseguir despejar suas tabelas com um valor innodb_force_recovery de 3 ou menos, então você está relativamente seguro. Em muitos casos você terá que ir até 4 e como você já sabe isso pode corromper os dados.
[mysqld]
innodb_force_recovery=1
service mysql restartSe necessário mude para o valor mais alto, seis é o máximo e o mais perigoso.
Assim que você conseguir iniciar seu banco de dados, digite o seguinte comando para exportar todos os bancos de dados para o arquivo databases.sql:
mysqldump --all-databases --add-drop-database --add-drop-table > dump.sqlInicie o mysql e tente descartar o banco de dados ou bancos de dados afetados usando o comando DROP DATABASE. Se o MySQL não conseguir descartar um banco de dados, você poderá excluí-lo manualmente usando as etapas abaixo após interromper o servidor MySQL.
service mysqld stopSe você não conseguiu eliminar um banco de dados, digite os comandos a seguir para excluí-lo manualmente.
cd /var/lib/mysql
rm -rf <DATABASE>Certifique-se de não excluir os diretórios internos do banco de dados.
Depois de terminar, comente a seguinte linha no [mysqld] para desabilitar o modo de recuperação do InnoDB.
#innodb_force_recovery=...Salve as alterações no arquivo my.cnf e inicie o servidor MySQL
service mysqld startDigite o seguinte comando para restaurar os bancos de dados do arquivo de backup que você criou na etapa 5:
mysql> tee import_database.log
mysql> source dump.sqlReparando o MyISAM
Se o mysqlcheck relatar um erro para uma tabela, digite o comando mysqlcheck com o sinalizador -repair para corrigi-lo. A opção de reparo do mysqlcheck funciona enquanto o servidor está funcionando.
mysqlcheck -uroot -p -r <DATABASE> <TABLE>Se o servidor estiver inativo e por qualquer motivo o mysqlcheck não puder reparar sua tabela, você ainda terá a opção de executar a recuperação diretamente nos arquivos usando o myisamchk. Com myisamchk, você precisa ter certeza de que o servidor não tem as mesas abertas.
Pare o MySQL
service mysqld stop
cd /var/lib/mysqlMude para o diretório onde o banco de dados está localizado.
cd /var/lib/mysql/employees
myisamchk <TABLE>Para verificar todas as tabelas em um banco de dados, digite o seguinte comando:
myisamchk *.MYISe o comando anterior não funcionar, você pode tentar excluir os arquivos temporários que podem estar impedindo que o myisamchk seja executado corretamente. Para fazer isso, volte para o diretório dir de dados e execute o seguinte comando:
ls */*.TMDSe houver algum arquivo .TMD listado, exclua-o:
rm */*.TMDEm seguida, execute novamente o myisamchk.
Para tentar reparar uma tabela, execute o seguinte comando, substituindo TABLE pelo nome da tabela que você deseja reparar:
myisamchk --recover <TABLE>Reinicie o servidor MySQL
service mysqld startComo evitar a perda de dados
Há várias coisas que você pode fazer para minimizar o risco de dados irrecuperáveis. Primeiro de todos os backups. O problema com os backups é que às vezes eles podem passar despercebidos. Para backups agendados cron, geralmente escrevemos scripts wrapper que detectam problemas no log de backup, mas isso não inclui casos em que o backup não foi iniciado. O Cron às vezes pode travar e muitas vezes não há monitoramento definido nele. Outro problema potencial pode ser o caso em que o backup nunca foi configurado. A boa prática é executar relatórios de uma ferramenta separada que analisará o status do backup e informará sobre agendamentos de backups ausentes. Você pode usar o ClusterControl para isso ou escrever seus próprios programas.
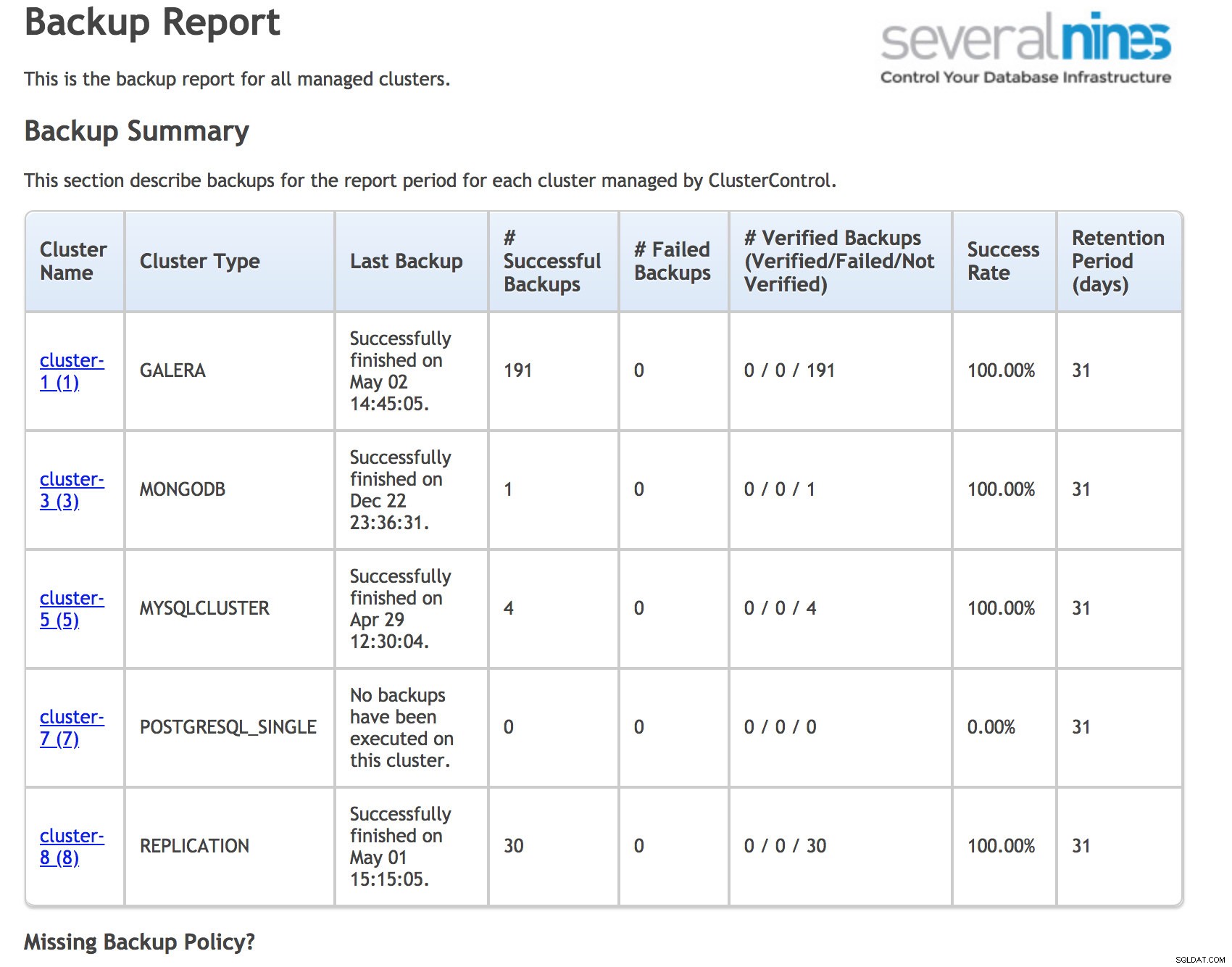 Relatório de backup operacional do ClusterControl
Relatório de backup operacional do ClusterControl Para reduzir o impacto da possível corrupção de dados, você deve sempre considerar sistemas em cluster. É apenas uma questão de tempo até que o banco de dados falhe ou seja corrompido, por isso é bom ter uma cópia para a qual você possa alternar. Pode ser replicação mestre/escravo. O aspecto importante aqui é ter uma recuperação automática segura para minimizar a complexidade do switchover e minimizar o tempo de recuperação (RTO).
 Recursos de recuperação automática do ClusterControl
Recursos de recuperação automática do ClusterControl 


