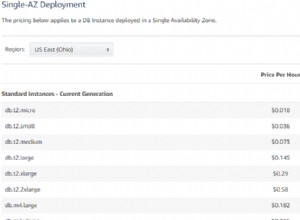
Conceitos
Você entendeu mal alguns conceitos básicos, e as dificuldades resultam disso. Temos que abordar os conceitos primeiro, não o problema como você o percebe e, consequentemente, seu problema desaparecerá.
IDs incrementados automaticamente, que obviamente são chaves primárias.
Não, eles não são. Esse é um equívoco comum. E os problemas são garantidos.
Um
ID campo não pode ser uma Chave Primária no sentido Inglês ou técnico ou Relacional. -
Claro, no SQL, você pode declarar qualquer campo seja umaPRIMARY KEY, mas isso não a transforma magicamente em uma chave primária nos sentidos inglês, técnico ou relacional. Você pode nomear um chihuahua "Rottweiller", mas isso não o transforma em um Rottweiller, ele continua sendo um chihuahua. Como qualquer linguagem, o SQL simplesmente executa os comandos que você dá, ele não entendePRIMARY KEYpara significar algo Relacional, apenas atinge um índice exclusivo na coluna (ou campo).
-
O problema é que você declarou oIDpara ser umaPRIMARY KEY, você pensa dele como uma chave primária, e você pode esperar que tem algumas das qualidades de uma Chave Primária. Exceto pela exclusividade do ID valor , não oferece nenhum benefício. Não tem nenhuma das qualidades de uma Chave Primária, ou qualquer tipo de Chave Relacional. Não é uma chave nos sentidos inglês, técnico ou relacional. Ao declarar uma não-chave como chave, você apenas se confundirá e descobrirá que há algo terrivelmente errado somente quando o usuário reclamar de duplicatas na tabela.
As tabelas relacionais devem ter linha exclusividade
Uma
PRIMARY KEY em um ID campo não fornece linha singularidade. Portanto, não é uma tabela relacional contendo linhas, e se não for isso, então é um arquivo contendo registros. Ele não tem nenhuma integridade, ou poder (neste estágio, você estará ciente apenas do poder de junção), ou velocidade, que uma tabela em um banco de dados relacional tem. Execute este código (MS SQL 2008) e prove a si mesmo. Por favor, não simplesmente leia isto e entenda, e então continue a ler o resto desta Resposta, este código deve ser executado antes de continuar lendo . Tem valor curativo.
CREATE TABLE dumb_file (
id INT NOT NULL IDENTITY PRIMARY KEY,
name_first CHAR(30) NOT NULL,
name_last CHAR(30) NOT NULL
)
INSERT dumb_file VALUES ( "Mickey", "Mouse" ) -- succeeds
INSERT dumb_file VALUES ( "Mickey", "Mouse" ) -- succeeds, but not intended
INSERT dumb_file VALUES ( "Mickey", "Mouse" ) -- succeeds, but not intended
SELECT * FROM dumb_file
Observe que você tem linhas duplicadas . As tabelas relacionais precisam ter linhas exclusivas . Mais uma prova de que você não tem uma tabela relacional, ou qualquer uma das qualidades de uma.
Observe que em seu relatório, a única coisa que é única é o
ID campo, que nenhum usuário se importa, nenhum usuário vê, porque não são dados, é algum absurdo adicional que algum "professor" muito estúpido disse para você colocar em todos os arquivos. Você tem registro exclusividade, mas não linha singularidade. Em termos de dados (os dados reais menos as adições estranhas), os dados
name_last e name_first pode existir sem o ID campo. Uma pessoa tem um nome e sobrenome sem um documento de identificação estampado na testa. A segunda coisa que você está usando que o confunde é o
AUTOINCREMENT. Se você estiver implementando um sistema de arquivamento de registros sem capacidade Relacional, claro, é útil, você não precisa codificar o incremento ao inserir registros. Mas se você estiver implementando um Banco de Dados Relacional, ele não serve para nada, porque você nunca o usará. Existem muitos recursos no SQL que a maioria das pessoas nunca usa. Ação Corretiva
Então, como você atualiza, eleva, esse dumb_file que está cheio de linhas duplicadas para uma tabela relacional, a fim de obter algumas das qualidades e benefícios de uma tabela relacional? Existem três etapas para isso.
-
Você precisa entender as chaves
- E como progredimos dos arquivos ISAM da década de 1970, para o Modelo Relacional , você precisa entender as Chaves Relacionais . Ou seja, se você deseja obter os benefícios (integridade, potência, velocidade) de um Banco de Dados Relacional.
Dr. E F Cood, em seu RM , declarou que:
uma chave é formada a partir dos dados
e
as linhas em uma tabela devem ser exclusivas
Sua "chave" não é composta de dados. É algum parasita adicional, sem dados, causado por você estar infectado com a doença de seu "professor". Reconheça-o como tal e permita-se a plena capacidade mental que Deus lhe deu (observe que não lhe peço que pense em termos isolados ou fragmentados ou abstratos, todos os elementos de um banco de dados devem estar integrados uns aos outros). Crie uma chave real a partir dos dados, e somente a partir dos dados. Neste caso, há apenas uma chave possível:(name_last, name_first).
-
Experimente este código , declarar uma restrição exclusiva nos dados:
CREATE TABLE dumb_table ( id INT NOT NULL IDENTITY PRIMARY KEY, name_first CHAR(30) NOT NULL, name_last CHAR(30) NOT NULL CONSTRAINT UK UNIQUE ( name_last, name_first ) ) INSERT dumb_table VALUES ( "Mickey", "Mouse" ) -- succeeds INSERT dumb_table VALUES ( "Mickey", "Mouse" ) -- fails, as intended INSERT dumb_table VALUES ( "Minnie", "Mouse" ) -- succeeds SELECT * FROM dumb_table
Agora temos unicidade de linha . Essa é a sequência que acontece com a maioria das pessoas:elas criam um arquivo que permite dupes; eles não têm ideia de por que os trapaceiros estão aparecendo nas listas suspensas; o usuário grita; eles ajustam o arquivo e adicionam um índice para evitar enganos; eles vão para a próxima correção de bug. (Eles podem fazê-lo corretamente ou não, essa é uma história diferente.)
-
O segundo nível. Para pessoas pensantes que pensam além do fix-its. Como agora temos exclusividade de linha, qual é o propósito doIDcampo, por que ainda temos isso ??? Ah, porque o chihuahua se chama Rotty e temos medo de tocá-lo.
A declaração de que é umaPRIMARY KEYé falso, mas permanece, causando confusão e falsas expectativas. A única chave genuína que existe é a(name_last, name_fist),e é uma chave alternativa neste ponto.
Portanto, oIDcampo é totalmente supérfluo; e assim é o índice que o suporta; e também o estúpidoAUTOINCREMENT; e assim é a declaração falsa de que é umaPRIMARY KEY; e quaisquer expectativas que você possa ter sobre isso são falsas.
Portanto, remova oIDsupérfluo campo. Experimente este código :
CREATE TABLE honest_table ( name_first CHAR(30) NOT NULL, name_last CHAR(30) NOT NULL CONSTRAINT PK PRIMARY KEY ( name_last, name_first ) ) INSERT honest_table VALUES ( "Mickey", "Mouse" ) -- succeeds INSERT honest_table VALUES ( "Mickey", "Mouse" ) -- fails, as intended INSERT honest_table VALUES ( "Minnie", "Mouse" ) -- succeeds SELECT * FROM honest_table
Funciona muito bem, funciona como pretendido, sem os campos e índices estranhos.
Por favor, lembre-se disso e faça certo, todas as vezes.
Falsos professores
Nestes tempos finais, como aconselhamos, teremos muitos deles. Observe bem, os "professores" que propagam
ID colunas, em virtude das evidências detalhadas neste post, simplesmente não entendem o Modelo Relacional ou Bancos de Dados Relacionais. Especialmente aqueles que escrevem livros sobre isso. Como evidenciado, eles estão presos à tecnologia ISAM anterior a 1970. Isso é tudo que eles entendem, e isso é tudo que eles podem ensinar. Eles usam um contêiner de banco de dados SQL, para facilitar o acesso, recuperação, backup, etc, mas o conteúdo é puro sistema de arquivamento de registros sem integridade relacional, potência ou velocidade. AFAIC, é uma fraude grave.
Além de
ID campos, é claro, existem vários itens que são conceitos-chave Relacionais-ou-não, que juntos, me levam a formar uma conclusão tão grave. Esses outros itens estão além do escopo deste post. Um par particular de idiotas está atualmente montando um ataque à Primeira Forma Normal. Eles pertencem ao asilo.
Resposta
Agora para o resto da sua pergunta.
Existe uma maneira de criar uma tabela relacional sem perder os recursos de incremento automático?
Essa é uma frase autocontraditória. Espero que você entenda pela minha explicação, tabelas relacionais não precisam para
AUTOINCREMENT "recursos"; se o arquivo tiver AUTOINCREMENT , não é uma tabela relacional. AUTOINCREMENT é bom apenas para uma coisa:se, e somente se, você quiser criar uma planilha do Excel no contêiner do banco de dados SQL, repleta de campos chamados A, B, e C, na parte superior e registre os números no lado esquerdo. Em termos de banco de dados, esse é o resultado de um SELECT, uma visão nivelada dos dados, que não a fonte de dados, que é organizado (Normalizado).
Outra solução possível (mas não preferida) pode ser que haja outra chave primária na primeira tabela, que é o nome de usuário do usuário, não com uma instrução de incremento automático, é claro. É inevitável?
No trabalho técnico, não nos importamos com as preferências, porque isso é subjetivo e muda o tempo todo. Preocupamo-nos com a correção técnica, porque isso é objetivo e não muda.
Sim, é inevitável. Porque é apenas uma questão de tempo; número de erros; número de "não posso fazer"; número de gritos do usuário, até você encarar os fatos, superar suas falsas declarações e perceber que:
-
a única maneira de garantir que o usuário linhas são únicos, que os nomes de usuário são únicos, é declarar umUNIQUErestrição sobre isso
-
e livre-se deuser_idouidno arquivo do usuário
-
que promoveuser_nameparaPRIMARY KEY
Sim, porque todo o seu problema com a terceira mesa, não por coincidência, é então eliminado.
Essa terceira tabela é uma Tabela Associativa . A única Chave necessária (Chave Primária) é uma composição das duas Chaves Primárias pai. Isso garante a exclusividade das linhas , que são identificados por suas chaves, não por seus
IDs. Estou avisando sobre isso porque os mesmos "professores" que ensinaram a você o erro de implementar o
ID campos, ensine o erro de implementação de ID campos na Tabela Associativa, onde, assim como em uma tabela comum, é supérfluo, não serve para nada, apresenta duplicatas e causa confusão. E é duplamente supérfluo porque as duas chaves que fornecem já estão lá, nos encarando. Como eles não entendem o RM , ou termos relacionais, eles chamam de tabelas associativas "link" ou "map" tabelas. Se eles tiverem um
ID campo, eles são na verdade, arquivos. Tabelas de pesquisa
ID campos são particularmente Coisas estúpidas de se fazer para tabelas de pesquisa ou referência. A maioria deles possui códigos reconhecíveis, não há necessidade de enumerar a lista de códigos neles, pois os códigos são (devem ser) únicos. Além disso, ter os códigos nas tabelas filhas como FKs é uma coisa boa:o código é muito mais significativo e geralmente economiza uma junção desnecessária:
SELECT ...
FROM child_table -- not the lookup table
WHERE gender_code = "M" -- FK in the child, PK in the lookup
ao invés de:
SELECT ...
FROM child_table
WHERE gender_id = 6 -- meaningless to the maintainer
ou pior:
SELECT ...
FROM child_table C -- that you are trying to determine
JOIN lookup_table L
ON C.gender_id = L.gender_id
WHERE L.gender_code = "M" -- meaningful, known
Observe que isso é algo que não se pode evitar:você precisa de exclusividade no código de pesquisa e exclusividade na descrição. Esse é o único método para evitar duplicatas em cada das duas colunas:
CREATE TABLE gender (
gender_code CHAR(2) NOT NULL,
name CHAR(30) NOT NULL
CONSTRAINT PK
PRIMARY KEY ( gender_code )
CONSTRAINT AK
UNIQUE ( name )
)
Exemplo Completo
A partir dos detalhes da sua pergunta, suspeito que você tenha problemas de sintaxe SQL e definição de FK, então darei toda a solução necessária como exemplo (já que você não forneceu definições de arquivo):
CREATE TABLE user ( -- Typical Identifying Table
user_name CHAR(16) NOT NULL, -- Short PK
name_first CHAR(30) NOT NULL, -- Alt Key.1
name_last CHAR(30) NOT NULL, -- Alt Key.2
birth_date DATE NOT NULL -- Alt Key.3
CONSTRAINT PK -- unique user_name
PRIMARY KEY ( user_name )
CONSTRAINT AK -- unique person identification
PRIMARY KEY ( name_last, name_first, birth_date )
)
CREATE TABLE sport ( -- Typical Lookup Table
sport_code CHAR(4) NOT NULL, -- PK Short code
name CHAR(30) NOT NULL -- AK
CONSTRAINT PK
PRIMARY KEY ( sport_code )
CONSTRAINT AK
PRIMARY KEY ( name )
)
CREATE TABLE user_sport ( -- Typical Associative Table
user_name CHAR(16) NOT NULL, -- PK.1, FK
sport_code CHAR(4) NOT NULL, -- PK.2, FK
start_date DATE NOT NULL
CONSTRAINT PK
PRIMARY KEY ( user_name, sport_code )
CONSTRAINT user_plays_sport_fk
FOREIGN KEY ( user_name )
REFERENCES user ( user_name )
CONSTRAINT sport_occupies_user_fk
FOREIGN KEY ( sport_code )
REFERENCES sport ( sport_code )
)
Lá, a
PRIMARY KEY declaração é honesta, é uma Chave Primária; sem ID; não AUTOINCREMENT; sem índices extras; sem linhas duplicadas; sem expectativas errôneas; sem problemas consequentes. Modelo de dados
Aqui está o modelo de dados para acompanhar as definições.
-
Exemplo de modelo de dados de esporte do usuário>
-
Se você não está acostumado com a notação, esteja ciente de que cada pequeno tique, entalhe e marca, as linhas sólidas versus linhas tracejadas, os cantos quadrados versus redondos, significam algo muito específico. Consulte a Notação IDEF1X .
-
Uma imagem vale mais que mil palavras; neste caso, uma imagem de reclamação padrão vale mais do que isso; um ruim não vale o papel em que é desenhado.
-
Por favor, verifique cuidadosamente as Frases Verbais, elas compreendem um conjunto de Predicados. O restante dos Predicados pode ser determinado diretamente do modelo. Se não estiver claro, pergunte.