Se você conhece o
avg() função no SQLite, você provavelmente sabe que ela retorna a média de todos os valores não NULL X dentro de um grupo. Mas você sabia que pode adicionar o
DISTINCT palavra-chave para esta função? Se você adicionar o
DISTINCT palavra-chave, avg() calculará seus resultados com base apenas em valores distintos. Isso é essencialmente o mesmo que remover valores duplicados e calcular a média dos valores restantes. Sintaxe
Para usar o
DISTINCT palavra-chave, você simplesmente a insere como o primeiro argumento. Assim:
avg(DISTINCT X)Onde
X é o nome da coluna para a qual você está calculando a média. Exemplo
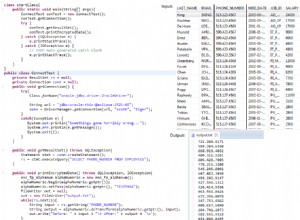
Pegue a seguinte tabela chamada
Products :ProductId ProductName Price ---------- ------------- ---------- 1 Widget Holder 139.5 2 Blue Widget 10.0 3 Red Widget 10.0 4 Green Widget 10.0 5 Widget Stick 89.75 6 Foo Cap 11.99
Se eu executar um
avg() normal na coluna Preço:SELECT avg(Price) FROM Products;Aqui está o que eu recebo:
45.2066666666667
Mas se eu executar um
DISTINCT inquerir:SELECT avg(DISTINCT Price) FROM Products;Eu entendi isso:
62.81
Então, neste caso, isso muda o resultado consideravelmente.
Só para ficar claro, aqui estão eles lado a lado:
SELECT
avg(Price) AS "Non-Distinct",
avg(DISTINCT Price) AS "Distinct"
FROM Products;Resultado:
Non-Distinct Distinct ---------------- ---------- 45.2066666666667 62.81
Como você provavelmente pode imaginar, usando o
DISTINCT palavra-chave com avg() pode distorcer enormemente os resultados, especialmente se houver muitas duplicatas em uma extremidade do intervalo, mas poucas duplicatas na outra extremidade.