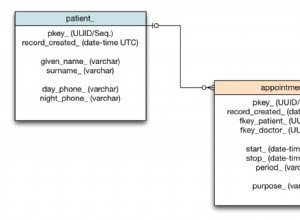
OK, então a lógica aqui pode ser resumida como:
- Encontre a série mais longa do mesmo dígito consecutivo em qualquer número; e
- Retorne true se o valor mais longo for> 5 dígitos
Certo?
Então, vamos dividi-lo em uma série de dígitos consecutivos:
regress=> SELECT regexp_matches('666666689', '(0+|1+|2+|3+|4+|5+|6+|7+|8+|9+)', 'g');
regexp_matches
----------------
{6666666}
{8}
{9}
(3 rows)
então filtre pelo mais longo:
regress=>
SELECT x[1]
FROM regexp_matches('6666666898', '(0+|1+|2+|3+|4+|5+|6+|7+|8+|9+)', 'g') x
ORDER BY length(x[1]) DESC
LIMIT 1;
x
---------
6666666
(1 row)
... mas, na verdade, não nos importamos com isso, apenas se alguma entrada tiver mais de 5 dígitos, então:
SELECT x[1]
FROM regexp_matches('6666666898', '(0+|1+|2+|3+|4+|5+|6+|7+|8+|9+)', 'g') x
WHERE length(x[1]) > 5;
pode ser usado como um
EXISTS teste, por exemplo WITH blah(n) AS (VALUES('999999969'),('000000089'),('666666689'),('15552555'))
SELECT n
FROM blah
WHERE EXISTS (
SELECT x[1]
FROM regexp_matches(n, '(0+|1+|2+|3+|4+|5+|6+|7+|8+|9+)', 'g') x
WHERE length(x[1]) > 5
)
que na verdade é bastante eficiente e retorna o resultado correto (sempre legal). Mas pode ser simplificado um pouco mais com:
WITH blah(n) AS (VALUES('999999969'),('000000089'),('666666689'),('15552555'))
SELECT n
FROM blah
WHERE EXISTS (
SELECT x[1]
FROM regexp_matches(n, '(0{6}|1{6}|2{6}|3{6}|4{6}|5{6}|6{6}|7{6}|8{6}|9{6})', 'g') x;
)
Você pode usar o mesmo
WHERE cláusula em um DELETE .