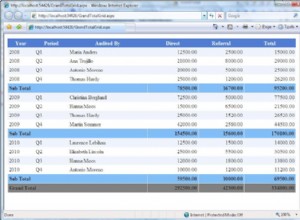
Faça NÃO use índices exceto para chave numérica única única.
Isso não se encaixa em todas as teorias de banco de dados que recebemos, mas testes com cargas pesadas de dados demonstram isso. Aqui está o resultado de 100 milhões de carregamentos de cada vez para atingir 2 bilhões de linhas em uma tabela e, a cada vez, várias consultas na tabela resultante. Primeiro gráfico com NAS de 10 gigabit (150 MB/s), segundo com 4 SSD em RAID 0 (R/W @ 2 GB/s).
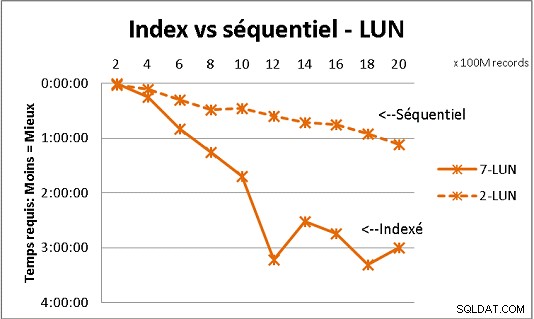
Se você tiver mais de 200 milhões de linhas em uma tabela em discos comuns, será mais rápido esquecer os índices. Nos SSDs, o limite é de 1 bilhão.
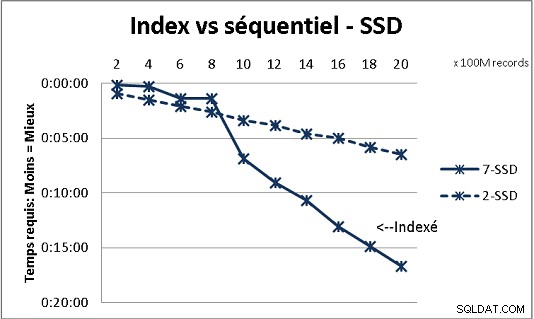
Eu fiz isso também com partições para obter melhores resultados, mas com o PG9.2 é difícil se beneficiar delas se você usar procedimentos armazenados. Você também tem que cuidar da escrita/leitura em apenas 1 partição de cada vez. No entanto, as partições são o caminho a seguir para manter suas tabelas abaixo da parede de 1 bilhão de linhas. Também ajuda muito para multiprocessar suas cargas. Com SSD, processo único permite inserir (copiar) 18.000 linhas/s (com algum trabalho de processamento incluído). Com multiprocessamento em 6 CPUs, cresce para 80.000 linhas/s.
Observe seu uso de CPU e E/S durante o teste para otimizar ambos.