lower()
/ upper()
Use um deles para dobrar os caracteres para letras minúsculas ou maiúsculas. Caracteres especiais não são afetados:
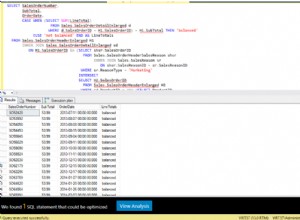
SELECT count(*), lower(name), number
FROM tbl
GROUP BY lower(name), number
HAVING count(*) > 1;
unaccent()
Se você realmente deseja ignorar sinais diacríticos, como seus comentários sugerem, instale o módulo adicional
sem acento
, que fornece um dicionário de pesquisa de texto que remove acentos e também a função de propósito geral unaccent() :CREATE EXTENSION unaccent;
Torna muito simples:
SELECT lower(unaccent('Büßercafé'));
Resultado:
busercafe
Isso não tira não-letras. Adicione
regexp_replace() como @Craig mencionou para isso:SELECT lower(unaccent(regexp_replace('$s^o&f!t Büßercafé', '\W', '', 'g') ));
Resultado:
softbusercafe
Você pode até construir um índice funcional em cima disso: