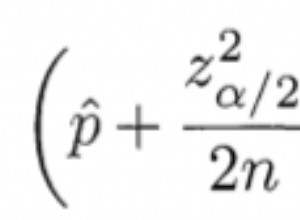Não sei se o Pg pode combinar um índice GiST e índices regulares de b-tree com uma varredura de índice de bitmap, mas suspeito que não. Você pode obter o melhor resultado possível sem adicionar um
user_id coluna ao seu índice GiST (e, consequentemente, tornando-o maior e mais lento para outras consultas que não usam user_id ). Como experimento, você pode:
CREATE EXTENSION btree_gist;
CREATE INDEX ix_coords_and_user_id ON test USING GIST (coords, user_id);
o que provavelmente resultará em um grande índice, mas pode aumentar essa consulta - se funcionar. Esteja ciente de que manter esse índice diminuirá significativamente o
INSERT e UPDATE s. Se você descartar o antigo ix_coords suas consultas usarão ix_coords_and_user_id mesmo que não filtrem em user_id , mas será mais lento que ix_coords . Manter ambos fará com que o INSERT e UPDATE desaceleração ainda pior. Consulte btree-gist
(Desatualizado por editar a pergunta que altera a pergunta completamente; quando escrito, o usuário tinha um índice de várias colunas, agora dividido em dois separados ):
Você não parece estar filtrando ou classificando em
user_id , apenas create_date . Pg não usará (não pode?) usar apenas o segundo termo de um índice de várias colunas como (user_id, create_date) , ele também precisa do primeiro item. Se você deseja indexar
create_date , crie um índice separado para ele. Se você usa e precisa do (user_id, create_date) index e geralmente não use apenas user_id sozinho, veja se consegue inverter a ordem das colunas. Como alternativa, crie dois índices independentes, (user_id) e (create_date) . Quando ambas as colunas são necessárias, o Pg pode combinar os dois índices independentes usando uma varredura de índice de bitmap.