Não consigo encontrar uma falha no seu design. Eu tentei.
Localidades e agrupamento
Retomei essa pergunta. Considere este caso de teste no sqlfiddle . Parece funcionar muito bem. Eu até criei a localidade
ca_ES.utf8 no meu servidor de teste local (PostgreSQL 9.1.6 no Debian Squeeze) e adicionei a localidade ao meu cluster de banco de dados:CREATE COLLATION "ca_ES" (LOCALE = 'ca_ES.utf8');
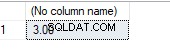
Eu recebo os mesmos resultados que podem ser vistos no sqlfiddle acima.
Observe que os nomes de agrupamentos são identificadores e precisam ser colocados entre aspas duplas para preservar a ortografia do CamelCase como
"ca_ES" . Talvez tenha havido alguma confusão com outras localidades em seu sistema? Verifique seus agrupamentos disponíveis
:SELECT * FROM pg_collation;
Geralmente, as regras de agrupamento são derivadas de localidades do sistema . Leia sobre os detalhes no manual aqui . Se você ainda obtiver resultados incorretos, tentarei atualizar seu sistema e gerar novamente a localidade para
"ca_ES" . No Debian (e distribuições Linux relacionadas), isso pode ser feito com:dpkg-reconfigure locales
NFC
Eu tenho uma outra ideia:strings UNICODE não normalizadas .
Pode ser que seu
'Àudio' é de fato '̀ ' || 'Audio' ? Esse seria esse personagem:SELECT U&'\0300A';
SELECT ascii(U&'\0300A');
SELECT chr(768);
Leia mais sobre o sotaque agudo na wikipedia .
Você tem que
SET standard_conforming_strings = TRUE para usar strings Unicode como na primeira linha. Observe que alguns navegadores não podem exibir caracteres Unicode não normalizados corretamente e muitas fontes não possuem glifos adequados para os caracteres especiais, portanto, você pode não ver nada aqui ou algo sem sentido. Mas o UNICODE permite esse absurdo. Teste para ver o que você tem:
SELECT octet_length('̀A') -- returns 3 (!)
SELECT octet_length('À') -- returns 2
Se é isso que seu banco de dados contratou, você precisa se livrar dele ou sofrer as consequências. A cura é normalizar suas strings para NFC . Perl tem habilidades superiores em UNICODE-foo, você pode fazer uso de suas bibliotecas em uma função plperlu para fazer isso no PostgreSQL. Fiz isso para me salvar da loucura.
Leia as instruções de instalação neste excelente artigo sobre normalização UNICODE no PostgreSQL por David Wheeler .
Leia todos os detalhes sangrentos sobre os Formulários de Normalização Unicode em unicode.org .