Alta disponibilidade é um requisito para muitos sistemas, independentemente da tecnologia que você está usando. Isso é especialmente importante para bancos de dados, pois eles armazenam dados dos quais os aplicativos dependem. Dependendo dos requisitos, existem diferentes maneiras de implantar um ambiente de Alta Disponibilidade para PostgreSQL, mas é sempre necessário usar uma ferramenta complementar, pois os recursos nativos do PostgreSQL não são suficientes.
Neste blog, veremos como implantar o Percona Distribution for PostgreSQL para alta disponibilidade e que tipo de ferramentas são necessárias para isso.
Distribuição Percona para PostgreSQL
É uma coleção de ferramentas para ajudá-lo a gerenciar seu sistema de banco de dados PostgreSQL. Ele instala o PostgreSQL e o complementa com uma seleção de extensões que permitem resolver tarefas práticas essenciais com eficiência, incluindo:
- pg_repack :reconstrói objetos de banco de dados PostgreSQL.
- pgaudit :fornece registro detalhado de auditoria de sessão ou objeto por meio do recurso de registro padrão do PostgreSQL.
- pgBackRest :É uma solução de backup e restauração para PostgreSQL.
- Patronos :É uma solução de alta disponibilidade para PostgreSQL.
- pg_stat_monitor :ele coleta e agrega estatísticas para PostgreSQL e fornece informações de histograma.
- Uma coleção de extensões adicionais de contribuição do PostgreSQL.
Alta disponibilidade no PostgreSQL
Existem diferentes arquiteturas para alta disponibilidade do PostgreSQL, mas a mais comum é ter uma topologia Master-Slave (Primary-Standby). Ele é baseado em um banco de dados primário com um ou mais nós de espera. Esses bancos de dados em espera permanecerão sincronizados (ou quase sincronizados) com o primário, dependendo se a replicação for síncrona ou assíncrona. Se o servidor principal falhar, o standby contém quase todos os dados do servidor principal e pode ser rapidamente transformado no novo servidor de banco de dados primário.
Mas uma configuração mestre-escravo não é suficiente para garantir efetivamente a alta disponibilidade, pois você também precisa lidar com falhas. Depois que uma falha for detectada, você poderá selecionar um nó em espera e fazer failover para ele com o menor atraso possível. O próprio PostgreSQL não inclui um mecanismo de failover automático, portanto, isso exigirá algum script personalizado ou ferramentas de terceiros para essa automação.
Após ocorrer um failover, os aplicativos precisam ser notificados de acordo, para que possam começar a usar o novo nó primário. Além disso, você precisa avaliar o estado de nossa arquitetura após um failover, porque você pode executar em uma situação em que você tem apenas o novo primário em execução (ou seja, você tinha um nó primário e apenas um em espera antes do problema). Nesse caso, você precisará adicionar um novo nó de espera de alguma forma para recriar a configuração mestre-escravo que você tinha originalmente para alta disponibilidade.
Para que funcione, você precisará ter diferentes ferramentas/serviços para ajudá-lo nessa tarefa.
Balanceadores de carga
Load balancers são ferramentas que podem ser usadas para gerenciar o tráfego de seu aplicativo para obter o máximo de sua arquitetura de banco de dados.
Não só é útil para equilibrar a carga de nossos bancos de dados, mas também ajuda os aplicativos a serem redirecionados para os nós disponíveis/saudáveis e até mesmo especificar portas com funções diferentes.
HAProxy é um balanceador de carga que distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para esta tarefa. Se algum dos destinos parar de responder, ele será marcado como off-line e o tráfego será enviado para o restante dos destinos disponíveis.
Keepalived é um serviço que permite configurar um IP virtual dentro de um grupo ativo/passivo de servidores. Este IP virtual é atribuído a um servidor ativo. Caso este servidor falhe, o IP é migrado automaticamente para o servidor passivo “Secundário”, permitindo que ele continue trabalhando com o mesmo IP de forma transparente para os sistemas.
Para implementar todas essas coisas você pode fazer isso manualmente, o que significa trabalho extra e tarefas demoradas, ou você pode fazer isso a partir de apenas um sistema usando o ClusterControl.
Vamos ver como importar sua distribuição Percona existente para PostgreSQL para ClusterControl e, em seguida, como configurar um ambiente de alta disponibilidade usando HAProxy e Keepalived em torno dessa configuração a partir de uma interface amigável e fácil de usar.
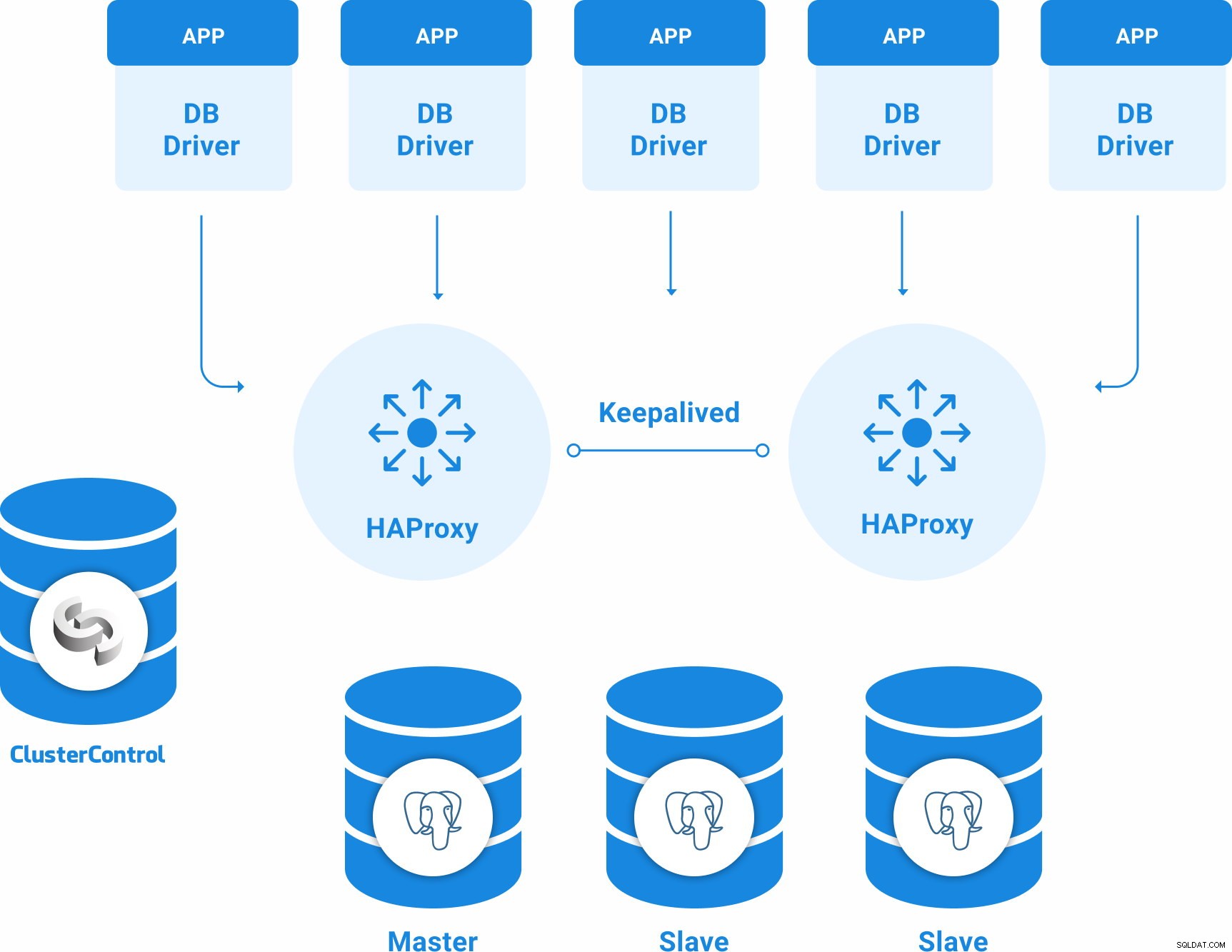
Topologia PostgreSQL para alta disponibilidade
Uma topologia básica de alta disponibilidade para PostgreSQL pode ser:
- 3 servidores PostgreSQL 12 (um primário e dois nós de espera).
- 2 balanceadores de carga HAProxy.
- Mantido configurado entre os servidores do balanceador de carga.
- 1 servidor ClusterControl
Então, você terá a seguinte topologia:
Como instalar o Percona Distribution para PostgreSQL
Vamos começar instalando o Percona Distribution para PostgreSQL. Para este exemplo, usaremos o CentOS 7 e o PostgreSQL 12.
Se você tiver seu cluster instalado, vá para a próxima seção para importar seu banco de dados existente para o ClusterControl.
Instale epel-release e percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmAtive o repositório PostgreSQL 12
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Instale o pacote do servidor
$ yum install percona-postgresql12-serverObserve que este pacote não instalará todos os componentes do Percona Distribution. Para instalar esses componentes, use os pacotes opcionais apropriados, conforme mostrado abaixo:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribInicializar o banco de dados
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKCertifique-se de ter a configuração correta para poder configurar uma replicação do PostgreSQL, semelhante a:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onEm seguida, inicie o serviço de banco de dados
$ systemctl start postgresql-12Agora, se desejar adicionar nós em espera, repita as etapas 1, 2 e 3 em todos os nós que deseja adicionar ao cluster. Para esses nós, você não precisa configurar mais nada, pois o ClusterControl criará a configuração correspondente.
Importando Distribuição Percona para PostgreSQL no ClusterControl
Com o ClusterControl você pode implantar ou importar diferentes mecanismos de banco de dados de código aberto do mesmo sistema, sendo necessário apenas acesso SSH e um usuário privilegiado para usá-lo.
Vá para a seção “Importar” e preencha as informações necessárias do seu servidor PostgreSQL.
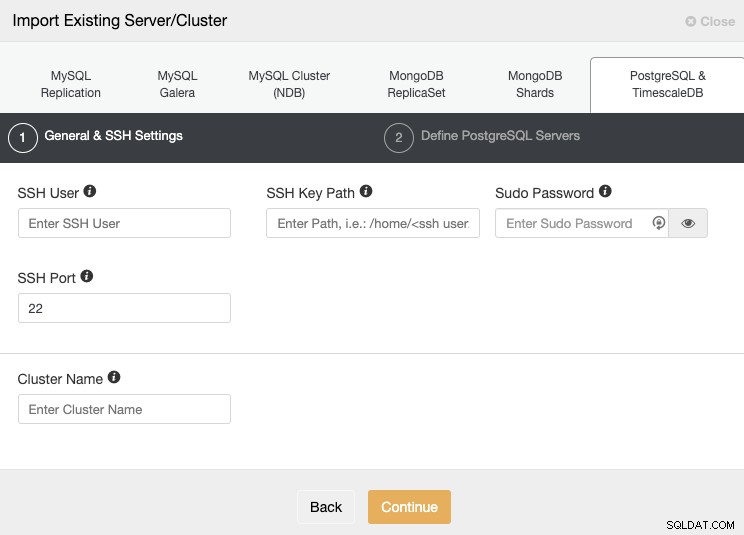
Você deve especificar Usuário, Chave ou Senha e porta para se conectar por SSH aos seus servidores. Você também precisa de um nome para seu novo cluster, caso contrário, o ClusterControl atribuirá um nome genérico para você.
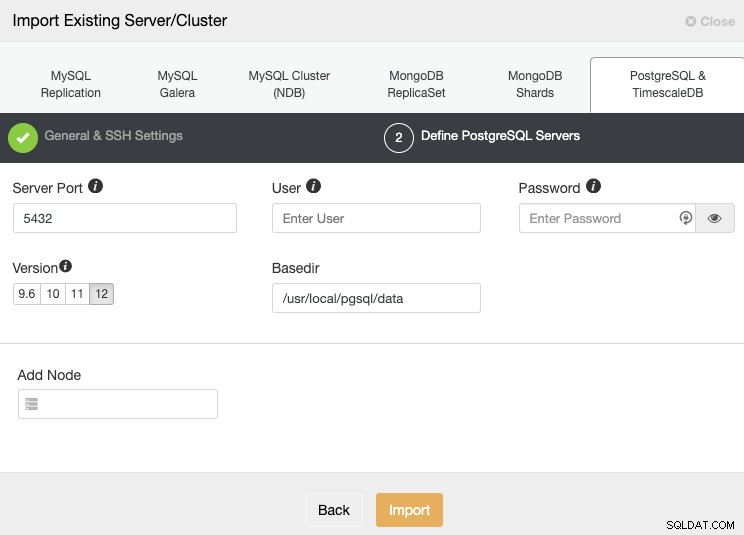
Após configurar as informações de acesso SSH, você deve definir as credenciais do banco de dados, version, basedir e o endereço IP ou nome do host para cada nó do banco de dados.
Se você ainda não configurou a replicação, basta adicionar o endereço IP ou o nome do host para o nó principal, pois mostraremos como adicionar o restante dos nós posteriormente.
Certifique-se de obter o visto verde ao inserir o nome do host ou o endereço IP, indicando que o ClusterControl pode se comunicar com o nó. Em seguida, clique no botão Importar e aguarde até que o ClusterControl termine seu trabalho. Você pode monitorar o processo na Seção de Atividade do ClusterControl. Quando terminar, você verá o novo cluster na tela principal do ClusterControl. Para adicionar uma nova réplica, acesse as ações do cluster e selecione a opção “Add Replication Slave”.
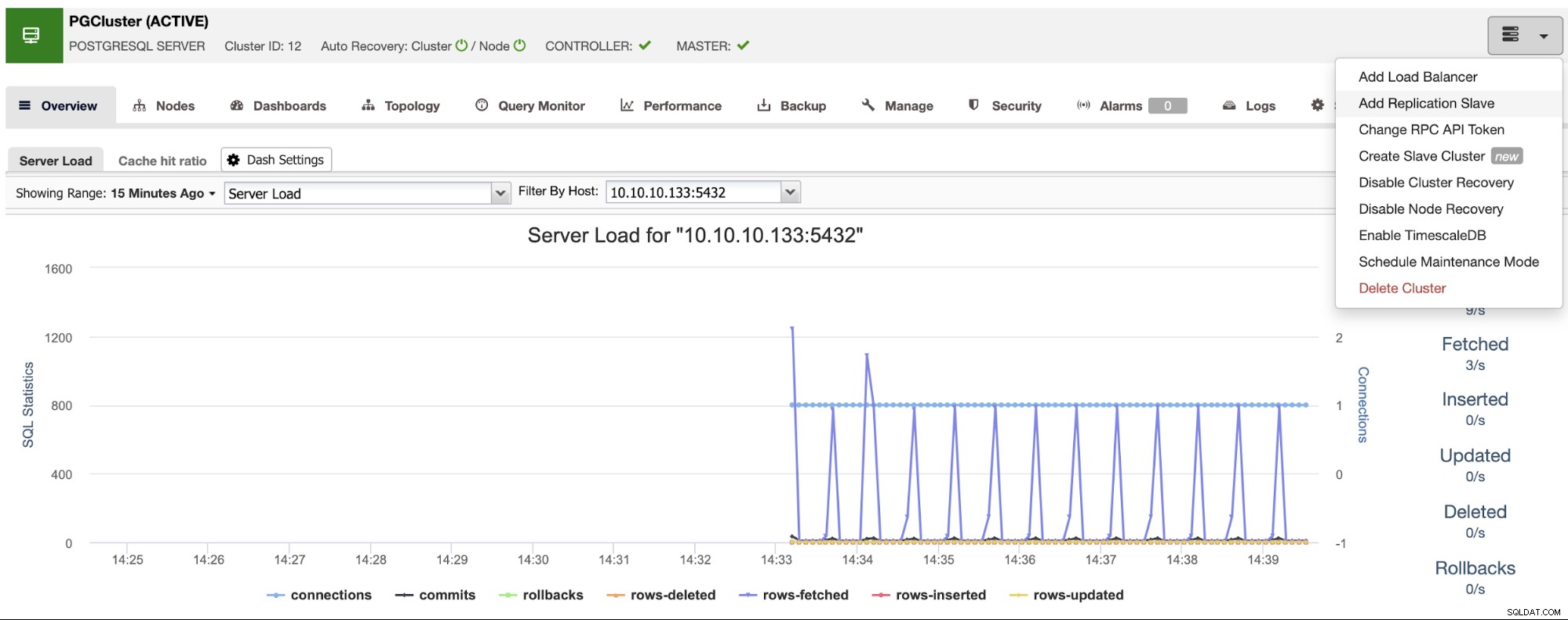
Se você seguiu as etapas anteriores, terá o Percona Distribution for PostgreSQL instalado em todos os nós standby, então você precisa desabilitar o “Install PostgreSQL software” nesta seção.
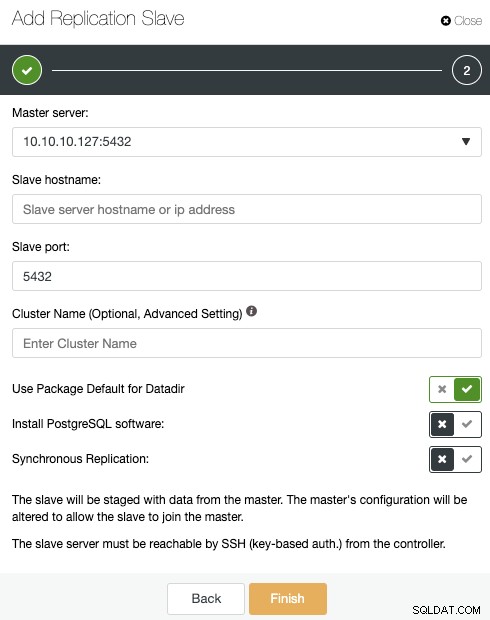
Dessa forma, o ClusterControl usará os pacotes Percona Distribution for PostgreSQL instalados. de instalar os pacotes oficiais do PostgreSQL.
Ao terminar, você verá todos os nós do cluster e o status de todos eles na seção de visão geral.
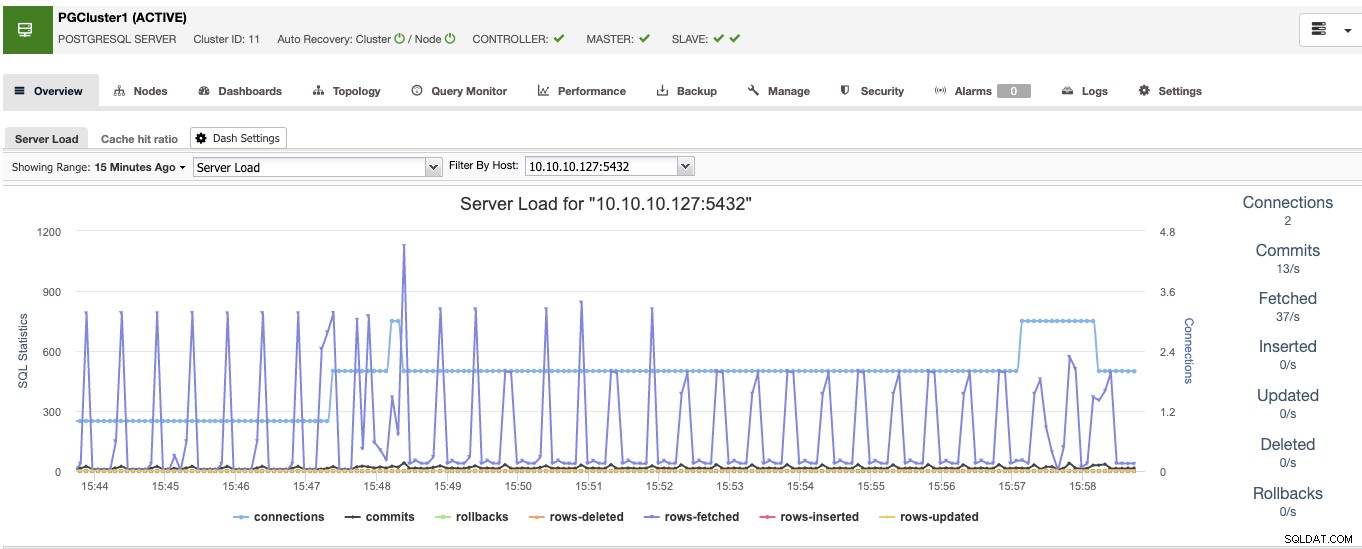
Agora você tem o lado do banco de dados pronto, vamos ver como completar o High Ambiente de disponibilidade adicionando o restante das ferramentas usando ClusterControl.
Implantação do balanceador de carga
Para realizar uma implantação do load balancer, selecione a opção “Add Load Balancer” nas ações do cluster e preencha as informações solicitadas. 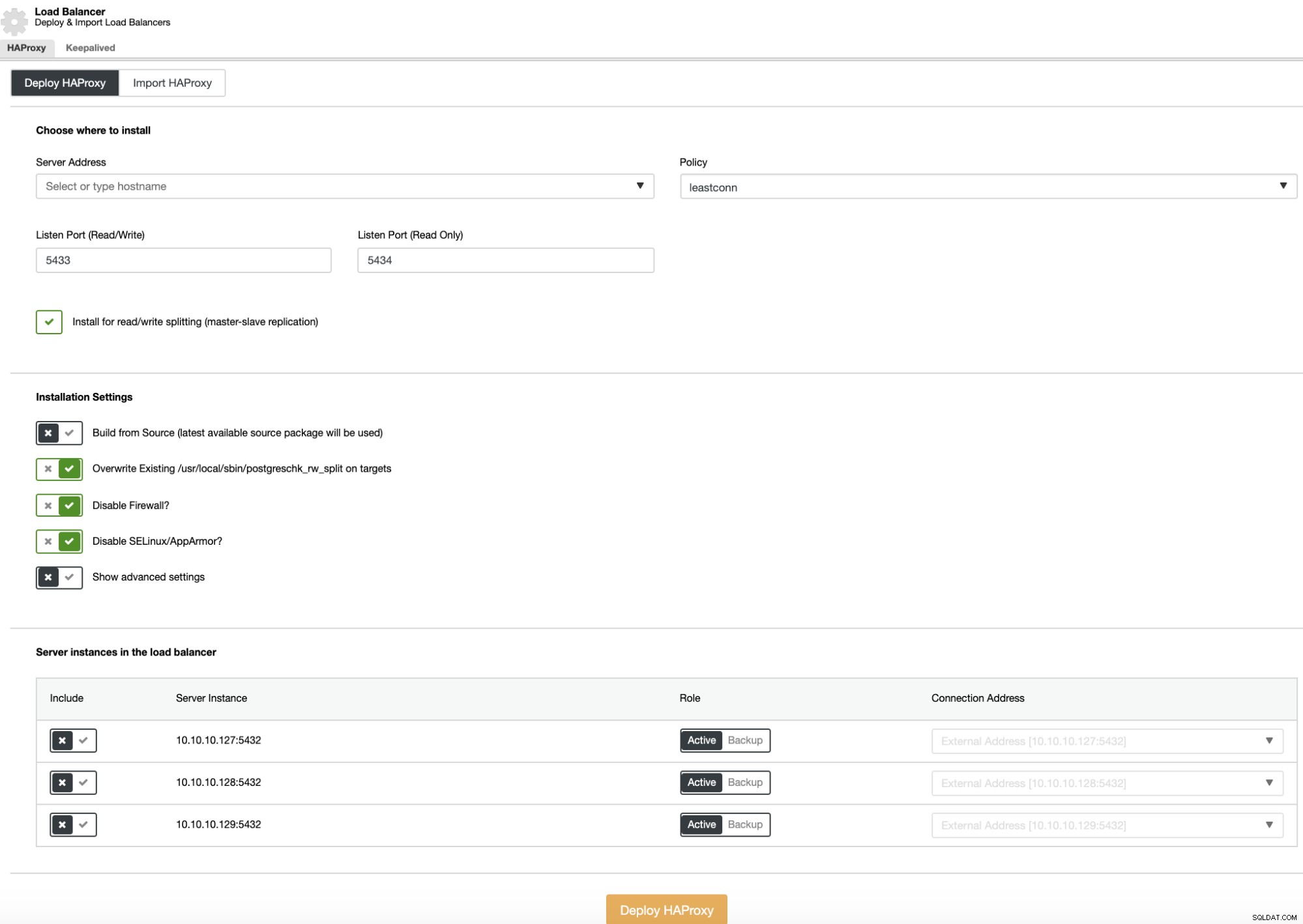
Você só precisa adicionar endereço IP ou nome de host, porta, política e os nós que você adicionará à configuração do balanceador de carga.
Implantação mantida
Para executar uma implantação Keepalived, selecione o cluster, vá para ações do cluster, selecione “Adicionar balanceador de carga” e, em seguida, vá para a seção “Keepalived”.
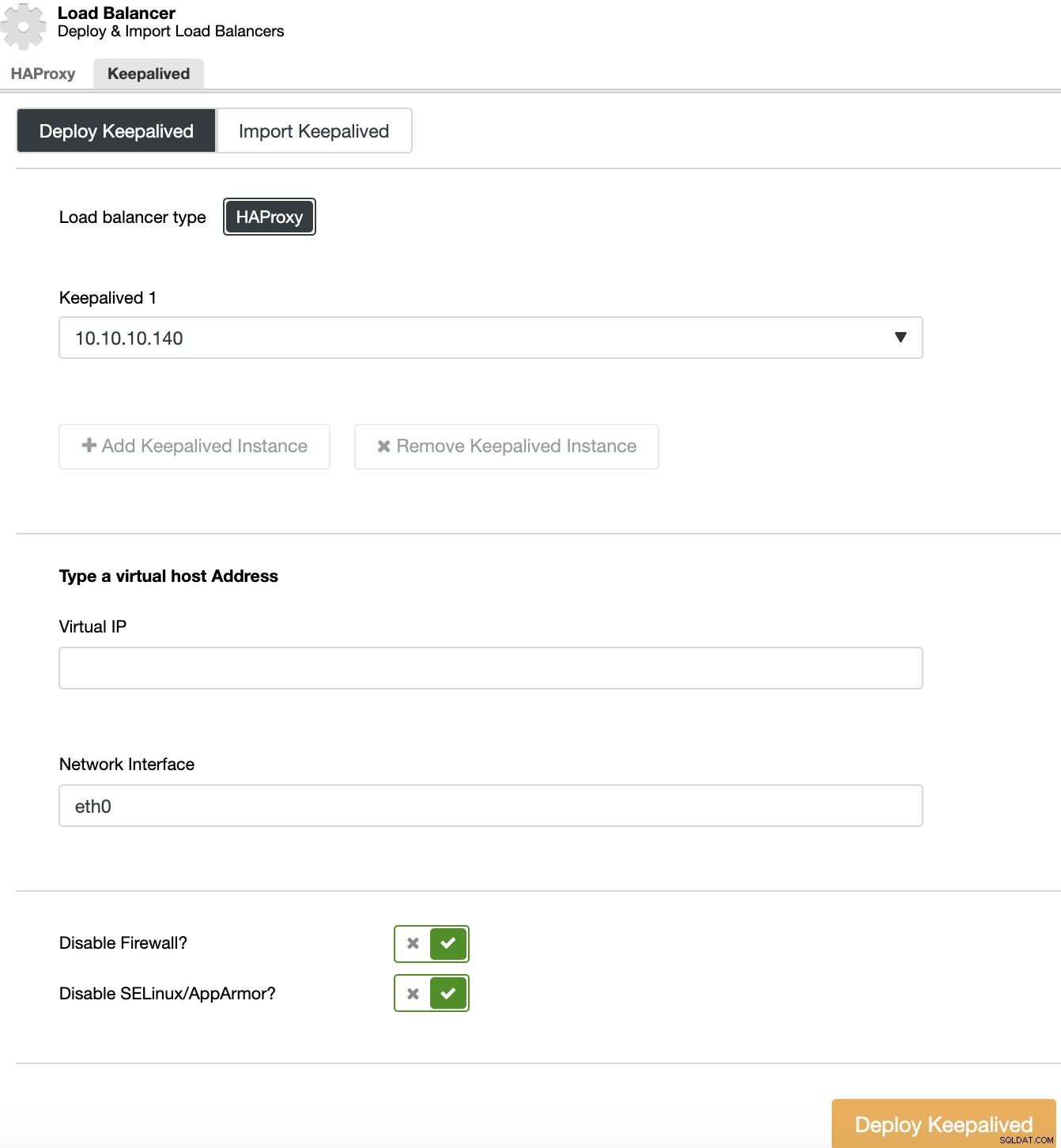
Para seu ambiente de alta disponibilidade, você precisa selecionar os servidores do balanceador de carga e o endereço IP virtual, que você precisará usar para acessar seu cluster. Keepalived configura esse IP virtual no balanceador de carga ativo e o migra de um balanceador de carga para outro em caso de falha, para que sua configuração possa continuar funcionando normalmente.
Conclusão
Como você ainda não pode implantar o Percona Distribution for PostgreSQL diretamente do ClusterControl, neste blog, mostramos como gerenciá-lo usando o ClusterControl e como adicionar ferramentas diferentes, como HAProxy e Keepalived, para ter um ambiente de alta disponibilidade. de um jeito fácil.



