Embora existam várias maneiras de recuperar seu banco de dados PostgreSQL, uma das abordagens mais convenientes para restaurar seus dados a partir de um backup lógico. Os backups lógicos desempenham um papel significativo para o Planejamento de Desastres e Recuperação (DRP). Backups lógicos são backups feitos, por exemplo, usando pg_dump ou pg_dumpall, que geram instruções SQL para obter todos os dados da tabela que são gravados em um arquivo binário.
Também é recomendável executar backups lógicos periódicos caso seus backups físicos falhem ou estejam indisponíveis. Para o PostgreSQL, a restauração pode ser problemática se você não tiver certeza de quais ferramentas usar. A ferramenta de backup pg_dump geralmente é combinada com a ferramenta de restauração pg_restore.
pg_dump e pg_restore atuam em conjunto se ocorrer um desastre e você precisar recuperar seus dados. Embora eles atendam ao objetivo principal de despejo e restauração, ele exige que você execute algumas tarefas extras quando precisar recuperar seu cluster e fazer um failover (se seu primário ou mestre ativo morrer devido a falha de hardware ou corrupção do sistema VM). Você acabará encontrando e utilizando ferramentas de terceiros que podem lidar com failover ou recuperação automática de cluster.
Neste blog, veremos como o pg_restore funciona e o compararemos com como o ClusterControl lida com o backup e a restauração de seus dados em caso de desastre.
Mecanismos de pg_restore
pg_restore é útil ao obter as seguintes tarefas:
- emparelhado com pg_dump para gerar arquivos gerados por SQL contendo dados, funções de acesso, banco de dados e definições de tabela
- restaure um banco de dados PostgreSQL a partir de um arquivo criado por pg_dump em um dos formatos que não sejam de texto simples.
- Ele emitirá os comandos necessários para reconstruir o banco de dados para o estado em que estava no momento em que foi salvo.
- pode ser seletivo ou até mesmo reordenar os itens antes de serem restaurados com base no arquivo
- Os arquivos compactados são projetados para serem portáteis entre arquiteturas.
- pg_restore pode operar em dois modos.
- Se um nome de banco de dados for especificado, o pg_restore se conectará a esse banco de dados e restaurará o conteúdo do arquivo diretamente no banco de dados.
- ou, um script contendo os comandos SQL necessários para reconstruir o banco de dados é criado e gravado em um arquivo ou saída padrão. Sua saída de script tem equivalência ao formato gerado por pg_dump
- Algumas das opções que controlam a saída são, portanto, análogas às opções do pg_dump.
Depois de restaurar os dados, é melhor e aconselhável executar ANALYZE em cada tabela restaurada para que o otimizador tenha estatísticas úteis. Embora adquira READ LOCK, talvez seja necessário executá-lo durante um tráfego baixo ou durante o período de manutenção.
Vantagens do pg_restore
pg_dump e pg_restore em conjunto têm recursos que são convenientes para um DBA utilizar.
- pg_dump e pg_restore podem ser executados em paralelo especificando a opção -j. O uso de -j/--jobs
permite especificar quantos trabalhos em execução em paralelo podem ser executados especialmente para carregar dados, criar índices ou criar restrições usando vários trabalhos simultâneos. - É muito prático de usar, você pode despejar ou carregar seletivamente banco de dados ou tabelas específicas
- Permite e fornece flexibilidade ao usuário sobre qual banco de dados, esquema ou reordenar os procedimentos específicos a serem executados com base na lista. Você pode até gerar e carregar a sequência de SQL livremente como prevent acls ou privilégio de acordo com suas necessidades. Há muitas opções para atender às suas necessidades.
- Ele fornece a capacidade de gerar arquivos SQL como pg_dump de um arquivo. Isso é muito conveniente se você quiser carregar em outro banco de dados ou host para provisionar um ambiente separado.
- É fácil de entender com base na sequência gerada de procedimentos SQL.
- É uma maneira conveniente de carregar dados em um ambiente de replicação. Você não precisa que sua réplica seja reestabelecida, pois as instruções são SQL que foram replicadas para os nós de espera e recuperação.
Limitações do pg_restore
Para backups lógicos, as limitações óbvias do pg_restore junto com o pg_dump são o desempenho e a velocidade ao utilizar as ferramentas. Pode ser útil quando você deseja provisionar um ambiente de banco de dados de teste ou desenvolvimento e carregar seus dados, mas não é aplicável quando seu conjunto de dados é enorme. O PostgreSQL precisa despejar seus dados um por um ou executar e aplicar seus dados sequencialmente pelo mecanismo de banco de dados. Embora você possa tornar isso flexível para acelerar, como especificar -j ou usar --single-transaction para evitar impacto em seu banco de dados, o carregamento usando SQL ainda precisa ser analisado pelo mecanismo.
Além disso, a documentação do PostgreSQL declara as seguintes limitações, com nossas adições conforme observamos essas ferramentas (pg_dump e pg_restore):
- Ao restaurar dados para uma tabela pré-existente e a opção --disable-triggers é usada, o pg_restore emite comandos para desabilitar gatilhos nas tabelas do usuário antes de inserir os dados e, em seguida, emite comandos para reativá-los após a inserção dos dados. Se a restauração for interrompida no meio, os catálogos do sistema podem ficar no estado errado.
- pg_restore não pode restaurar objetos grandes seletivamente; por exemplo, apenas aqueles para uma tabela específica. Se um arquivo contiver objetos grandes, todos os objetos grandes serão restaurados, ou nenhum deles se forem excluídos por meio de -L, -t ou outras opções.
- Espera-se que ambas as ferramentas gerem uma grande quantidade de tamanho (arquivos, diretório ou arquivo tar), especialmente para um banco de dados enorme.
- Para pg_dump, ao despejar uma única tabela ou como texto simples, o pg_dump não manipula objetos grandes. Objetos grandes devem ser despejados com todo o banco de dados usando um dos formatos de arquivo não-texto.
- Se você tiver arquivos tar gerados por essas ferramentas, observe que os arquivos tar estão limitados a um tamanho inferior a 8 GB. Esta é uma limitação inerente ao formato do arquivo tar. Portanto, esse formato não pode ser usado se a representação textual de uma tabela exceder esse tamanho. O tamanho total de um arquivo tar e qualquer outro formato de saída não é limitado, exceto possivelmente pelo sistema operacional.
Usando pg_restore
Usar o pg_restore é bastante prático e fácil de utilizar. Como está emparelhado com o pg_dump, ambas as ferramentas funcionam suficientemente bem, desde que a saída de destino seja adequada à outra. Por exemplo, o seguinte pg_dump não será útil para pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Este resultado será compatível com psql que se parece com o seguinte:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Mas isso falhará para pg_restore, pois não há um formato simples a seguir:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerAgora, vamos a termos mais úteis para pg_restore.
pg_restore:Soltar e restaurar
Considere um uso simples de pg_restore que você derrubou um banco de dados, por exemplo
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Restaurando com pg_restore é muito simples,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump O -C/--create aqui indica que cria o banco de dados assim que for encontrado no cabeçalho. O -d postgres aponta para o banco de dados postgres, mas não significa que ele criará as tabelas para o banco de dados postgres. Requer que o banco de dados exista. Se -C não for especificado, a(s) tabela(s) e os registros serão armazenados nesse banco de dados referenciado com o argumento -d.
Restaurando seletivamente por tabela
Restaurar uma tabela com pg_restore é fácil e simples. Por exemplo, você tem duas tabelas, a saber, tabelas "b" e "d". Digamos que você execute o seguinte comando pg_dump abaixo,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Onde o conteúdo deste diretório terá a seguinte aparência,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Se você deseja restaurar uma tabela (ou seja, "d" neste exemplo),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Deve ter,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Copiando tabelas de banco de dados para um banco de dados diferente
Você pode até copiar o conteúdo de seu banco de dados existente e tê-lo em seu banco de dados de destino. Por exemplo, eu tenho os seguintes bancos de dados,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)O banco de dados paultest é um banco de dados vazio enquanto vamos copiar o que está dentro do banco de dados maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Para copiá-lo, precisamos despejar os dados do banco de dados maxtest da seguinte forma,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Em seguida, carregue ou restaure-o da seguinte maneira,
Agora, temos dados no banco de dados paultest e as tabelas foram armazenadas de acordo.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Gerar um arquivo SQL com reordenação
Tenho visto muito uso com pg_restore, mas parece que esse recurso geralmente não é exibido. Achei essa abordagem muito interessante, pois permite que você faça pedidos com base no que não deseja incluir e, em seguida, gere um arquivo SQL a partir do pedido que deseja prosseguir.
Por exemplo, usaremos o exemplo pgdump_data.tar que geramos anteriormente e criaremos uma lista. Para fazer isso, execute o seguinte comando:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listIsto irá gerar um arquivo como mostrado abaixo:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresAgora, vamos reordenar ou digamos que eu removi a criação de SEQUENCE e também a criação da restrição. Isso ficaria da seguinte forma,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresPara gerar o arquivo no formato SQL, basta fazer o seguinte:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Agora, o arquivo /tmp/selective_data.out será um arquivo gerado por SQL e é legível se você usar psql, mas não pg_restore. O que é ótimo nisso é que você pode gerar um arquivo SQL de acordo com seu modelo no qual os dados só podem ser restaurados de um arquivo existente ou backup feito usando pg_dump com a ajuda de pg_restore.
Restauração do PostgreSQL com ClusterControl
ClusterControl não utiliza pg_restore ou pg_dump como parte de seu conjunto de recursos. Usamos pg_dumpall para gerar backups lógicos e, infelizmente, a saída não é compatível com pg_restore.
Existem várias outras maneiras de gerar um backup no PostgreSQL, como visto abaixo.
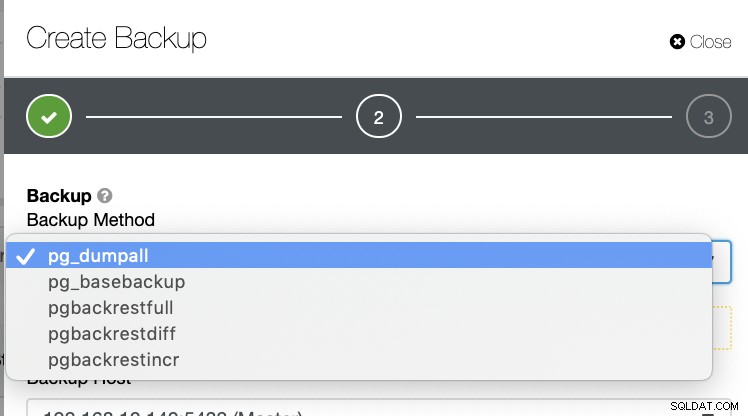
Não existe tal mecanismo onde você pode armazenar seletivamente uma tabela, um banco de dados, ou copie de um banco de dados para outro banco de dados.
O ClusterControl suporta a recuperação pontual (PITR), mas isso não permite que você gerencie a restauração de dados tão flexível quanto com o pg_restore. Para toda a lista de métodos de backup, apenas pg_basebackup e pgbackrest são compatíveis com PITR.
Como o ClusterControl lida com a restauração é que ele tem a capacidade de recuperar um cluster com falha, desde que a Recuperação Automática esteja habilitada, conforme mostrado abaixo.

Uma vez que o mestre falhe, o escravo pode recuperar automaticamente o cluster conforme o ClusterControl executa o failover (que é feito automaticamente). Para a parte de recuperação de dados, sua única opção é ter uma recuperação em todo o cluster, o que significa que ela vem de um backup completo. Não há capacidade de restaurar seletivamente no banco de dados ou tabela de destino que você deseja restaurar apenas. Se você quiser fazer isso, restaure o backup completo, é fácil fazer isso com o ClusterControl. Você pode ir para as guias de backup, como mostrado abaixo,
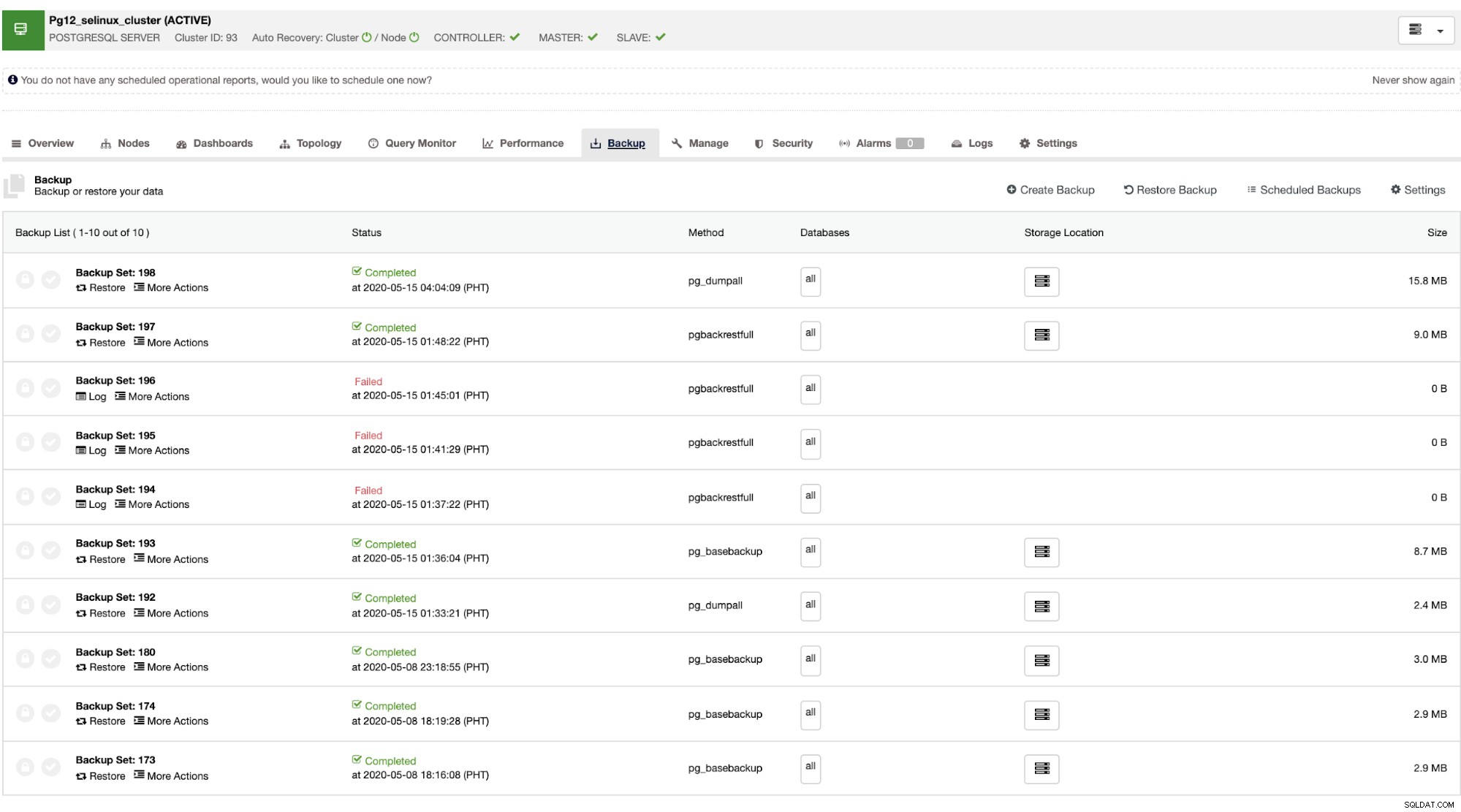
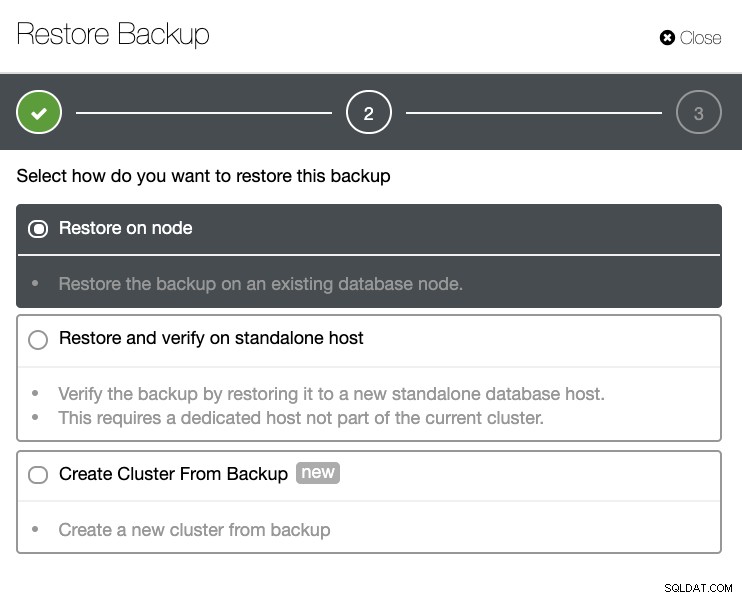
Você terá uma lista completa de backups bem-sucedidos e com falha. Em seguida, a restauração pode ser feita escolhendo o backup de destino e clicando no botão "Restaurar". Isso permitirá restaurar em um nó existente registrado no ClusterControl, verificar em um nó autônomo ou criar um cluster a partir do backup.
Conclusão
Usar pg_dump e pg_restore simplifica a abordagem de backup/dump e restauração. No entanto, para um ambiente de banco de dados de grande escala, isso pode não ser um componente ideal para recuperação de desastres. Para um procedimento mínimo de seleção e restauração, usar a combinação de pg_dump e pg_restore fornece o poder de descarregar e carregar seus dados de acordo com suas necessidades.
Para ambientes de produção (especialmente para arquiteturas corporativas), você pode usar a abordagem ClusterControl para criar um backup e uma restauração com recuperação automática.
Uma combinação de abordagens também é uma boa abordagem. Isso ajuda você a reduzir seu RTO e RPO e, ao mesmo tempo, aproveitar a maneira mais flexível de restaurar seus dados quando necessário.