A maioria das cargas de trabalho OLTP envolve o uso de E/S de disco aleatório. Sabendo que os discos (incluindo SSD) têm desempenho mais lento do que usar RAM, os sistemas de banco de dados usam o cache para aumentar o desempenho. O armazenamento em cache consiste em armazenar dados na memória (RAM) para acesso mais rápido em um momento posterior.
O PostgreSQL também utiliza cache de seus dados em um espaço chamado shared_buffers. Neste blog, exploraremos essa funcionalidade para ajudá-lo a aumentar o desempenho.
Noções básicas de cache do PostgreSQL
Antes de nos aprofundarmos no conceito de cache, vamos fazer uma revisão do básico.
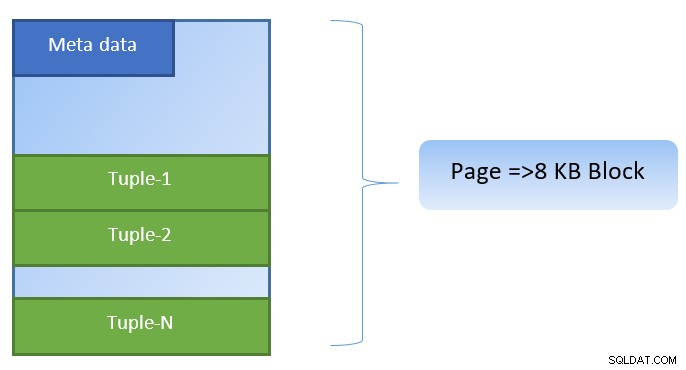
No PostgreSQL, os dados são organizados na forma de páginas de tamanho 8KB, e cada uma dessas páginas pode conter várias tuplas (dependendo do tamanho da tupla). Uma representação simplista poderia ser como abaixo:
O PostgreSQL armazena em cache o seguinte para acelerar o acesso aos dados:
- Dados em tabelas
- Índices
- Planos de execução de consultas
Enquanto o cache do plano de execução da consulta se concentra em economizar ciclos de CPU; o armazenamento em cache para dados de tabela e dados de índice é focado para economizar na operação de E/S de disco dispendiosa.
O PostgreSQL permite que os usuários definam quanta memória eles gostariam de reservar para manter esse cache de dados. A configuração relevante é shared_buffers no arquivo de configuração postgresql.conf. O valor finito de shared_buffers define quantas páginas podem ser armazenadas em cache a qualquer momento.
À medida que uma consulta é executada, o PostgreSQL procura a página no disco que contém a tupla relevante e a coloca no cache shared_buffers para acesso lateral. Da próxima vez que a mesma tupla (ou qualquer tupla na mesma página) precisar ser acessada, o PostgreSQL pode salvar a E/S do disco lendo-a na memória.
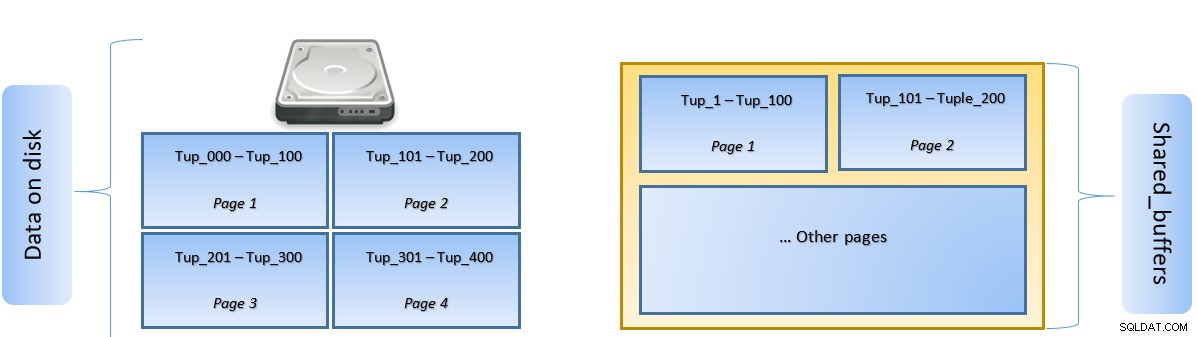
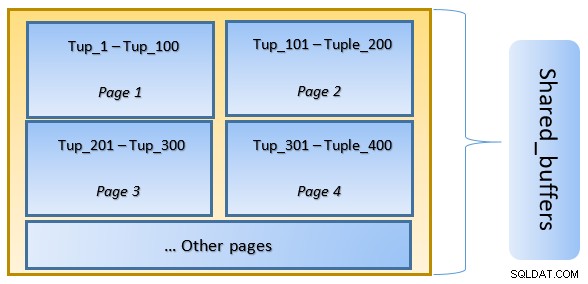
Na figura acima, Página-1 e Página-2 de um determinado tabela foram armazenados em cache. Caso uma consulta de usuário precise acessar tuplas entre Tuple-1 e Tuple-200, o PostgreSQL pode buscá-la na própria RAM.
No entanto, se a consulta precisar acessar as Tuplas 250 a 350, ela precisará fazer E/S de disco para a página 3 e a página 4. Qualquer acesso adicional para a Tupla 201 a 400 será obtido do cache e A E/S de disco não será necessária – tornando a consulta mais rápida.
Em alto nível, o PostgreSQL segue o algoritmo LRU (menos usado recentemente) para identificar as páginas que precisam ser despejadas do cache. Em outras palavras, uma página que é acessada apenas uma vez tem maiores chances de despejo (em comparação com uma página que é acessada várias vezes), caso uma nova página precise ser buscada pelo PostgreSQL no cache.
Cache do PostgreSQL em ação
Vamos executar um exemplo e ver o impacto do cache no desempenho.
Inicie o PostgreSQL mantendo shared_buffer definido como padrão de 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startConecte-se ao servidor e crie uma tabela fictícia tblDummy e um índice em c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Preencha dados fictícios com 200.000 tuplas, de modo que haja 10.000 p_id únicos e para cada p_id haja 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Reinicie o servidor para limpar o cache. Agora execute uma consulta e verifique o tempo gasto para executar a mesma
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msEm seguida, verifique os blocos lidos do disco
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0No exemplo acima, havia 1.000 blocos lidos do disco para encontrar tuplas de contagem onde c_id =1. Demorou 160 ms, pois havia E/S de disco envolvida para buscar esses registros do disco.
A execução é mais rápida se a mesma consulta for executada novamente, pois todos os blocos ainda estão no cache do servidor PostgreSQL neste estágio
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 mse blocos lidos do disco versus do cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000É evidente de cima que, como todos os blocos foram lidos do cache e nenhuma E/S de disco foi necessária. Isso, portanto, também deu os resultados mais rápido.
Definindo o tamanho do cache do PostgreSQL
O tamanho do cache precisa ser ajustado em um ambiente de produção de acordo com a quantidade de RAM disponível, bem como as consultas necessárias para serem executadas.
Como exemplo – shared_buffer de 128 MB pode não ser suficiente para armazenar em cache todos os dados, se a consulta for buscar mais tuplas:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Altere o shared_buffer para 1024 MB para aumentar o heap_blks_hit.
De fato, considerando as consultas (baseadas em c_id), caso os dados sejam reorganizados, uma melhor taxa de acertos de cache também pode ser alcançada com um shared_buffer menor.
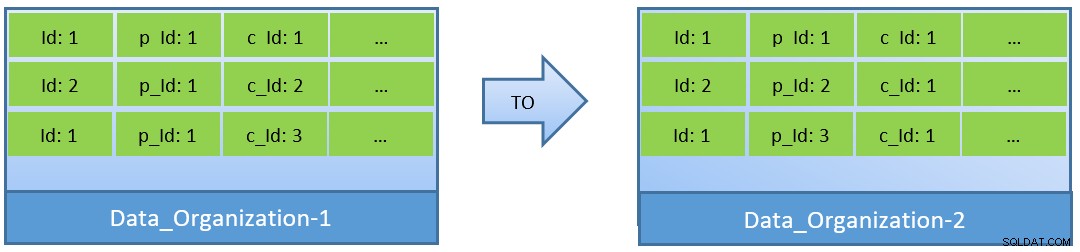
No Data_Organization-1, o PostgreSQL precisará de 1.000 leituras de bloco (e consumo de cache ) para encontrar c_id=1. Por outro lado, para Data_Organisation-2, para a mesma consulta, o PostgreSQL precisará de apenas 104 blocos.
Menos blocos necessários para a mesma consulta acabam consumindo menos cache e também mantêm o tempo de execução da consulta otimizado.
Conclusão
Enquanto o shared_buffer é mantido no nível de processo do PostgreSQL, o cache no nível do kernel também é levado em consideração para identificar planos otimizados de execução de consultas. Vou abordar este tópico em uma série posterior de blogs.