Este blog é a segunda parte de Implementação de uma configuração de vários datacenters para PostgreSQL. Neste golpe, mostraremos como implantar o PostgreSQL neste tipo de ambiente e como fazer o failover em caso de falha do mestre usando o recurso de auto-recuperação do ClusterControl.
Neste ponto, vamos supor que você tenha conectividade entre os data centers (como vimos na primeira parte deste blog) e você tem os servidores necessários para esta tarefa (como também mencionamos no parte anterior).
Implantar um cluster PostgreSQL
Nós usaremos o ClusterControl para esta tarefa, então vamos supor que você o tenha instalado (ele pode ser instalado no mesmo servidor do Load Balancer, mas se você puder usar um diferente ainda melhor).
Vá ao seu servidor ClusterControl e selecione a opção ‘Deploy’. Se você já tem uma instância do PostgreSQL em execução, então você precisa selecionar ‘Import Existing Server/Database’.
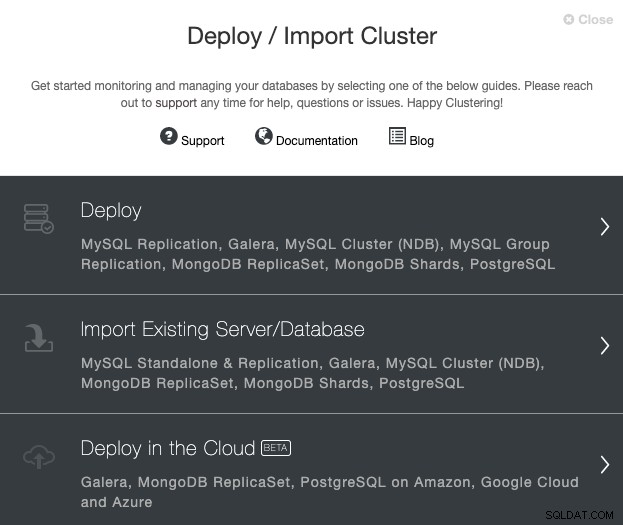
Ao selecionar PostgreSQL, você deve especificar Usuário, Chave ou Senha e porta para conectar por SSH aos nossos hosts PostgreSQL. Você também precisa do nome do seu novo cluster e se deseja que o ClusterControl instale o software e as configurações correspondentes para você.
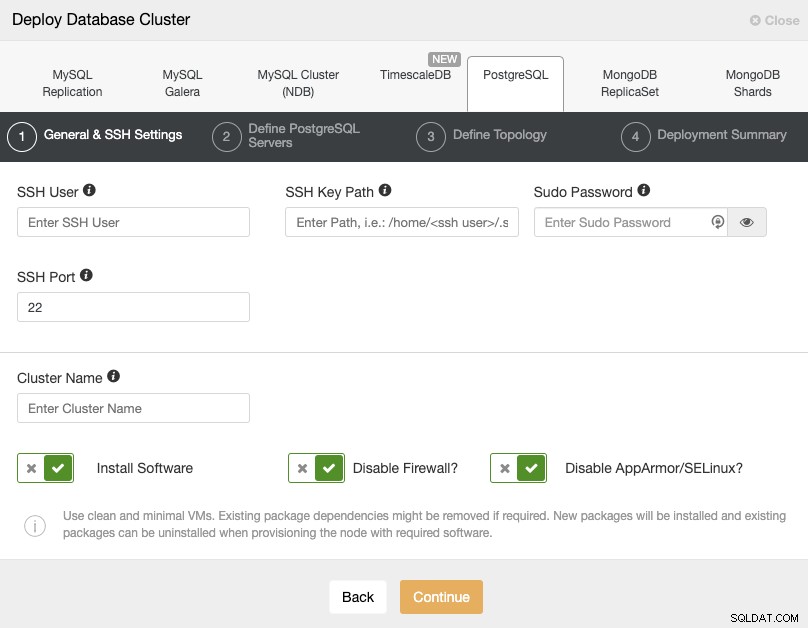
Por favor, verifique os requisitos de usuário do ClusterControl para esta tarefa aqui, mas se você seguiu No blog anterior, você deve usar o usuário 'remote' aqui e a porta SSH correta (como mencionamos, é recomendável usar uma diferente se você estiver usando o endereço IP público para acessá-la em vez de uma VPN).
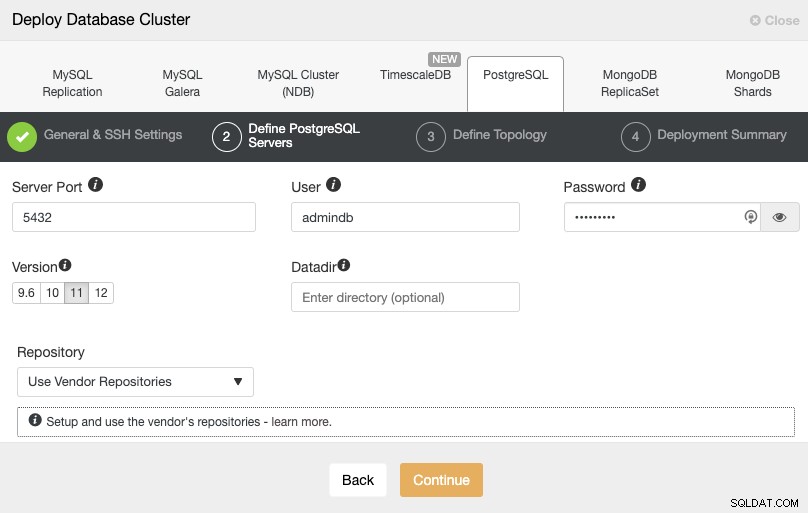
Após configurar as informações de acesso SSH, você deve definir o usuário do banco de dados, version e datadir (opcional). Você também pode especificar qual repositório usar. Na próxima etapa, você precisa adicionar seus servidores ao cluster que você criará.
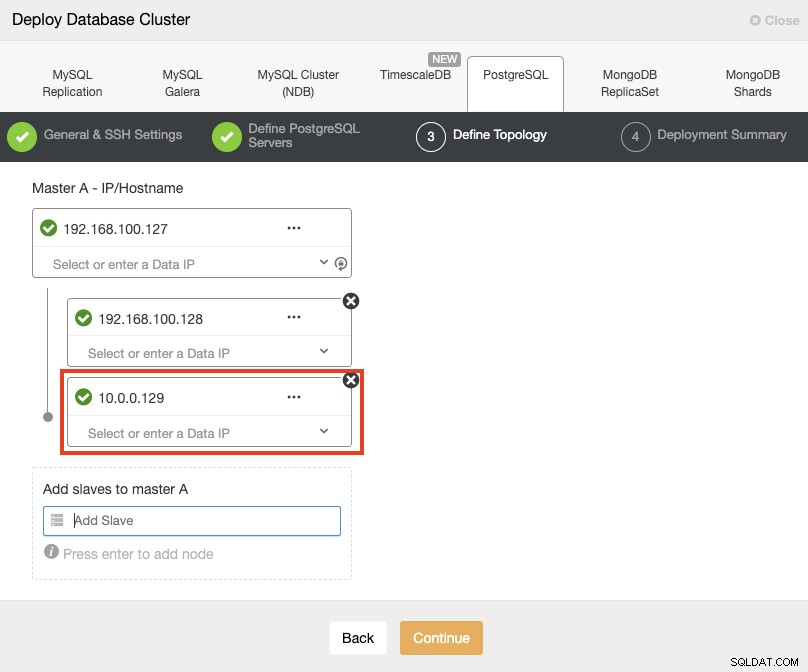
Ao adicionar seus servidores, você pode inserir o IP ou o nome do host. Nesta parte, você usará os endereços IP públicos de seus servidores e, como você pode ver na caixa vermelha, estou usando uma rede diferente para o segundo nó em espera. O ClusterControl não tem limitações quanto à rede a ser utilizada. O único requisito sobre isso é ter acesso SSH ao nó.
Então, seguindo nosso exemplo anterior, esses endereços IP devem ser:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Na última etapa, você pode escolher se sua replicação será síncrona ou assíncrona.
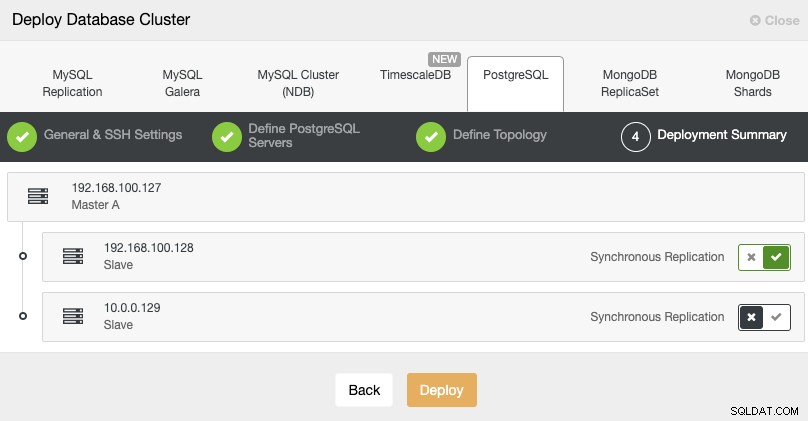
Nesse caso, é importante usar a replicação assíncrona para seu nó remoto , caso contrário, seu cluster pode ser afetado pela latência ou problemas de rede.
Você pode monitorar o status da criação de seu novo cluster no monitor de atividades do ClusterControl.
Quando a tarefa for concluída, você poderá ver seu novo cluster PostgreSQL no tela principal do ClusterControl.

Adicionando um balanceador de carga PostgreSQL (HAProxy)
Depois de criar seu cluster, você pode executar várias tarefas nele, como adicionar um balanceador de carga (HAProxy) ou uma nova réplica.
Para seguir nosso exemplo anterior, vamos adicionar um balanceador de carga que, como mencionamos, ajudará você a gerenciar seu ambiente de alta disponibilidade. Para isso, vá para ClusterControl -> Select PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
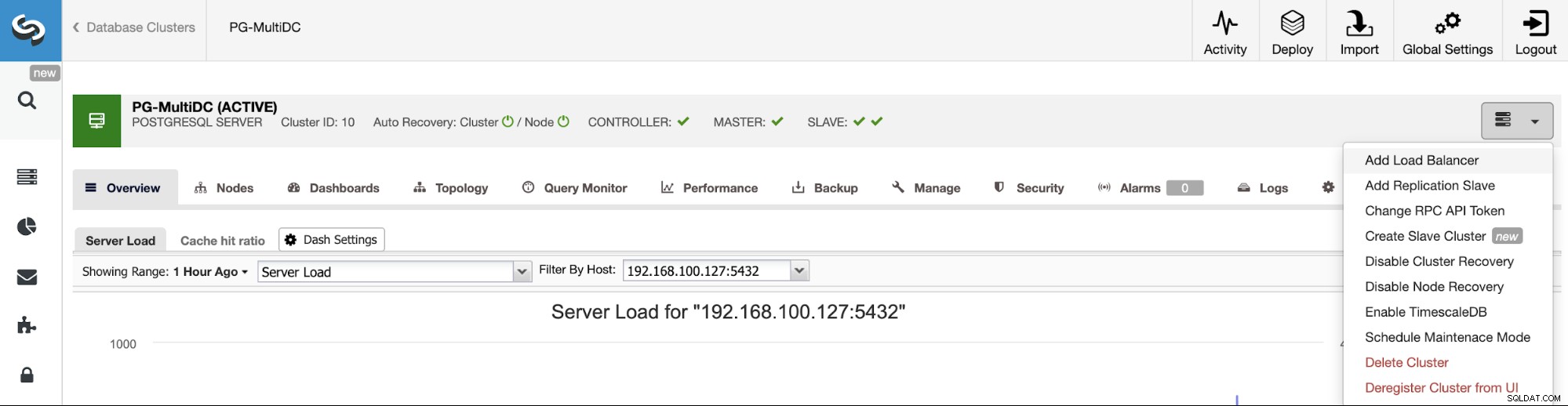
Aqui você deve adicionar as informações que o ClusterControl usará para instalar e configurar seu Balanceador de carga HAProxy. Esse Load Balancer pode ser instalado no mesmo servidor ClusterControl, mas se você puder usar um diferente, melhor ainda.
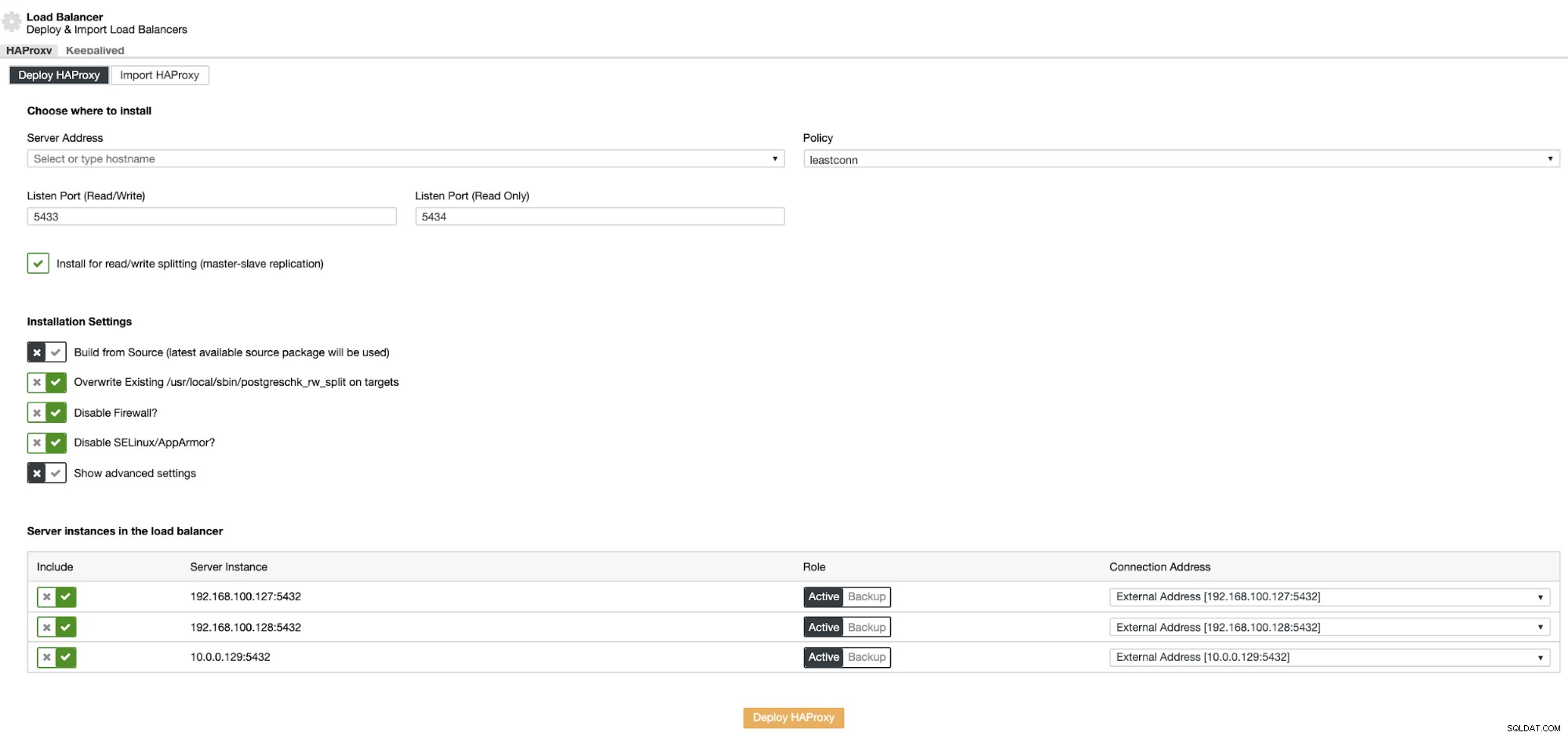
As informações que você precisa apresentar são:
Ação:Implantar ou Importar.
Endereço do Servidor:Endereço IP do seu servidor HAProxy (pode ser o mesmo Endereço IP do ClusterControl).
Porta de escuta (leitura/gravação):Porta para modo de leitura/gravação.
Porta de escuta (somente leitura):Porta para modo somente leitura.
Política:Pode ser:
- leastconn:o servidor com o menor número de conexões recebe a conexão.
- roundrobin:Cada servidor é usado em turnos, de acordo com seus pesos.
- origem:o endereço IP de origem é criptografado e dividido pelo peso total dos servidores em execução para designar qual servidor receberá a solicitação.
Instalar para divisão de leitura/gravação:para replicação mestre-escravo.
Build from Source:Você pode escolher Install from a package manager ou build from source.
E você precisa selecionar quais servidores deseja adicionar à configuração do HAProxy.
Além disso, você pode definir configurações avançadas como usuário administrador, nome de back-end, tempos limite e muito mais.
Ao concluir a configuração e confirmar a implantação, você pode acompanhar o progresso na seção Atividade na interface do usuário do ClusterControl.
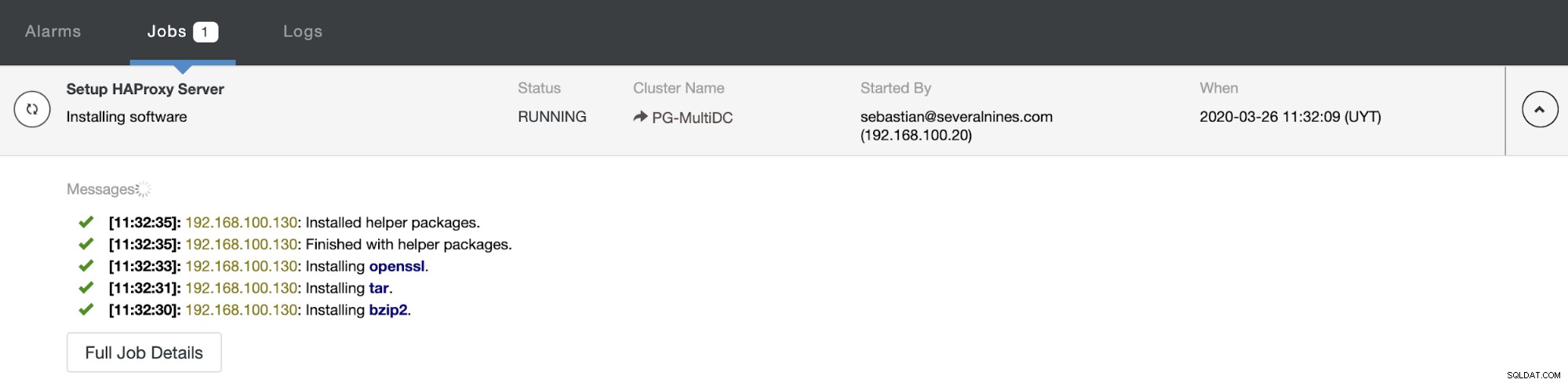
E quando isso terminar, você pode ir para ClusterControl -> Nodes -> nó HAProxy e verifique o status atual.
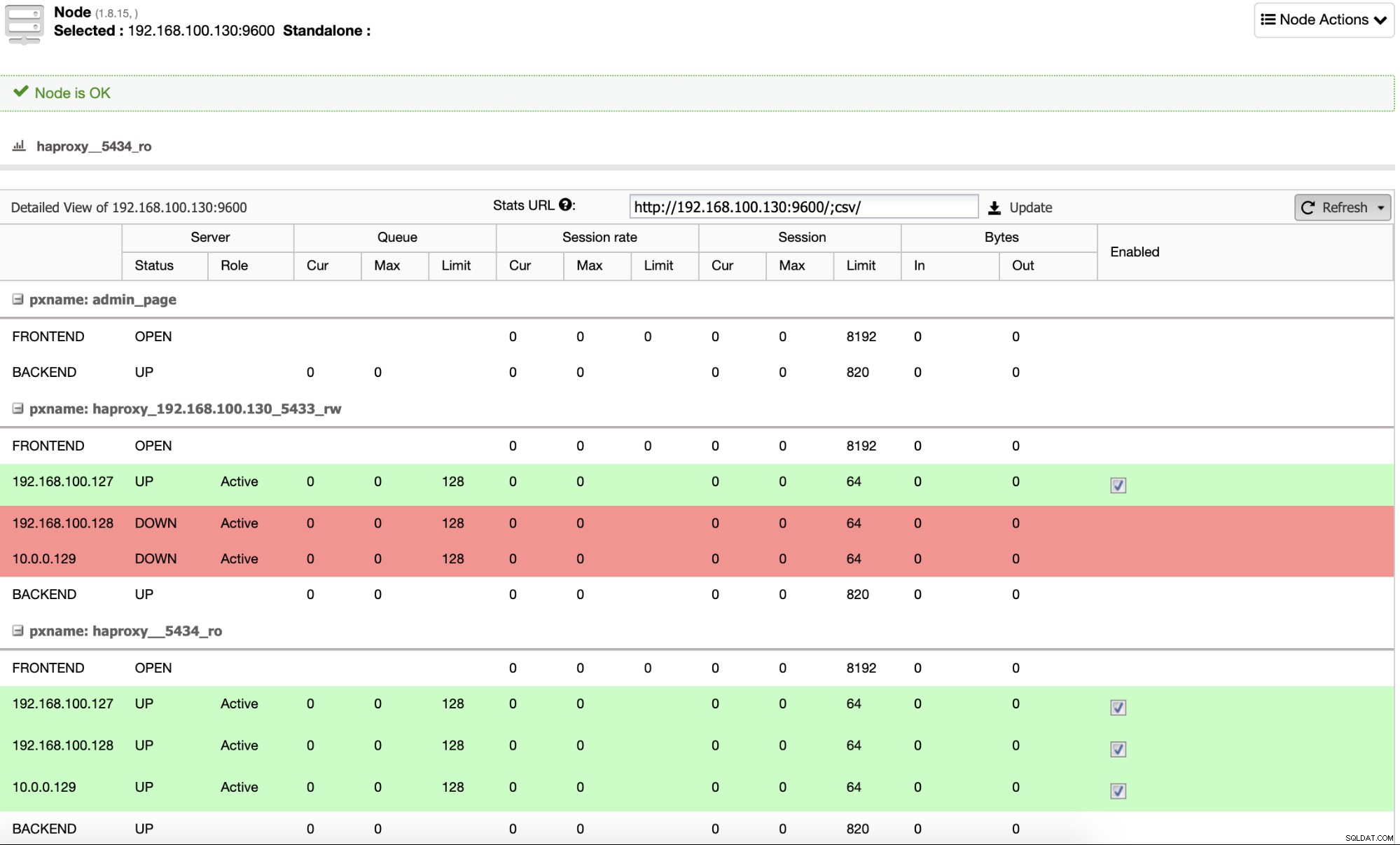
Por padrão, o ClusterControl configura o HAProxy com duas portas diferentes, uma para leitura Write, que será usado para a aplicação ou usuário escrever (e ler) dados, e outro para Read-Only, que será usado para balancear o tráfego de leitura entre todos os nós. Na porta Read-Write, apenas o nó mestre é habilitado, e em caso de falha do mestre, o ClusterControl irá promover o escravo mais avançado a mestre e irá reconfigurar esta porta para desabilitar o mestre antigo e habilitar o novo. Dessa forma, seu aplicativo ainda pode funcionar em caso de falha do banco de dados mestre, pois o tráfego é redirecionado pelo Load Balancer para o nó correto.
Você também pode monitorar seus servidores HAProxy verificando a seção Dashboard.
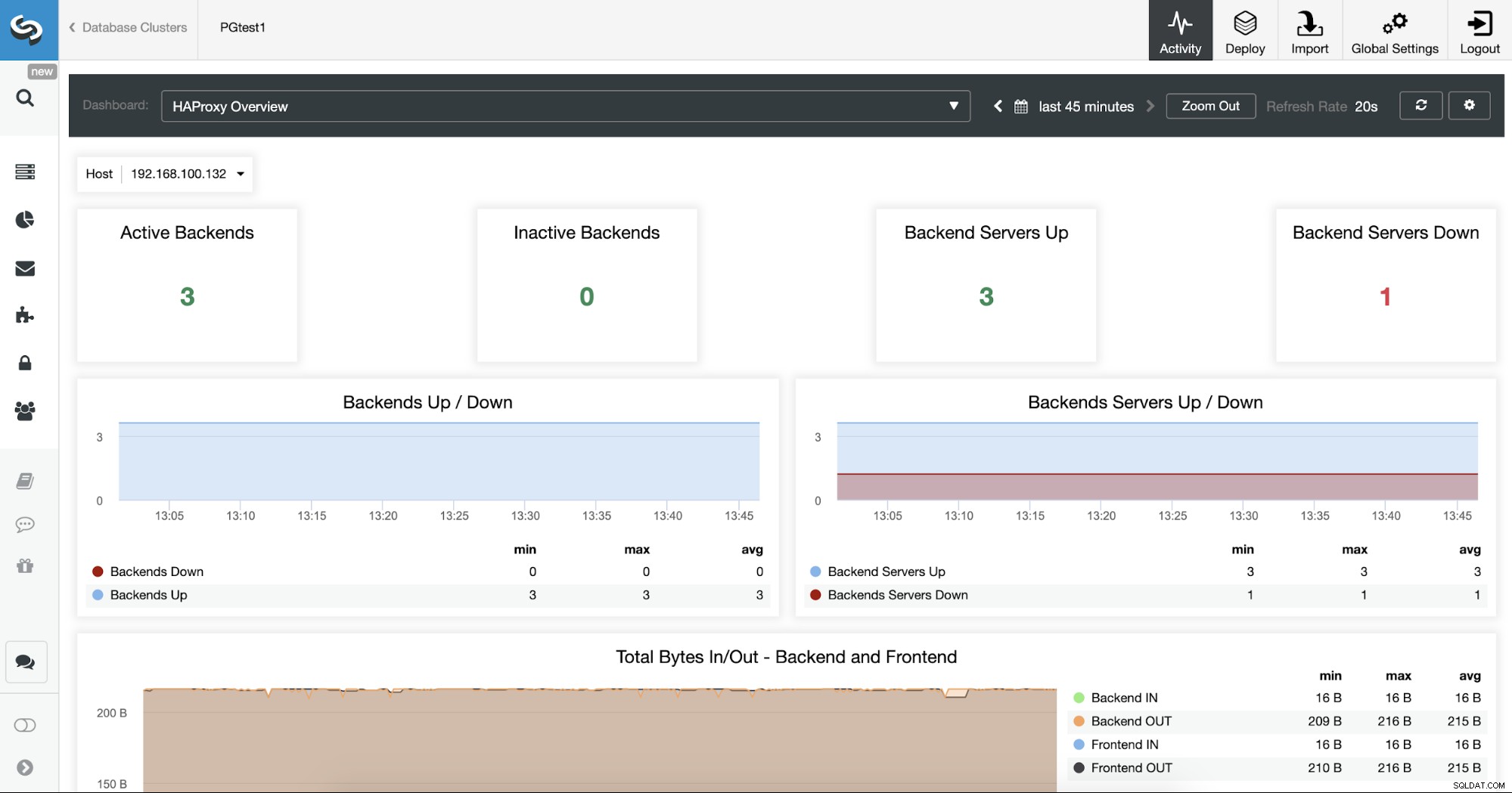
Agora, você pode melhorar seu design de alta disponibilidade adicionando um novo nó HAProxy no datacenter remoto e configurar o serviço Keepalived entre eles. Keepalived permitirá que você use um endereço IP virtual atribuído ao nó do Load Balancer ativo. Se esse nó falhar, esse IP virtual será migrado para o nó HAProxy secundário, portanto, ter esse IP configurado em seu aplicativo permitirá que você mantenha tudo funcionando no caso de um problema do Load Balancer.
Toda essa configuração pode ser realizada usando o ClusterControl.
Conclusão
Seguindo este blog de duas partes, você pode implementar uma configuração de vários datacenters para PostgreSQL com alta disponibilidade e conectividade SSH entre o datacenter, para evitar a complexidade de uma configuração de VPN.
Usando a replicação assíncrona para o nó remoto você evitará qualquer problema relacionado à latência e desempenho da rede, e usando o ClusterControl você terá failover automático (ou manual) em caso de falha (entre outras várias funcionalidades). Essa pode ser a maneira mais simples de alcançar essa topologia e esperamos que seja útil para você.