Introdução
Independentemente da tecnologia de banco de dados, é necessário ter uma configuração de monitoramento, tanto para detectar problemas e agir, ou simplesmente para conhecer o estado atual de nossos sistemas.
Para isso existem diversas ferramentas, pagas e gratuitas. Neste blog vamos focar em um em particular:Nagios Core.
O que é o Nagios Core?
O Nagios Core é um sistema Open Source para monitoramento de hosts, redes e serviços. Permite configurar alertas e possui diferentes estados para eles. Permite a implementação de plugins, desenvolvidos pela comunidade, ou ainda permite configurar nossos próprios scripts de monitoramento.
Como instalar o Nagios?
A documentação oficial mostra como instalar o Nagios Core em sistemas CentOS ou Ubuntu.
Vejamos um exemplo dos passos necessários para a instalação no CentOS 7.
Pacotes necessários
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipFaça o download do Nagios Core, plug-ins do Nagios e NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzAdicionar usuário e grupo do Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheInstalação do Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgPlugin do Nagios e instalação do NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginAdicionamos a seguinte linha ao final do nosso arquivo /usr/local/nagios/etc/objects/command.cfg para usar o NRPE ao verificar nossos servidores:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios começa
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdAcesso à Web
Criamos o usuário para acessar a interface web e podemos entrar no site.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Nagios Web Access
Nagios Web Access Como configurar o Nagios?
Agora que temos nosso Nagios instalado, podemos continuar com a configuração. Para isso devemos ir ao local correspondente à nossa instalação, em nosso exemplo /usr/local/nagios/etc.
Existem vários arquivos de configuração diferentes que você precisará criar ou editar antes de começar a monitorar qualquer coisa.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: O arquivo de configuração CGI contém várias diretivas que afetam a operação dos CGIs. Ele também contém uma referência ao arquivo de configuração principal, para que os CGIs saibam como você configurou o Nagios e onde suas definições de objeto estão armazenadas.
- htpasswd.users: Este arquivo contém os usuários criados para acessar a interface web do Nagios.
- nagios.cfg: O arquivo de configuração principal contém várias diretivas que afetam o funcionamento do daemon do Nagios Core.
- objetos: Quando você instala o Nagios, vários arquivos de configuração de objeto de amostra são colocados aqui. Você pode usar esses arquivos de amostra para ver como a herança de objetos funciona e aprender como definir suas próprias definições de objeto. Objetos são todos os elementos envolvidos na lógica de monitoramento e notificação.
- recurso.cfg: Isso é usado para especificar um arquivo de recurso opcional que pode conter definições de macro. As macros permitem que você faça referência às informações de hosts, serviços e outras fontes em seus comandos.
Dentro dos objetos, podemos encontrar templates, que podem ser usados na criação de novos objetos. Por exemplo, podemos ver que em nosso arquivo /usr/local/nagios/etc/objects/templates.cfg, existe um template chamado linux-server, que será usado para adicionar nossos servidores.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Usando este modelo, nossos hosts herdarão a configuração sem precisar especificá-los um por um em cada servidor que adicionamos.
Também temos comandos, contatos e prazos predefinidos.
Os comandos serão usados pelo Nagios para suas verificações, e é isso que adicionamos dentro do arquivo de configuração de cada servidor para monitorá-lo. Por exemplo, PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Temos a possibilidade de criar contatos ou grupos, e especificar quais alertas quero alcançar para qual pessoa ou grupo.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Para nossas verificações e alertas, podemos configurar em que horas e dias queremos recebê-los. Se temos um serviço que não é crítico, provavelmente não queremos acordar de madrugada, então seria bom alertar apenas no horário de trabalho para evitar isso.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Vamos ver agora como adicionar alertas ao nosso Nagios.
Vamos monitorar nossos servidores PostgreSQL, então primeiro os adicionamos como hosts em nosso diretório de objetos. Vamos criar 3 novos arquivos:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Então devemos adicioná-los ao arquivo nagios.cfg e aqui temos 2 opções.
Adicione nossos hosts (arquivos cfg) um por um usando a variável cfg_file (opção padrão) ou adicione todos os arquivos cfg que temos dentro de um diretório usando a variável cfg_dir.
Adicionaremos os arquivos um a um seguindo a estratégia padrão.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgCom isso temos nossos hosts monitorados. Agora só temos que adicionar quais serviços queremos monitorar. Para isso utilizaremos algumas verificações já definidas (check_ssh e check_ping), e adicionaremos algumas verificações básicas do sistema operacional como carga e espaço em disco, entre outras, utilizando NRPE.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
O que é NRPE?
Executor de plug-in remoto do Nagios. Esta ferramenta nos permite executar plugins Nagios em um host remoto da maneira mais transparente possível.
Para usá-lo, devemos instalar o servidor em cada nó que queremos monitorar, e nosso Nagios se conectará como cliente a cada um deles, executando o(s) plugin(s) correspondente(s).
Como instalar o NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeEm seguida, editamos o arquivo de configuração /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>E reiniciamos o serviço NRPE:
[example@sqldat.com ~]# systemctl restart nrpePodemos testar a conexão executando o seguinte em nosso servidor Nagios:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Como monitorar o PostgreSQL?
Ao monitorar o PostgreSQL, há duas áreas principais a serem consideradas:sistema operacional e bancos de dados.
Para o sistema operacional, o NRPE possui algumas verificações básicas configuradas como espaço em disco e carga, entre outras. Essas verificações podem ser habilitadas muito facilmente da seguinte maneira.
Em nossos nós editamos o arquivo /usr/local/nagios/etc/nrpe.cfg e vamos até onde estão as seguintes linhas:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Os nomes entre colchetes são aqueles que usaremos em nosso servidor Nagios para habilitar essas verificações.
Em nosso Nagios, editamos os arquivos dos 3 nós:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgAdicionamos essas verificações que vimos anteriormente, deixando nossos arquivos da seguinte forma:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}E reiniciamos o serviço nagios:
[example@sqldat.com ~]# systemctl start nagiosNeste ponto, se formos para a seção de serviços na interface web do nosso Nagios, devemos ter algo como o seguinte:
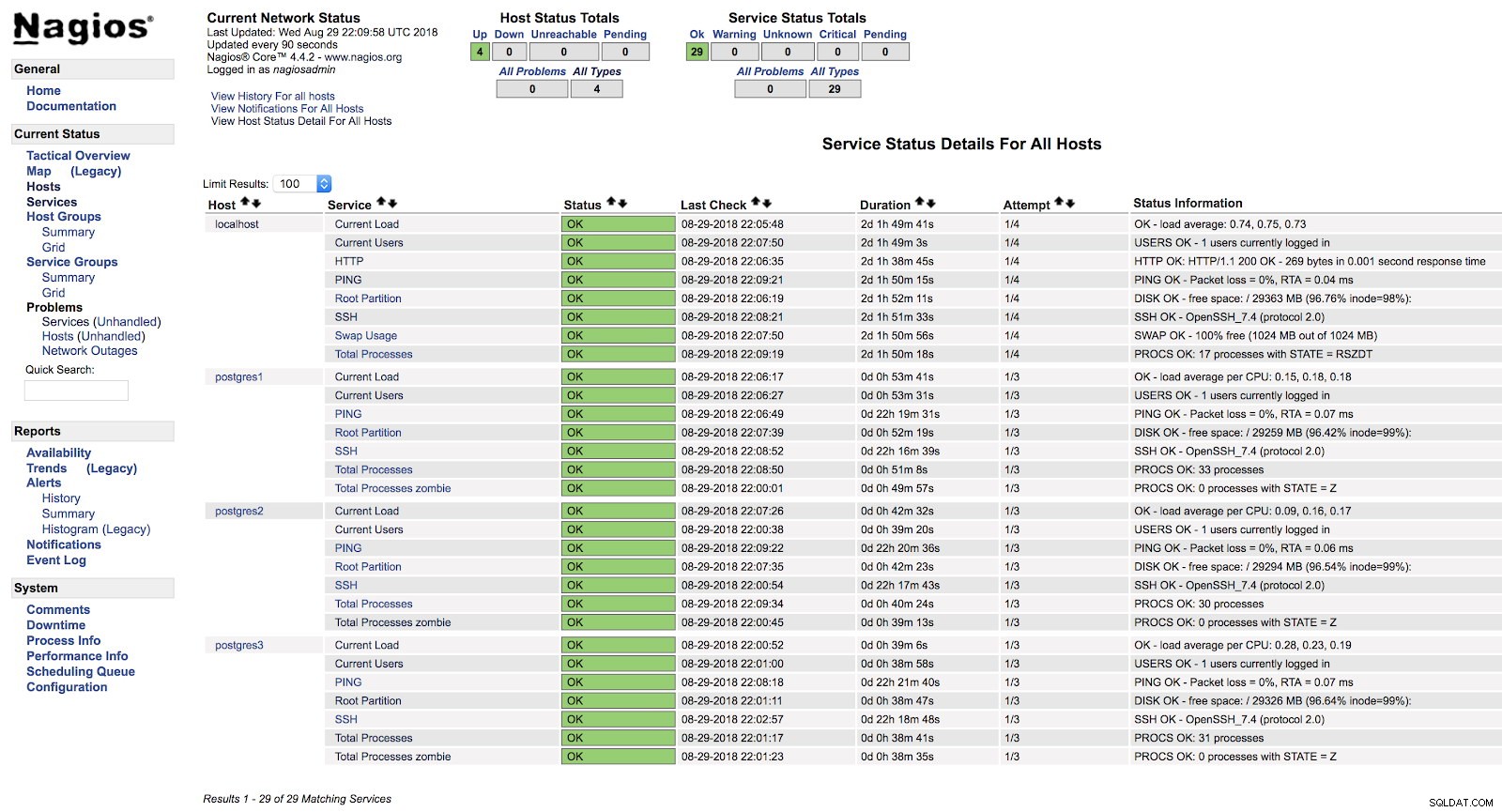 Alertas de host do Nagios
Alertas de host do Nagios Desta forma, estaremos cobrindo as verificações básicas do nosso servidor no nível do sistema operacional.
Temos muitas outras verificações que podemos adicionar e podemos até criar nossas próprias verificações (veremos um exemplo mais adiante).
Agora vamos ver como monitorar nosso mecanismo de banco de dados PostgreSQL usando dois dos principais plugins projetados para esta tarefa.
Check_postgres
Um dos plugins mais populares para verificar o PostgreSQL é o check_postgres do Bucardo.
Vamos ver como instalá-lo e como usá-lo com nosso banco de dados PostgreSQL.
Pacotes obrigatórios
[example@sqldat.com ~]# yum install perl-develInstalação
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksEste último comando cria os links para usar todas as funções desta verificação, como check_postgres_connection, check_postgres_last_vacuum ou check_postgres_replication_slots entre outras.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Adicionamos em nosso arquivo de configuração do NRPE (/usr/local/nagios/etc/nrpe.cfg) a linha para executar a verificação que queremos usar:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100Em nosso exemplo adicionamos 4 verificações básicas para o PostgreSQL. Vamos monitorar Locks, Bloat, Connection e Backends.
No arquivo correspondente ao nosso banco de dados no servidor Nagios (/usr/local/nagios/etc/objects/postgres1.cfg), adicionamos as seguintes entradas:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}E após reiniciar os dois serviços (NRPE e Nagios) em ambos os servidores, podemos ver nossos alertas configurados.
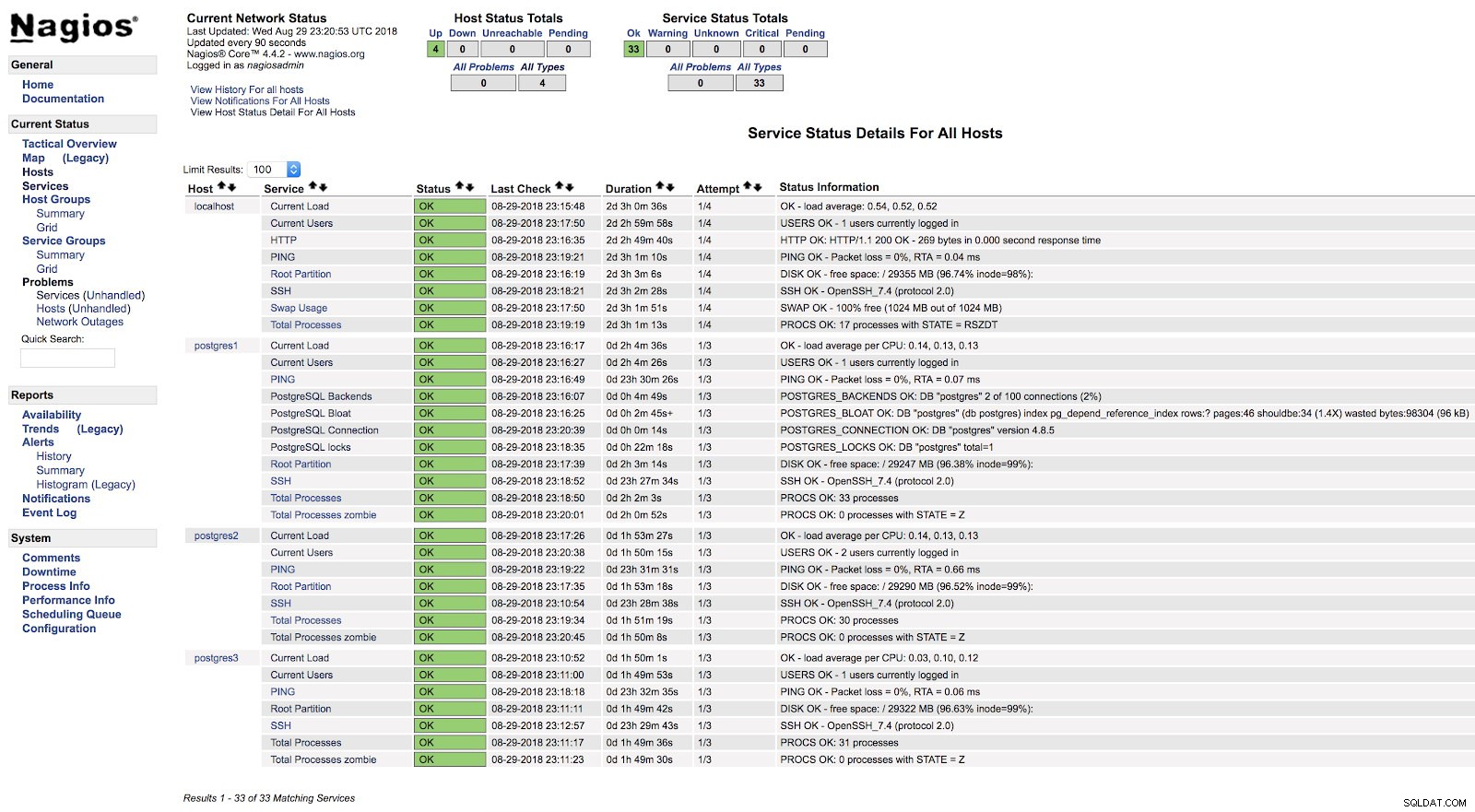 Nagios check_postgres Alertas
Nagios check_postgres Alertas Na documentação oficial do plugin check_postgres, você pode encontrar informações sobre o que mais monitorar e como fazê-lo.
Verificar_pgatividade
Agora é a vez do check_pgactivity, também popular para monitorar nosso banco de dados PostgreSQL.
Instalação
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityAdicionamos em nosso arquivo de configuração do NRPE (/usr/local/nagios/etc/nrpe.cfg) a linha para executar a verificação que queremos usar:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10Em nosso exemplo, adicionaremos 4 verificações básicas para o PostgreSQL. Monitoraremos Backends, Conexão, Índices Inválidos e bloqueios.
No arquivo correspondente ao nosso banco de dados no servidor Nagios (/usr/local/nagios/etc/objects/postgres2.cfg), adicionamos as seguintes entradas:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}E após reiniciar os dois serviços (NRPE e Nagios) em ambos os servidores, podemos ver nossos alertas configurados.
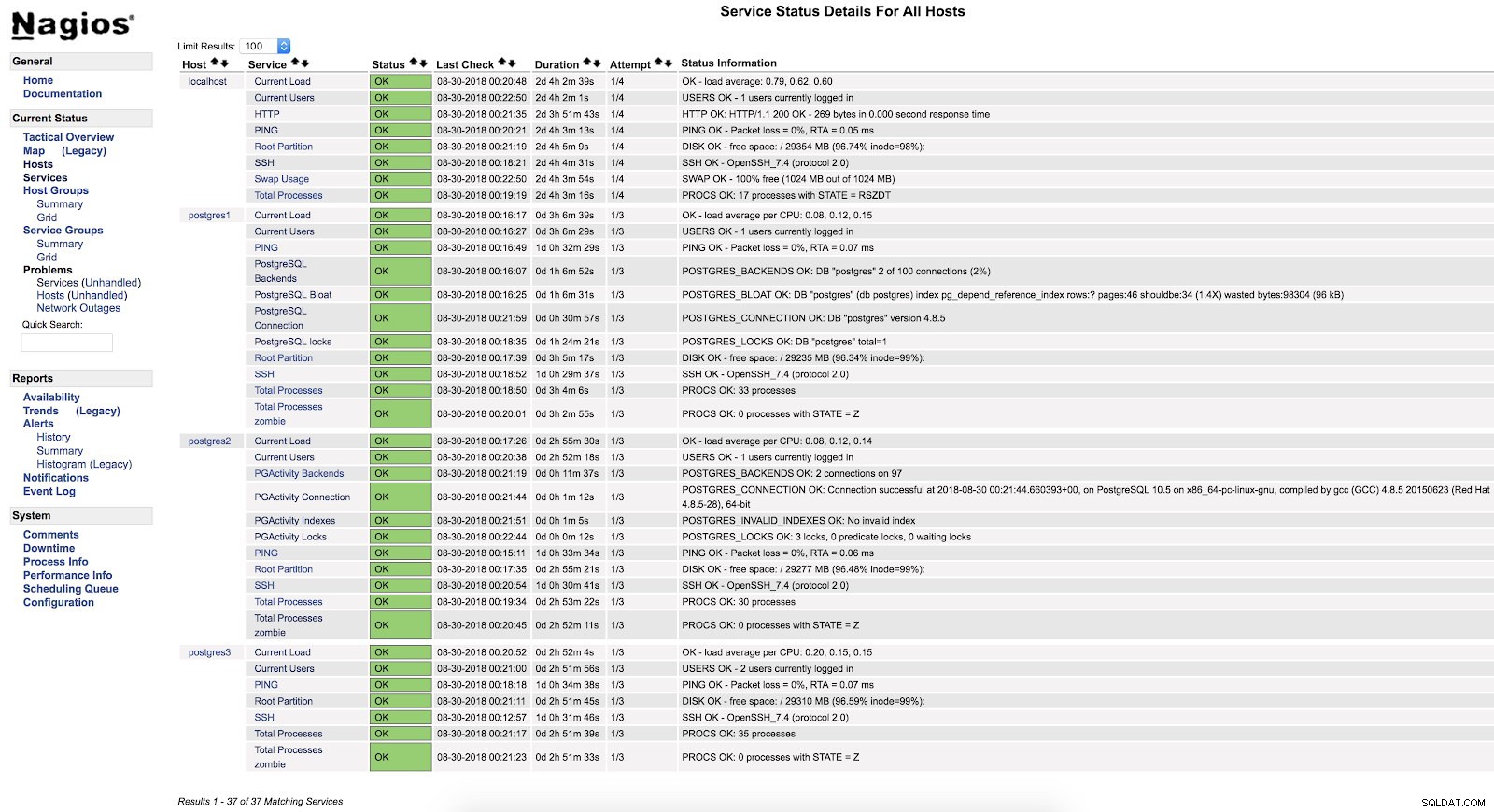 Nagios check_pgactivity Alertas
Nagios check_pgactivity Alertas Verificar registro de erros
Uma das verificações mais importantes, ou a mais importante, é verificar nosso log de erros.
Aqui podemos encontrar diferentes tipos de erros como FATAL ou deadlock, e é um bom ponto de partida para analisar qualquer problema que tenhamos em nosso banco de dados.
Para verificar nosso log de erros, vamos criar nosso próprio script de monitoramento e integrá-lo ao nosso Nagios (este é apenas um exemplo, este script será básico e tem muito espaço para melhorias).
Roteiro
Vamos criar o arquivo /usr/local/nagios/libexec/check_postgres_log.sh em nosso servidor PostgreSQL3.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiO importante do script é criar corretamente as saídas correspondentes a cada estado. Essas saídas são lidas pelo Nagios e cada número corresponde a um estado:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNEm nosso exemplo usaremos apenas 2 estados, OK e CRITICAL, pois estamos interessados apenas em saber se há erros do tipo FATAL em nosso log de erros na hora atual.
O texto que usamos antes de nossa saída será mostrado pela interface web do nosso Nagios, portanto, deve ser o mais claro possível usá-lo como guia para o problema.
Assim que terminarmos nosso script de monitoramento, iremos dar a ele permissões de execução, atribuí-lo ao usuário nagios e adicioná-lo ao nosso servidor de banco de dados NRPE, bem como ao nosso Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Reinicie o NRPE e o Nagios. Então podemos ver nosso check na interface do Nagios:
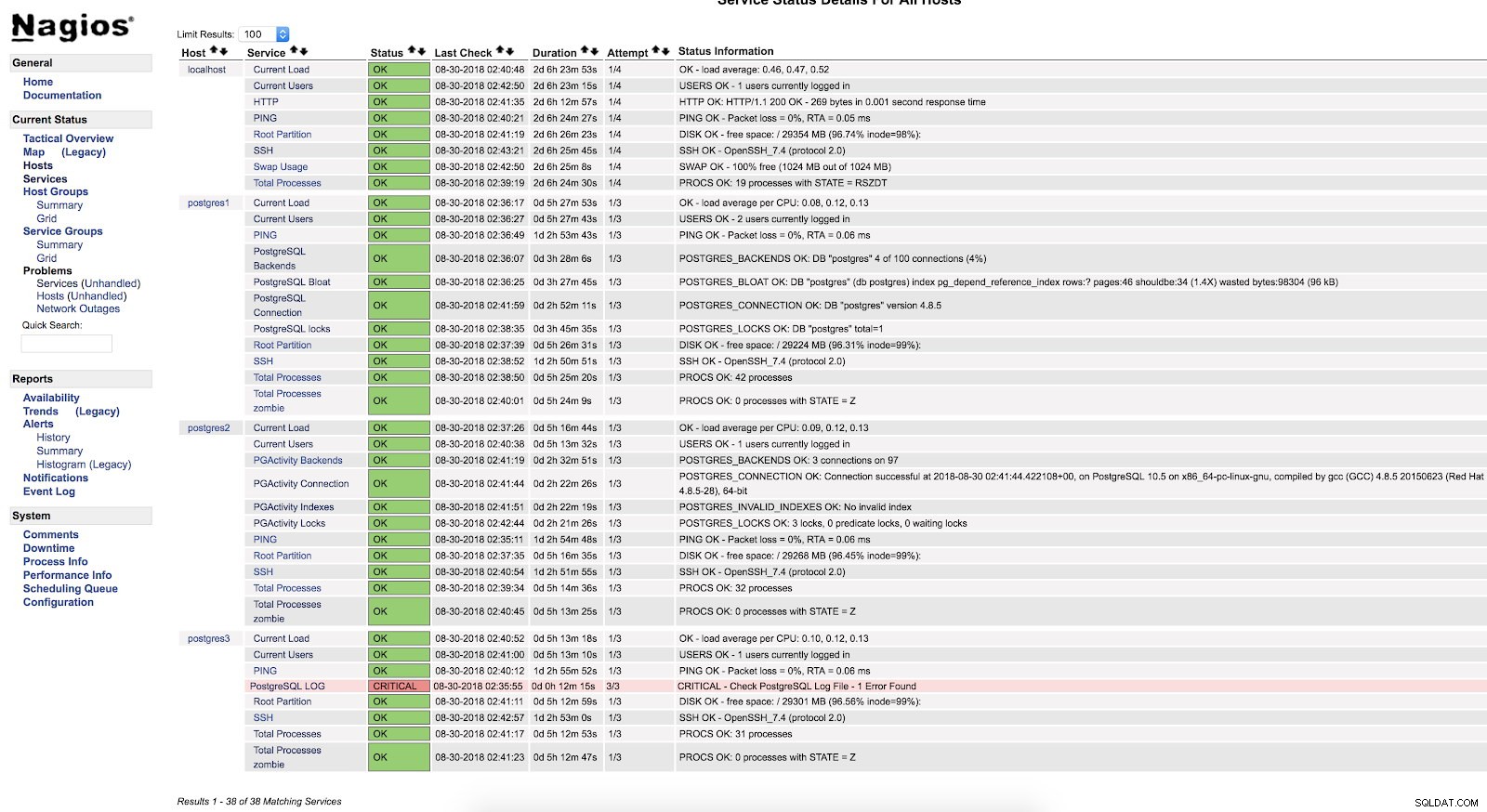 Alertas de script do Nagios
Alertas de script do Nagios Como podemos ver está em estado CRÍTICO, então se formos ao log, podemos ver o seguinte:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Para obter mais informações sobre o que podemos monitorar em nosso banco de dados PostgreSQL, recomendo que você verifique nossos blogs de desempenho e monitoramento ou este webinar de Desempenho do Postgres.
Segurança e desempenho
Ao configurar qualquer monitoramento, seja usando plugins ou nosso próprio script, devemos ter muito cuidado com 2 coisas muito importantes - segurança e desempenho.
Quando atribuímos as permissões necessárias para o monitoramento, devemos ser o mais restritivos possível, limitando o acesso apenas localmente ou do nosso servidor de monitoramento, utilizando chaves seguras, criptografando o tráfego, permitindo a conexão ao mínimo necessário para que o monitoramento funcione.
Com relação ao desempenho, o monitoramento é necessário, mas também é necessário usá-lo com segurança para nossos sistemas.
Devemos ter cuidado para não gerar acesso ao disco excessivamente alto ou executar consultas que afetem negativamente o desempenho de nosso banco de dados.
Se tivermos muitas transações por segundo gerando gigabytes de logs, e continuarmos procurando erros continuamente, provavelmente não é o melhor para nosso banco de dados. Portanto, devemos manter um equilíbrio entre o que monitoramos, com que frequência e o impacto no desempenho.
Conclusão
Existem várias maneiras de implementar o monitoramento ou configurá-lo. Podemos fazê-lo tão complexo ou tão simples quanto quisermos. O objetivo deste blog foi apresentar a você o monitoramento do PostgreSQL utilizando uma das ferramentas open source mais utilizadas. Vimos também que a configuração é muito flexível e pode ser adaptada a diferentes necessidades.
E não se esqueça que podemos sempre contar com a comunidade, por isso deixo alguns links que poderão ser de grande ajuda.
Fórum de suporte:https://support.nagios.com/forum/
Problemas conhecidos:https://github.com/NagiosEnterprises/nagioscore/issues
Plugins do Nagios:https://exchange.nagios.org/directory/Plugins
Plugin Nagios para ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol