Como administrador de banco de dados PostgreSQL, há as expectativas diárias de verificar backups, aplicar alterações de DDL, garantir que os logs não tenham nenhum ERRO de quebra de jogo e responder a chamadas em pânico de desenvolvedores cujos relatórios estão sendo executados duas vezes mais do que o normal e eles ter uma reunião em dez minutos.
Mesmo com uma boa compreensão da saúde dos bancos de dados gerenciados, sempre haverá novos casos e novos problemas surgindo relacionados ao desempenho e como o banco de dados “se sente”. Seja um e-mail em pânico ou um ticket aberto para “o banco de dados parece lento”, essa tarefa comum geralmente pode ser seguida com algumas etapas para verificar se há ou não um problema com o PostgreSQL e qual pode ser esse problema.
Este não é um guia exaustivo, nem as etapas precisam ser feitas em qualquer ordem específica. Mas é um conjunto de etapas iniciais que podem ser tomadas para ajudar a encontrar os infratores comuns rapidamente, bem como obter novos insights sobre qual pode ser o problema. Um desenvolvedor pode saber como o aplicativo age e responde, mas o Administrador de Banco de Dados sabe como o banco de dados age e responde ao aplicativo e, juntos, o problema pode ser encontrado.
OBSERVAÇÃO: As consultas a serem executadas devem ser feitas como um superusuário, como ‘postgres’ ou qualquer usuário de banco de dados com permissões de superusuário. Usuários limitados serão negados ou terão dados omitidos.
Etapa 0 - Coleta de informações
Obtenha o máximo de informações possível de quem diz que o banco de dados parece lento; consultas específicas, aplicativos conectados, prazos de lentidão de desempenho, etc. Quanto mais informações eles fornecerem, mais fácil será encontrar o problema.
Etapa 1 - Verifique pg_stat_activity
A solicitação pode vir de muitas formas diferentes, mas se “lentidão” for o problema geral, verificar pg_stat_activity é o primeiro passo para entender exatamente o que está acontecendo. A visão pg_stat_activity (a documentação para cada coluna nesta visão pode ser encontrada aqui) contém uma linha para cada processo/conexão do servidor ao banco de dados de um cliente. Há um punhado de informações úteis nessa exibição que podem ajudar.
OBSERVAÇÃO: pg_stat_activity é conhecido por mudar a estrutura ao longo do tempo, refinando os dados que apresenta. A compreensão das próprias colunas ajudará a criar consultas dinamicamente conforme necessário no futuro.
As colunas notáveis em pg_stat_activity são:
- consulta:uma coluna de texto que mostra a consulta que está sendo executada no momento, aguardando para ser executada ou foi executada pela última vez (dependendo do estado). Isso pode ajudar a identificar quais consultas um desenvolvedor pode estar relatando que estão sendo executadas lentamente.
- client_addr:o endereço IP do qual esta conexão e consulta foram originadas. Se vazio (ou Nulo), originou-se de localhost.
- backend_start, xact_start, query_start:esses três fornecem um carimbo de data/hora de quando cada um foi iniciado, respectivamente. Backend_start representa quando a conexão com o banco de dados foi estabelecida, xact_start é quando a transação atual foi iniciada e query_start é quando a consulta atual (ou última) foi iniciada.
- state:O estado da conexão com o banco de dados. Ativo significa que está executando uma consulta no momento, 'ocioso' significa que está aguardando mais entradas do cliente, 'ocioso na transação' significa que está aguardando mais entradas do cliente enquanto mantém uma transação aberta. (Existem outros, porém sua probabilidade é rara, consulte a documentação para mais informações).
- datname:o nome do banco de dados ao qual a conexão está conectada no momento. Em vários clusters de banco de dados, isso pode ajudar a isolar conexões problemáticas.
- wait_event_type e wait_event:essas colunas serão nulas quando uma consulta não estiver esperando, mas se estiver esperando, elas conterão informações sobre por que a consulta está esperando, e explorar pg_locks pode identificar o que está esperando. (O PostgreSQL 9.5 e anteriores têm apenas uma coluna booleana chamada 'waiting', true se estiver aguardando, false se não estiver.
1.1. A consulta está esperando/bloqueada?
Se houver uma consulta específica ou consultas "lentas" ou "travadas", verifique se elas estão aguardando a conclusão de outra consulta. Devido ao bloqueio de relação, outras consultas podem bloquear uma tabela e não permitir que outras consultas acessem ou alterem dados até que essa consulta ou transação seja concluída.
PostgreSQL 9.5 e anteriores:
SELECT * FROM pg_stat_activity WHERE waiting = TRUE;PostgreSQL 9.6:
SELECT * FROM pg_stat_activity WHERE wait_event IS NOT NULL;PostgreSQL 10 e posterior (?):
SELECT * FROM pg_stat_activity WHERE wait_event IS NOT NULL AND backend_type = 'client backend';Os resultados dessa consulta mostrarão todas as conexões que estão aguardando outra conexão para liberar bloqueios em uma relação necessária.
Se a consulta estiver bloqueada por outra conexão, existem algumas maneiras de descobrir exatamente quais são. No PostgreSQL 9.6 e posterior, a função pg_blocking_pids() permite a entrada de um ID de processo que está sendo bloqueado e retornará um array de IDs de processo responsáveis por bloqueá-lo.
PostgreSQL 9.6 e posterior:
SELECT * FROM pg_stat_activity
WHERE pid IN (SELECT pg_blocking_pids(<pid of blocked query>));PostgreSQL 9.5 e anteriores:
SELECT blocked_locks.pid AS blocked_pid,
blocked_activity.usename AS blocked_user,
blocking_locks.pid AS blocking_pid,
blocking_activity.usename AS blocking_user,
blocked_activity.query AS blocked_statement,
blocking_activity.query AS current_statement_in_blocking_process
FROM pg_catalog.pg_locks blocked_locks
JOIN pg_catalog.pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid
JOIN pg_catalog.pg_locks blocking_locks
ON blocking_locks.locktype = blocked_locks.locktype
AND blocking_locks.DATABASE IS NOT DISTINCT FROM blocked_locks.DATABASE
AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation
AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page
AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple
AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid
AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid
AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid
AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid
AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid
AND blocking_locks.pid != blocked_locks.pid
JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid
WHERE NOT blocked_locks.GRANTED;(Disponível no PostgreSQL Wiki).
Essas consultas apontarão para o que está bloqueando um PID específico fornecido. Com isso, pode-se tomar a decisão de matar a consulta ou conexão de bloqueio ou deixá-la em execução.
Etapa 2 - Se as consultas estão em execução, por que estão demorando tanto?
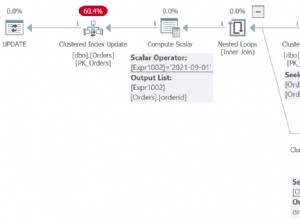
2.1. O planejador está executando consultas com eficiência?
Se uma consulta (ou conjunto de consultas) em questão tiver o status 'ativo', ela está realmente em execução. Se a consulta inteira não estiver disponível em pg_stat_activity, busque-a nos desenvolvedores ou no log do postgresql e comece a explorar o planejador de consultas.
EXPLAIN SELECT * FROM postgres_stats.table_stats t JOIN hosts h ON (t.host_id = h.host_id) WHERE logged_date >= '2018-02-01' AND logged_date < '2018-02-04' AND t.india_romeo = 569;
Nested Loop (cost=0.280..1328182.030 rows=2127135 width=335)
-> Index Scan using six on victor_oscar echo (cost=0.280..8.290 rows=1 width=71)
Index Cond: (india_romeo = 569)
-> Append (cost=0.000..1306902.390 rows=2127135 width=264)
-> Seq Scan on india_echo romeo (cost=0.000..0.000 rows=1 width=264)
Filter: ((logged_date >= '2018-02-01'::timestamp with time zone) AND (logged_date < '2018-02-04'::timestamp with time zone) AND (india_romeo = 569))
-> Seq Scan on juliet victor_echo (cost=0.000..437153.700 rows=711789 width=264)
Filter: ((logged_date >= '2018-02-01'::timestamp with time zone) AND (logged_date < '2018-02-04'::timestamp with time zone) AND (india_romeo = 569))
-> Seq Scan on india_papa quebec_bravo (cost=0.000..434936.960 rows=700197 width=264)
Filter: ((logged_date >= '2018-02-01'::timestamp with time zone) AND (logged_date < '2018-02-04'::timestamp with time zone) AND (india_romeo = 569))
-> Seq Scan on two oscar (cost=0.000..434811.720 rows=715148 width=264)
Filter: ((logged_date >= '2018-02-01'::timestamp with time zone) AND (logged_date < '2018-02-04'::timestamp with time zone) AND (india_romeo = 569))Este exemplo mostra um plano de consulta para uma junção de duas tabelas que também atinge uma tabela particionada. Estamos procurando por qualquer coisa que possa tornar a consulta lenta e, neste caso, o planejador está fazendo várias varreduras sequenciais em partições, sugerindo que estão faltando índices. Adicionar índices a essas tabelas para a coluna 'india_romeo' melhorará instantaneamente essa consulta.
O que se deve procurar são varreduras sequenciais, loops aninhados, classificação cara, etc. Compreender o planejador de consultas é crucial para garantir que as consultas estejam funcionando da melhor maneira possível. A documentação oficial pode ser lida para obter mais informações aqui.
2.2. As mesas envolvidas estão inchadas?
Se as consultas ainda estiverem lentas sem que o planejador de consultas aponte para algo óbvio, é hora de verificar a integridade das tabelas envolvidas. Eles são muito grandes? Estão inchados?
SELECT n_live_tup, n_dead_tup from pg_stat_user_tables where relname = ‘mytable’;
n_live_tup | n_dead_tup
------------+------------
15677 | 8275431
(1 row)Aqui vemos que há muitas vezes mais linhas mortas do que linhas ativas, o que significa que para encontrar as linhas corretas, o mecanismo deve filtrar dados que nem são relevantes para encontrar dados reais. Um vácuo / vácuo completo nesta mesa aumentará significativamente o desempenho.
Etapa 3 - Verifique os registros
Se o problema ainda não puder ser encontrado, verifique os logs em busca de pistas.
Mensagens FATAL/ERRO:
Procure mensagens que possam estar causando problemas, como impasses ou longos tempos de espera para obter um bloqueio.
Pontos de verificação
Espero que log_checkpoints esteja ativado, o que gravará informações de ponto de verificação nos logs. Existem dois tipos de pontos de verificação, cronometrados e solicitados (forçados). Se os pontos de verificação estiverem sendo forçados, os buffers sujos na memória devem ser gravados no disco antes de processar mais consultas, o que pode dar ao sistema de banco de dados uma sensação geral de “lentidão”. Aumentar checkpoint_segments ou max_wal_size (dependendo da versão do banco de dados) dará ao checkpointer mais espaço para trabalhar, bem como ajudará o gravador em segundo plano a suportar parte da carga de gravação.
Etapa 4 - Qual é a integridade do sistema host?
Se não houver pistas no próprio banco de dados, talvez o próprio host esteja sobrecarregado ou com problemas. Qualquer coisa, desde um canal de E/S sobrecarregado para o disco, estouro de memória para swap ou até mesmo uma unidade com falha, nenhum desses problemas seria aparente com qualquer coisa que analisamos antes. Supondo que o banco de dados esteja sendo executado em um sistema operacional baseado em *nix, aqui estão algumas coisas que podem ajudar.
4.1. Carga do sistema
Usando 'top', veja a média de carga para o host. Se o número estiver se aproximando ou excedendo o número de núcleos no sistema, podem ser simplesmente muitas conexões simultâneas atingindo o banco de dados, levando-o a um rastreamento para recuperar o atraso.
load average: 3.43, 5.25, 4.854.2. Memória do sistema e SWAP
Usando 'grátis', verifique se o SWAP foi usado. O estouro de memória para SWAP em um ambiente de banco de dados PostgreSQL é extremamente ruim para o desempenho, e muitos DBAs até eliminam o SWAP dos hosts de banco de dados, pois um erro de 'falta de memória' é mais preferível do que um sistema lento para muitos.
Se SWAP estiver sendo usado, uma reinicialização do sistema irá limpá-lo, e aumentar a memória total do sistema ou reconfigurar o uso de memória para PostgreSQL (como diminuir shared_buffers ou work_mem) pode estar em ordem.
[example@sqldat.com ~]$ free -m
total used free shared buff/cache available
Mem: 7986 225 1297 12 6462 7473
Swap: 7987 2048 59394.3. Acesso ao disco
O PostgreSQL tenta fazer muito de seu trabalho na memória e espalhar a escrita no disco para minimizar os gargalos, mas em um sistema sobrecarregado com escrita pesada, é facilmente possível ver leituras e escritas pesadas fazendo com que todo o sistema fique lento à medida que ele alcança sobre as demandas. Discos mais rápidos, mais discos e canais de E/S são algumas maneiras de aumentar a quantidade de trabalho que pode ser feito.
Ferramentas como 'iostat' ou 'iotop' podem ajudar a identificar se há um gargalo no disco e de onde ele pode estar vindo.
4.4. Verifique os logs
Se tudo mais falhar, ou mesmo se não, os logs devem sempre ser verificados para ver se o sistema está relatando algo que não esteja certo. Já discutimos a verificação do postgresql.logs, mas os logs do sistema podem fornecer informações sobre problemas como falha de disco, falha de memória, problemas de rede, etc. de saúde perfeita pode ajudar a encontrar esses problemas.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Etapa 5 - Algo ainda não faz sentido?
Mesmo os administradores mais experientes encontrarão algo novo que não faz sentido. É aí que a comunidade global do PostgreSQL pode entrar para ajudar. Assim como na etapa 0, quanto mais informações claras forem fornecidas à comunidade, mais fácil será a ajuda.
5.1. Listas de discussão do PostgreSQL
Como o PostgreSQL é desenvolvido e gerenciado pela comunidade de código aberto, existem milhares de pessoas que conversam nas listas de discussão para discutir inúmeros tópicos, incluindo recursos, erros e problemas de desempenho. As listas de discussão podem ser encontradas aqui, sendo pgsql-admin e pgsql-performance os mais importantes para procurar ajuda com problemas de desempenho.
5.2. IRC
O Freenode hospeda vários canais PostgreSQL com desenvolvedores e administradores em todo o mundo, e não é difícil encontrar uma pessoa útil para rastrear de onde os problemas podem estar vindo. Mais informações podem ser encontradas na página do PostgreSQL IRC.