Gerenciar uma instalação do PostgreSQL envolve inspeção e controle sobre uma ampla gama de aspectos na pilha de software/infraestrutura na qual o PostgreSQL é executado. Isso deve abranger:
- Ajuste do aplicativo em relação ao uso/transações/conexões do banco de dados
- Código do banco de dados (consultas, funções)
- Sistema de banco de dados (desempenho, HA, backups)
- Hardware/Infraestrutura (discos, CPU/memória)
O núcleo do PostgreSQL fornece a camada de banco de dados na qual confiamos que nossos dados sejam armazenados, processados e servidos. Também fornece toda a tecnologia para ter um sistema verdadeiramente moderno, eficiente, confiável e seguro. Mas muitas vezes essa tecnologia não está disponível como um produto de classe empresarial refinado e pronto para uso na distribuição central do PostgreSQL. Em vez disso, existem muitos produtos/soluções da comunidade PostgreSQL ou ofertas comerciais que atendem a essas necessidades. Essas soluções vêm como refinamentos amigáveis para as tecnologias centrais, ou extensões das tecnologias centrais ou até mesmo como integração entre os componentes do PostgreSQL e outros componentes do sistema. Em nosso blog anterior intitulado Dez dicas para entrar em produção com o PostgreSQL, analisamos algumas dessas ferramentas que podem ajudar a gerenciar uma instalação do PostgreSQL em produção. Neste blog vamos explorar com mais detalhes os aspectos que devem ser abordados ao gerenciar uma instalação do PostgreSQL em produção e as ferramentas mais utilizadas para esse fim. Abordaremos os seguintes tópicos:
- Implantação
- Gerenciamento
- Escalonamento
- Monitoramento
Implantação
Antigamente, as pessoas costumavam baixar e compilar o PostgreSQL manualmente e depois configurar os parâmetros de tempo de execução e o controle de acesso do usuário. Ainda existem alguns casos em que isso pode ser necessário, mas à medida que os sistemas amadureceram e começaram a crescer, surgiu a necessidade de formas mais padronizadas de implantar e gerenciar o Postgresql. A maioria dos sistemas operacionais fornece pacotes para instalar, implantar e gerenciar clusters PostgreSQL. O Debian padronizou seu próprio layout de sistema suportando muitas versões do Postgresql e muitos clusters por versão ao mesmo tempo. O pacote debian postgresql-common fornece as ferramentas necessárias. Por exemplo, para criar um novo cluster (chamado i18n_cluster) para o PostgreSQL versão 10 no Debian, podemos fazê-lo dando os seguintes comandos:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsEm seguida, atualize o systemd:
$ sudo systemctl daemon-reloade finalmente inicie e use o novo cluster:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(observe que o Debian lida com diferentes clusters pelo uso de diferentes portas 5432, 5433 e assim por diante)
À medida que cresce a necessidade de implantações mais automatizadas e massivas, mais e mais instalações usam ferramentas de automação como Ansible, Chef e Puppet. Além da automação e reprodutibilidade das implantações, as ferramentas de automação são ótimas porque são uma boa maneira de documentar a implantação e a configuração de um cluster. Por outro lado, a automação evoluiu para se tornar um grande campo por conta própria, exigindo pessoas qualificadas para escrever, gerenciar e executar scripts automatizados. Mais informações sobre o provisionamento do PostgreSQL podem ser encontradas neste blog:Torne-se um DBA do PostgreSQL:Provisioning and Deployment.
Gerenciamento
Gerenciar um sistema ativo envolve tarefas como:agendar backups e monitorar seu status, recuperação de desastres, gerenciamento de configuração, gerenciamento de alta disponibilidade e tratamento automático de failover. O backup de um cluster Postgresql pode ser feito de várias maneiras. Ferramentas de baixo nível:
- pg_dump tradicional (backup lógico)
- backups no nível do sistema de arquivos (backup físico)
- pg_basebackup (backup físico)
Ou nível superior:
- Barman
- PgBackRest
Cada uma dessas maneiras abrange diferentes casos de uso e cenários de recuperação e variam em complexidade. O backup do PostgreSQL está intimamente relacionado às noções de arquivamento e replicação de PITR, WAL. Ao longo dos anos, o procedimento de fazer, testar e finalmente (dedos cruzados!) usar backups com PostgreSQL evoluiu para ser uma tarefa complexa. Pode-se encontrar uma boa visão geral das soluções de backup para PostgreSQL neste blog:Top Backup Tools for PostgreSQL.
Em relação à alta disponibilidade e failover automático, o mínimo que uma instalação deve ter para implementar isso é:
- Um trabalho primário
- Um hot standby aceitando WAL transmitido do primário
- No caso de falha no primário, um método para informar ao primário que ele não é mais o primário (às vezes chamado de STONITH)
- Um mecanismo de pulsação para verificar a conectividade entre os dois servidores e a integridade do servidor principal
- Um método para realizar o failover (por exemplo, por meio da promoção pg_ctl ou arquivo de acionamento)
- Um procedimento automatizado para recriar o primário antigo como um novo standby:uma vez detectada a interrupção ou falha no primário, um standby deve ser promovido como o novo primário. O antigo primário não é mais válido ou utilizável. Portanto, o sistema deve ter uma maneira de lidar com esse estado entre o failover e a recriação do servidor primário antigo como o novo em espera. Esse estado é chamado de estado degenerado, e o PostgreSQL fornece uma ferramenta chamada pg_rewind para acelerar o processo de trazer o antigo primário de volta ao estado sincronizável do novo primário.
- Um método para fazer trocas sob demanda/planejadas
Uma ferramenta amplamente utilizada que lida com todos os itens acima é Repmgr. Descreveremos a configuração mínima que permitirá uma transição bem-sucedida. Começamos com um PostgreSQL 10.4 primário funcionando no FreeBSD 11.1, construído e instalado manualmente, e o repmgr 4.0 também construído e instalado manualmente para esta versão (10.4). Usaremos dois hosts chamados fbsd (192.168.1.80) e fbsdclone (192.168.1.81) com versões idênticas do PostgreSQL e repmgr. No primário (inicialmente fbsd , 192.168.1.80) garantimos que os seguintes parâmetros do PostgreSQL estejam configurados:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Em seguida, criamos o usuário repmgr (como superusuário) e o banco de dados:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgre configure o controle de acesso baseado em host em pg_hba.conf colocando as seguintes linhas no topo:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustGarantimos que configuramos o login sem senha para o usuário repmgr em todos os nós do cluster, em nosso caso fbsd e fbsdclone, configurando as chaves_autorizadas em .ssh e compartilhando .ssh. Em seguida, criamos repmrg.conf no primário como:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Em seguida, registramos o primário:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredE verifique o status do cluster:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Agora trabalhamos no modo de espera configurando o repmgr.conf da seguinte forma:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Também nos certificamos de que o diretório de dados especificado apenas na linha acima exista, esteja vazio e tenha as permissões corretas:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataAgora temos que clonar para o nosso novo modo de espera:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"E inicie o modo de espera:
example@sqldat.com:~ % pg_ctl -D data startNeste ponto, a replicação deve estar funcionando conforme o esperado, verifique isso consultando pg_stat_replication (fbsd) e pg_stat_wal_receiver (fbsdclone). O próximo passo é registrar o standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerAgora podemos obter o status do cluster no standly ou no primário e verificar se o standby está registrado:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Agora vamos supor que desejamos realizar uma alternância manual programada em ordem, por exemplo, para fazer algum trabalho de administração no nó fbsd. No nó de espera, executamos o seguinte comando:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyA transição foi executada com sucesso! Vamos ver o que o cluster show dá:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Os dois servidores trocaram funções! Repmgr fornece o daemon repmgrd que fornece monitoramento, failover automático, bem como notificações/alertas. Combinando repmgrd com pgbouncer, é possível implementar a atualização automática das informações de conexão do banco de dados, fornecendo cerca para o primário com falha (evitando que o nó com falha seja usado pelo aplicativo), além de fornecer um tempo de inatividade mínimo para o aplicativo. Em esquemas mais complexos, outra ideia é combinar Keepalived com HAProxy em cima de pgbouncer e repmgr, para obter:
- balanceamento de carga (escalonamento)
- alta disponibilidade
Observe que o ClusterControl também gerencia o failover das configurações de replicação do PostgreSQL e integra o HAProxy e o VirtualIP para redirecionar automaticamente as conexões do cliente para o mestre de trabalho. Mais informações podem ser encontradas neste whitepaper sobre Automação do PostgreSQL.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Escalonamento
A partir do PostgreSQL 10 (e 11) ainda não há como ter replicação multi-mestre, pelo menos não a partir do núcleo do PostgreSQL. Isso significa que apenas a atividade select (somente leitura) pode ser ampliada. O dimensionamento no PostgreSQL é obtido adicionando mais hot standbys, fornecendo assim mais recursos para atividades somente leitura. Com repmgr é fácil adicionar um novo modo de espera como vimos anteriormente via clone em espera e registro em espera comandos. Standbys adicionados (ou removidos) devem ser informados à configuração do balanceador de carga. O HAProxy, como mencionado acima no tópico de gerenciamento, é um balanceador de carga popular para PostgreSQL. Geralmente é acoplado ao Keepalived, que fornece IP virtual via VRRP. Uma boa visão geral do uso de HAProxy e Keepalived junto com o PostgreSQL pode ser encontrada neste artigo:PostgreSQL Load Balancing Using HAProxy &Keepalived.
Monitoramento
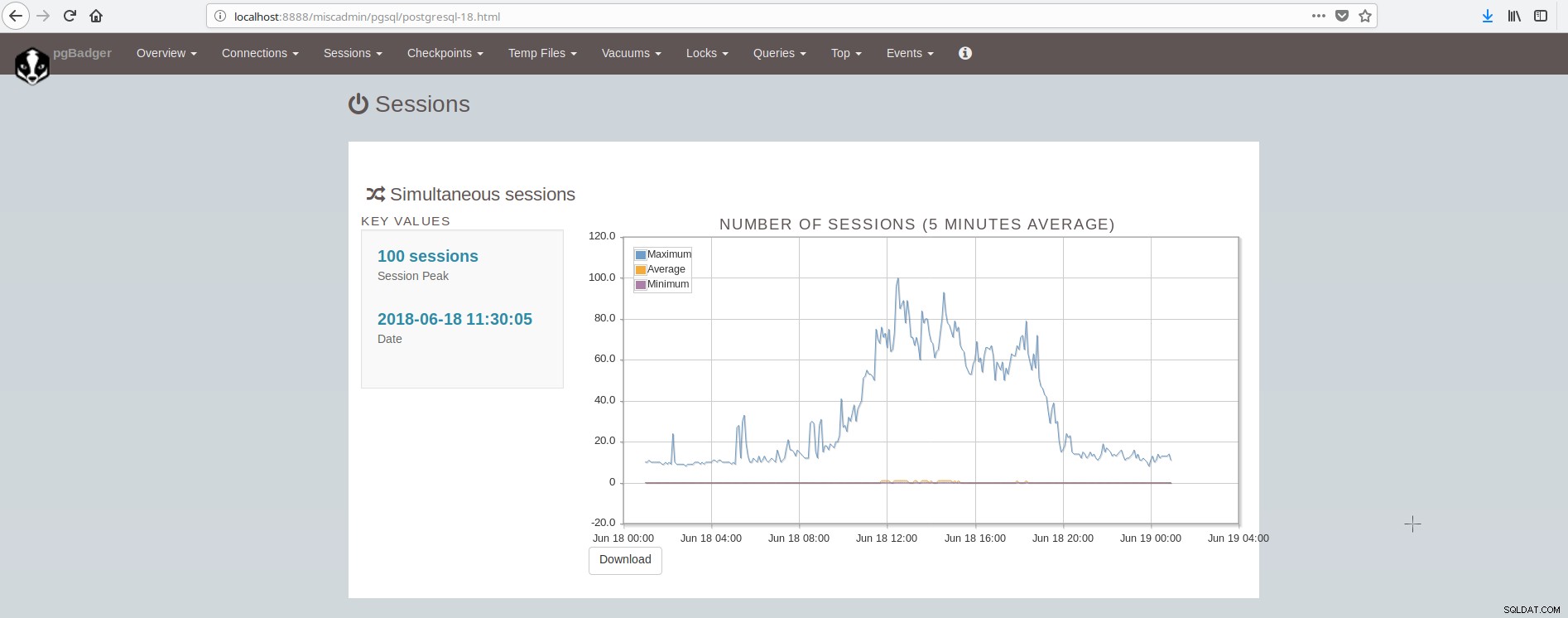
Uma visão geral do que monitorar no PostgreSQL pode ser encontrada neste artigo:Principais coisas para monitorar no PostgreSQL - Analisando sua carga de trabalho. Existem muitas ferramentas que podem fornecer monitoramento do sistema e do postgresql por meio de plugins. Algumas ferramentas cobrem a área de apresentação de gráficos de valores históricos (munin), outras cobrem a área de monitoramento de dados ao vivo e fornecimento de alertas ao vivo (nagios), enquanto algumas ferramentas cobrem ambas as áreas (zabbix). Uma lista dessas ferramentas para PostgreSQL pode ser encontrada aqui:https://wiki.postgresql.org/wiki/Monitoring. Uma ferramenta popular para monitoramento offline (baseado em arquivo de log) é o pgBadger. pgBadger é um script Perl que funciona analisando o log do PostgreSQL (que geralmente cobre a atividade de um dia), extraindo informações, computando estatísticas e finalmente produzindo uma página html sofisticada apresentando os resultados. O pgBadger não é restritivo na configuração log_line_prefix, ele pode se adaptar ao seu formato já existente. Por exemplo, se você configurou em seu postgresql.conf algo como:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'então o comando pgbadger para analisar o arquivo de log e produzir os resultados pode parecer com:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logO pgBadger fornece relatórios para:
- Visão geral das estatísticas (principalmente tráfego SQL)
- Conexões (por segundo, por banco de dados/usuário/host)
- Sessões (número, tempos de sessão, por banco de dados/usuário/host/aplicativo)
- Pontos de verificação (buffers, arquivos wal, atividade)
- Uso de arquivos temporários
- Atividade de vácuo/análise (por tabela, tuplas/páginas removidas)
- Bloqueios
- Consultas (por tipo/banco de dados/usuário/host/aplicativo, duração por usuário)
- Início (consultas:mais lentas, demoradas, mais frequentes, mais lentas normalizadas)
- Eventos (Erros, Avisos, Fatais, etc)
A tela que mostra as sessões se parece com:
Como podemos concluir, a instalação média do PostgreSQL precisa integrar e cuidar de muitas ferramentas para ter uma infraestrutura moderna, confiável e rápida e isso é bastante complexo de conseguir, a menos que haja grandes equipes envolvidas no postgresql e na administração do sistema. Um bom conjunto que faz tudo isso e muito mais é o ClusterControl.