Roteamento de transações Spring
Primeiro, vamos criar um
DataSourceType Java Enum que define nossas opções de roteamento de transações:public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Para rotear as transações de leitura/gravação para o nó primário e transações somente leitura para o nó de réplica, podemos definir um
ReadWriteDataSource que se conecta ao nó Primário e um ReadOnlyDataSource que se conectam ao nó Réplica. O roteamento de transações de leitura-gravação e somente leitura é feito pelo Spring
AbstractRoutingDataSource abstração, que é implementada pelo TransactionRoutingDatasource , conforme ilustrado pelo diagrama a seguir: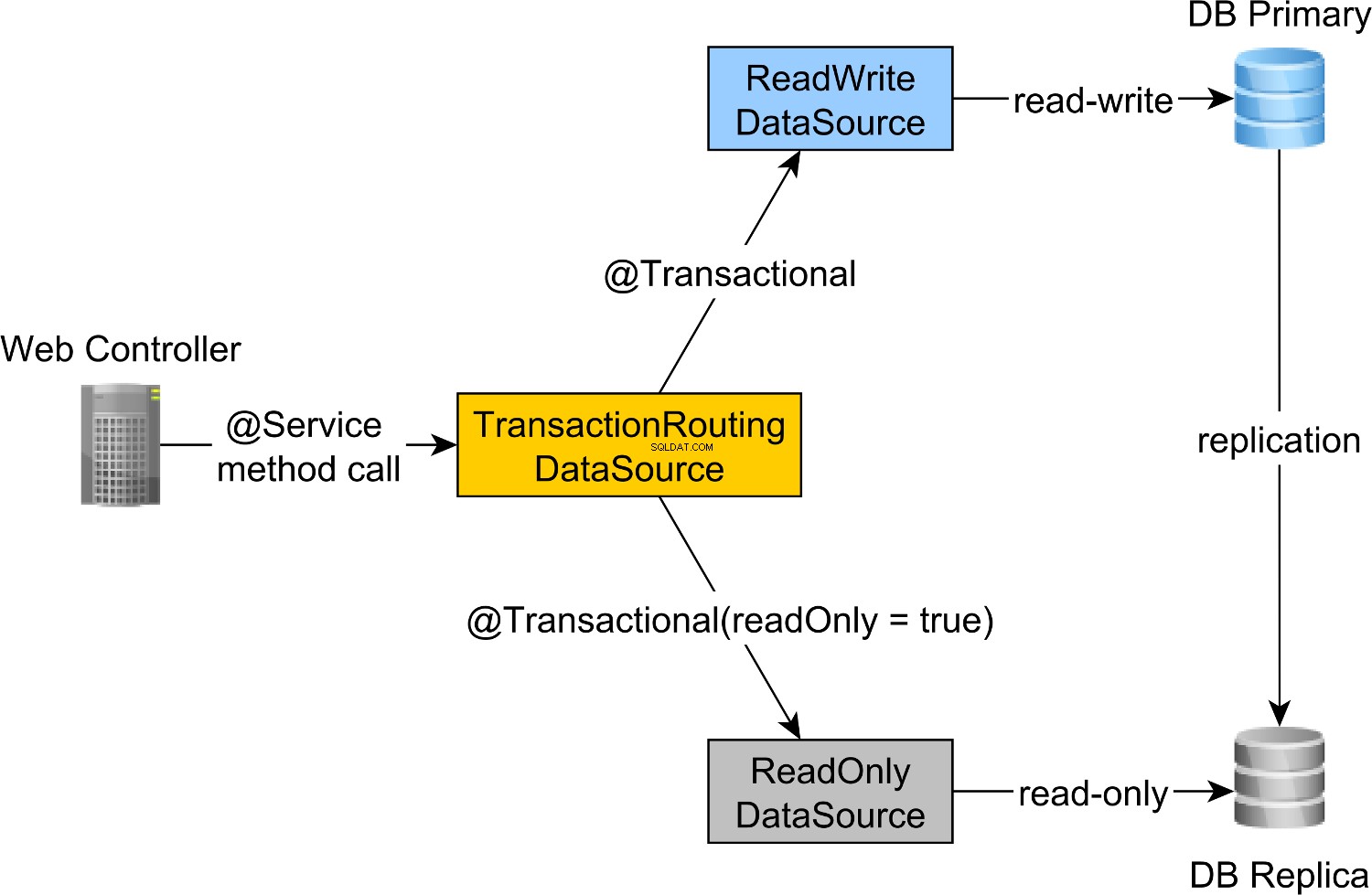
O
TransactionRoutingDataSource é muito fácil de implementar e se parece com o seguinte:public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
Basicamente, inspecionamos o Spring
TransactionSynchronizationManager classe que armazena o contexto transacional atual para verificar se a transação Spring atualmente em execução é somente leitura ou não. O
determineCurrentLookupKey O método retorna o valor discriminador que será usado para escolher o JDBC de leitura-gravação ou somente leitura DataSource . Configuração de fonte de dados JDBC de leitura/gravação e somente leitura
O
DataSource configuração fica da seguinte forma:@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
O
/META-INF/jdbc-postgresql-replication.properties arquivo de recurso fornece a configuração para o JDBC de leitura-gravação e somente leitura DataSource componentes:hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
O
jdbc.url.primary A propriedade define a URL do nó Primário enquanto o jdbc.url.replica define a URL do nó Réplica. O
readWriteDataSource O componente Spring define o JDBC de leitura e gravação DataSource enquanto o readOnlyDataSource componente define o JDBC somente leitura DataSource .
Observe que as fontes de dados de leitura-gravação e somente leitura usam HikariCP para pool de conexões.
O
actualDataSource atua como uma fachada para as fontes de dados de leitura-gravação e somente leitura e é implementado usando o TransactionRoutingDataSource Utilitário. O
readWriteDataSource é registrado usando o DataSourceType.READ_WRITE chave e o readOnlyDataSource usando o DataSourceType.READ_ONLY chave. Então, ao executar uma leitura-escrita
@Transactional método, o readWriteDataSource será usado ao executar um @Transactional(readOnly = true) método, o readOnlyDataSource será usado em seu lugar.
Observe que asadditionalPropertiesO método define ohibernate.connection.provider_disables_autocommitHibernate, que adicionei ao Hibernate para adiar a aquisição do banco de dados para transações RESOURCE_LOCAL JPA.
Não apenas ohibernate.connection.provider_disables_autocommitpermite que você faça melhor uso das conexões de banco de dados, mas é a única maneira de fazer este exemplo funcionar, pois, sem essa configuração, a conexão é adquirida antes de chamar odetermineCurrentLookupKeymétodoTransactionRoutingDataSource.
Os componentes restantes do Spring necessários para construir o JPA
EntityManagerFactory são definidos pelo AbstractJPAConfiguration classe básica. Basicamente, o
actualDataSource é ainda encapsulado pelo DataSource-Proxy e fornecido ao JPA EntityManagerFactory . Você pode verificar o código-fonte no GitHub para obter mais detalhes. Tempo de teste
Para verificar se o roteamento de transações funciona, vamos habilitar o log de consultas do PostgreSQL definindo as seguintes propriedades no
postgresql.conf arquivo de configuração:log_min_duration_statement = 0
log_line_prefix = '[%d] '
A
log_min_duration_statement A configuração da propriedade é para registrar todas as instruções do PostgreSQL enquanto a segunda adiciona o nome do banco de dados ao log SQL. Então, ao chamar o
newPost e findAllPostsByTitle métodos, assim:Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Podemos ver que o PostgreSQL registra as seguintes mensagens:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
As instruções de log usando a
high_performance_java_persistence prefix foram executados no nó Primário enquanto os que usam o high_performance_java_persistence_replica no nó Réplica. Assim, tudo funciona como um encanto!
Todo o código-fonte pode ser encontrado em meu repositório GitHub de persistência Java de alto desempenho, para que você possa experimentá-lo também.
Conclusão
Você precisa definir o tamanho certo para seus pools de conexão, pois isso pode fazer uma enorme diferença. Para isso, recomendo usar o Flexy Pool.
Você precisa ser muito diligente e marcar todas as transações somente leitura de acordo. É incomum que apenas 10% de suas transações sejam somente leitura. Pode ser que você tenha um aplicativo de maior quantidade de gravação ou esteja usando transações de gravação em que apenas emite instruções de consulta?
Para processamento em lote, você definitivamente precisa de transações de leitura e gravação, portanto, certifique-se de habilitar o lote JDBC, assim:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Para lotes, você também pode usar um
DataSource separado que usa um pool de conexões diferente que se conecta ao nó Primário. Apenas certifique-se de que o tamanho total da conexão de todos os pools de conexão seja menor que o número de conexões com as quais o PostgreSQL foi configurado.
Cada trabalho em lote deve usar uma transação dedicada, portanto, certifique-se de usar um tamanho de lote razoável.
Além disso, você deseja manter bloqueios e concluir as transações o mais rápido possível. Se o processador em lote estiver usando trabalhadores de processamento simultâneo, certifique-se de que o tamanho do pool de conexões associado seja igual ao número de trabalhadores, para que eles não esperem que outros liberem conexões.



