Corrigir o LEFT JOIN
Isso deve funcionar:
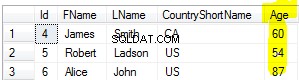
SELECT o.name AS organisation_name, count(e.id) AS total_used
FROM organisations o
LEFT JOIN exam_items e ON e.organisation_id = o.id
AND e.item_template_id = #{sanitize(item_template_id)}
AND e.used
GROUP BY o.name
ORDER BY o.name;
Você tinha um
LEFT [OUTER] JOIN mas o posterior WHERE condições fizeram com que ele agisse como um simples [INNER] JOIN .Mova a(s) condição(ões) para o
JOIN cláusula para fazê-lo funcionar como pretendido. Dessa forma, apenas as linhas que atendem a todas essas condições são unidas em primeiro lugar (ou colunas da direita tabela são preenchidos com NULL). Como você fez, as linhas unidas são testadas para condições adicionais virtualmente depois o LEFT JOIN e removidos se não passarem, assim como com um simples JOIN . count() nunca retorna NULL para começar. É uma exceção entre as funções agregadas a esse respeito. Portanto, COALESCE(COUNT(col))
Deve-se observar que exceto paracount, essas funções retornam um valor nulo quando nenhuma linha é selecionada.
Minha ênfase em negrito. Ver:
- Conte o número de atributos que são NULL para uma linha
count() deve estar em uma coluna definida NOT NULL (como e.id ), ou onde a condição de junção garante NOT NULL (e.organisation_id , e.item_template_id , ou e.used ) no exemplo. Desde
used é tipo boolean , a expressão e.used = true é o ruído que se reduz a apenas e.used . Desde
o.name não está definido UNIQUE NOT NULL , você pode querer GROUP BY o.id em vez disso (id sendo o PK) - a menos que você intenha para dobrar linhas com o mesmo nome (incluindo NULL). Agregue primeiro, junte-se depois
Se a maioria ou todas as linhas de
exam_items são contados no processo, essa consulta equivalente é normalmente consideravelmente mais rápida / mais barata:SELECT o.id, o.name AS organisation_name, e.total_used
FROM organisations o
LEFT JOIN (
SELECT organisation_id AS id -- alias to simplify join syntax
, count(*) AS total_used -- count(*) = fastest to count all
FROM exam_items
WHERE item_template_id = #{sanitize(item_template_id)}
AND used
GROUP BY 1
) e USING (id)
ORDER BY o.name, o.id;
(Isto supõe que você não deseja dobrar linhas com o mesmo nome mencionado acima - o caso típico.)
Agora podemos usar o
count(*) mais rápido/simples na subconsulta e não precisamos de GROUP BY no SELECT externo . Ver:
- Várias chamadas array_agg() em uma única consulta