A eficiência de um banco de dados não depende apenas do ajuste fino dos parâmetros mais críticos, mas também vai além da apresentação adequada dos dados nas coleções relacionadas. Recentemente, trabalhei em um projeto que desenvolvia um aplicativo de bate-papo social e, após alguns dias de testes, notamos algum atraso ao buscar dados do banco de dados. Não tínhamos tantos usuários, então descartamos o ajuste dos parâmetros do banco de dados e focamos em nossas consultas para chegar à causa raiz.
Para nossa surpresa, percebemos que nossa estruturação de dados não era totalmente adequada, pois tínhamos mais de 1 solicitação de leitura para buscar algumas informações específicas.
O modelo conceitual de como as seções do aplicativo são implementadas depende muito da estrutura das coleções do banco de dados. Por exemplo, se você fizer login em um aplicativo social, os dados serão inseridos nas diferentes seções de acordo com o design do aplicativo, conforme descrito na apresentação do banco de dados.
Em poucas palavras, para um banco de dados bem projetado, a estrutura do esquema e os relacionamentos de coleção são coisas fundamentais para sua velocidade e integridade aprimoradas, como veremos nas seções a seguir.
Discutiremos os fatores que você deve considerar ao modelar seus dados.
O que é modelagem de dados
A modelagem de dados geralmente é a análise de itens de dados em um banco de dados e como eles estão relacionados a outros objetos dentro desse banco de dados.
No MongoDB, por exemplo, podemos ter uma coleção de usuários e uma coleção de perfis. A coleção de usuários lista os nomes dos usuários de um determinado aplicativo, enquanto a coleção de perfis captura as configurações de perfil de cada usuário.
Na modelagem de dados, precisamos projetar um relacionamento para conectar cada usuário ao perfil correspondente. Em poucas palavras, a modelagem de dados é o passo fundamental no projeto de banco de dados, além de formar a base da arquitetura para a programação orientada a objetos. Também dá uma pista de como será a aparência da aplicação física durante o progresso do desenvolvimento. Uma arquitetura de integração de banco de dados de aplicativo pode ser ilustrada como abaixo.
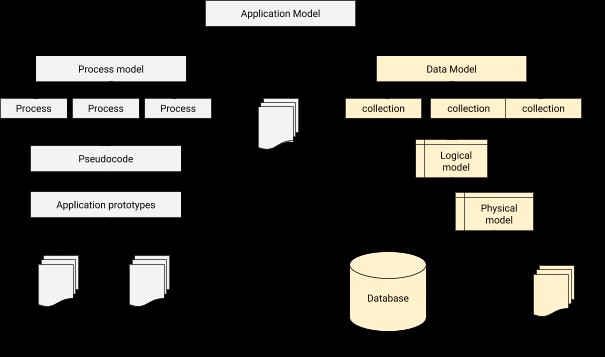
O processo de modelagem de dados no MongoDB
A modelagem de dados vem com desempenho aprimorado do banco de dados, mas à custa de algumas considerações que incluem:
- Padrões de recuperação de dados
- Balanceamento das necessidades do aplicativo como:consultas, atualizações e processamento de dados
- Recursos de desempenho do mecanismo de banco de dados escolhido
- A estrutura inerente dos dados em si
Estrutura do documento MongoDB
Os documentos no MongoDB desempenham um papel importante na tomada de decisão sobre qual técnica aplicar para um determinado conjunto de dados. Geralmente, existem dois relacionamentos entre os dados, que são:
- Dados incorporados
- Dados de referência
Dados incorporados
Nesse caso, os dados relacionados são armazenados em um único documento como um valor de campo ou uma matriz dentro do próprio documento. A principal vantagem dessa abordagem é que os dados são desnormalizados e, portanto, oferecem uma oportunidade para manipular os dados relacionados em uma única operação de banco de dados. Consequentemente, isso melhora a taxa na qual as operações CRUD são executadas, portanto, menos consultas são necessárias. Vamos considerar um exemplo de um documento abaixo:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}Neste conjunto de dados, temos um aluno com seu nome e algumas outras informações adicionais. O campo Settings foi incorporado a um objeto e, além disso, o campo placeLocation também é incorporado a um objeto com as configurações de latitude e longitude. Todos os dados para este aluno foram contidos em um único documento. Se precisarmos buscar todas as informações para este aluno, basta executar:
db.students.findOne({StudentName : "George Beckonn"})Forças da incorporação
- Aumento da velocidade de acesso aos dados:para uma melhor taxa de acesso aos dados, a incorporação é a melhor opção, já que uma única operação de consulta pode manipular dados no documento especificado com apenas uma única pesquisa no banco de dados.
- Inconsistência de dados reduzida:durante a operação, se algo der errado (por exemplo, uma desconexão da rede ou falha de energia), apenas alguns poucos documentos podem ser afetados, pois os critérios geralmente selecionam um único documento.
- Redução das operações CRUD. Isso quer dizer que as operações de leitura na verdade superam as gravações. Além disso, é possível atualizar dados relacionados em uma única operação de gravação atômica. Ou seja, para os dados acima, podemos atualizar o número de telefone e também aumentar a distância com esta única operação:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Deficiências da incorporação
- Tamanho do documento restrito. Todos os documentos no MongoDB são restritos ao tamanho BSON de 16 megabytes. Portanto, o tamanho geral do documento junto com os dados incorporados não deve ultrapassar esse limite. Caso contrário, para alguns mecanismos de armazenamento, como o MMAPv1, os dados podem crescer e resultar em fragmentação de dados como resultado da degradação do desempenho de gravação.
- Duplicação de dados:várias cópias dos mesmos dados dificultam a consulta dos dados replicados e pode levar mais tempo para filtrar documentos incorporados, superando a principal vantagem da incorporação.
Notação de ponto
A notação de ponto é o recurso de identificação para dados incorporados na parte de programação. Ele é usado para acessar elementos de um campo incorporado ou uma matriz. Nos dados de exemplo acima, podemos retornar informações do aluno cuja localização é “Embassy” com esta consulta usando a notação de ponto.
db.users.find({'Settings.location': 'Embassy'})Dados de referência
A relação de dados neste caso é que os dados relacionados são armazenados em documentos diferentes, mas algum link de referência é emitido para esses documentos relacionados. Para os dados de amostra acima, podemos reconstruí-los de tal forma que:
Documento do usuário
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Documento de configurações
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Existem 2 documentos diferentes, mas eles estão vinculados pelo mesmo valor para os campos _id e id. O modelo de dados é assim normalizado. No entanto, para acessarmos as informações de um documento relacionado, precisamos emitir consultas adicionais e, consequentemente, isso resulta em maior tempo de execução. Por exemplo, se quisermos atualizar o ParentPhone e as configurações de distância relacionadas, teremos pelo menos 3 consultas, ou seja,
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Forças da referência
- Consistência de dados. Para cada documento, uma forma canônica é mantida, portanto, as chances de inconsistência de dados são muito baixas.
- Integridade de dados aprimorada. Devido à normalização, é fácil atualizar os dados independentemente da duração da operação e, portanto, garantir dados corretos para cada documento sem causar confusão.
- Melhor utilização do cache. Documentos canônicos acessados com frequência são armazenados no cache em vez de documentos incorporados que são acessados algumas vezes.
- Utilização eficiente de hardware. Ao contrário da incorporação, que pode resultar na superação do documento, a referência não promove o crescimento do documento, portanto, reduz o uso de disco e RAM.
- Flexibilidade aprimorada, especialmente com um grande conjunto de subdocumentos.
- Gravações mais rápidas.
Deficiências da referência
- Várias pesquisas:como temos que procurar em vários documentos que correspondam aos critérios, aumenta o tempo de leitura ao recuperar do disco. Além disso, isso pode resultar em falhas de cache.
- Muitas consultas são emitidas para realizar alguma operação, portanto, os modelos de dados normalizados exigem mais viagens de ida e volta ao servidor para concluir uma operação específica.
Normalização de dados
A normalização de dados refere-se à reestruturação de um banco de dados de acordo com algumas formas normais para melhorar a integridade dos dados e reduzir os eventos de redundância de dados.
A modelagem de dados gira em torno de 2 técnicas principais de normalização que são:
-
Modelos de dados normalizados
Conforme aplicado em dados de referência, a normalização divide os dados em várias coleções com referências entre as novas coleções. Uma única atualização de documento será emitida para a outra coleção e aplicada de acordo com o documento correspondente. Isso fornece uma representação de atualização de dados eficiente e é comumente usado para dados que mudam com bastante frequência.
-
Modelos de dados desnormalizados
Os dados contêm documentos incorporados, tornando as operações de leitura bastante eficientes. No entanto, está associado a mais uso de espaço em disco e também a dificuldades para manter a sincronização. O conceito de desnormalização pode ser bem aplicado a subdocumentos cujos dados não mudam com frequência.
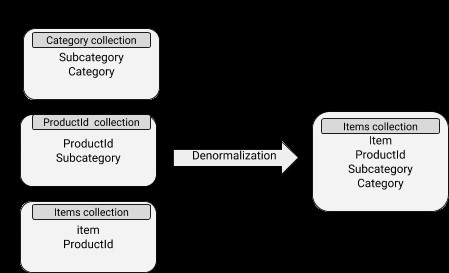
Esquema MongoDB
Um esquema é basicamente um esqueleto delineado de campos e tipo de dados que cada campo deve conter para um determinado conjunto de dados. Considerando o ponto de vista SQL, todas as linhas são projetadas para ter as mesmas colunas e cada coluna deve conter o tipo de dado definido. No entanto, no MongoDB, temos um Schema flexível por padrão que não possui a mesma conformidade para todos os documentos.
Esquema flexível
Um esquema flexível no MongoDB define que os documentos não precisam necessariamente ter os mesmos campos ou tipo de dados, pois um campo pode diferir entre documentos dentro de uma coleção. A principal vantagem desse conceito é que se pode adicionar novos campos, remover os existentes ou alterar os valores dos campos para um novo tipo e, portanto, atualizar o documento em uma nova estrutura.
Por exemplo, podemos ter esses 2 documentos na mesma coleção:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}No primeiro documento, temos um campo de idade enquanto que no segundo documento não há campo de idade. Além disso, o tipo de dados para o campo ParentPhone é um número, enquanto no segundo documento foi definido como false, que é um tipo booleano.
A flexibilidade do esquema facilita o mapeamento de documentos para um objeto e cada documento pode corresponder aos campos de dados da entidade representada.
Esquema rígido
Por mais que tenhamos dito que esses documentos podem diferir um do outro, às vezes você pode decidir criar um esquema rígido. Um esquema rígido definirá que todos os documentos em uma coleção compartilharão a mesma estrutura e isso lhe dará uma chance melhor de definir algumas regras de validação de documentos como forma de melhorar a integridade dos dados durante as operações de inserção e atualização.
Tipos de dados de esquema
Ao usar alguns drivers de servidor para MongoDB, como o mongoose, existem alguns tipos de dados fornecidos que permitem que você faça a validação de dados. Os tipos básicos de dados são:
- Sequência
- Número
- Booleano
- Data
- Tampão
- ObjectID
- Matriz
- Misto
- Decimal128
- Mapa
Dê uma olhada no esquema de exemplo abaixo
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Caso de uso de exemplo
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Validação do esquema
Por mais que você possa fazer a validação de dados do lado do aplicativo, é sempre uma boa prática fazer a validação do lado do servidor também. Conseguimos isso empregando as regras de validação de esquema.
Essas regras são aplicadas durante as operações de inserção e atualização. Eles são declarados em uma base de coleta durante o processo de criação normalmente. No entanto, você também pode adicionar as regras de validação de documentos a uma coleção existente usando o comando collMod com opções de validação, mas essas regras não são aplicadas aos documentos existentes até que uma atualização seja aplicada a eles.
Da mesma forma, ao criar uma nova coleção usando o comando db.createCollection() você pode emitir a opção validador. Dê uma olhada neste exemplo ao criar uma coleção para alunos. A partir da versão 3.6, o MongoDB suporta a validação do esquema JSON, portanto, tudo o que você precisa é usar o operador $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Neste projeto de esquema, se tentarmos inserir um novo documento como:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})A função de retorno de chamada retornará o erro abaixo, devido a algumas regras de validação violadas, como o valor do ano fornecido não estar dentro dos limites especificados.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Além disso, você pode adicionar expressões de consulta à sua opção de validação usando operadores de consulta, exceto $where, $text, near e $nearSphere, ou seja:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Níveis de validação do esquema
Como mencionado anteriormente, a validação é emitida para as operações de gravação, normalmente.
No entanto, a validação também pode ser aplicada a documentos já existentes.
Existem 3 níveis de validação:
- Estrita:este é o nível de validação padrão do MongoDB e aplica regras de validação a todas as inserções e atualizações.
- Moderado:as regras de validação são aplicadas durante inserções, atualizações e documentos já existentes que atendem apenas aos critérios de validação.
- Desativado:este nível define as regras de validação para um determinado esquema como nulo, portanto, nenhuma validação será feita nos documentos.
Exemplo:
Vamos inserir os dados abaixo em uma coleção de clientes.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Se aplicarmos o nível de validação moderado usando:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )As regras de validação serão aplicadas apenas ao documento com _id de 1, pois atenderá a todos os critérios.
Para o segundo documento, uma vez que as regras de validação não são atendidas com os critérios emitidos, o documento não será validado.
Ações de validação do esquema
Depois de fazer a validação nos documentos, pode haver alguns que podem violar as regras de validação. Há sempre a necessidade de fornecer uma ação quando isso acontece.
O MongoDB fornece duas ações que podem ser emitidas para os documentos que falham nas regras de validação:
- Erro:esta é a ação padrão do MongoDB, que rejeita qualquer inserção ou atualização caso viole os critérios de validação.
-
Aviso:Esta ação registrará a violação no log do MongoDB, mas permite que a operação de inserção ou atualização seja concluída. Por exemplo:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })
Se tentarmos inserir um documento como este:
db.students.insert( { name: "Amanda", status: "Updated" } );
O gpa está ausente, independentemente do fato de ser um campo obrigatório no design do esquema, mas como a ação de validação foi definida para avisar, o documento será salvo e uma mensagem de erro será registrada no log do MongoDB.



