Isso foi hash e re-hash. Além de a dica que indiquei no comentário e os links e explicação @xQbert postados acima, a pedido, aqui está uma explicação de COALESCE vs. ISNULL usando uma subconsulta. Vamos considerar essas duas consultas, que em termos de resultados são idênticas:
SELECT COALESCE((SELECT TOP (1) name FROM sys.objects), N'foo');
SELECT ISNULL((SELECT TOP (1) name FROM sys.objects), N'foo');
(Comentários sobre o uso de TOP sem ORDER BY para /dev/null/ obrigado.)
No caso COALESCE, a lógica na verdade é expandida para algo assim:
SELECT CASE WHEN (SELECT TOP (1) ...) IS NULL
THEN (SELECT TOP (1) ...)
ELSE N'foo'
END
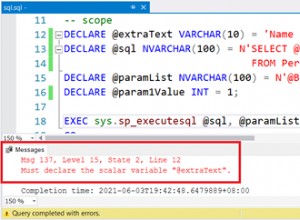
Com ISNULL, isso não acontece. Existe uma otimização interna que parece garantir que a subconsulta seja avaliada apenas uma vez. Não sei se alguém fora da Microsoft sabe exatamente como essa otimização funciona, mas você pode fazer isso se comparar os planos. Aqui está o plano para a versão COALESCE:

E aqui está o plano para a versão ISNULL - observe como é mais simples (e que a verificação acontece apenas uma vez):

No caso COALESCE a varredura acontece duas vezes. Significando que a subconsulta é avaliada duas vezes, mesmo que não produza nenhum resultado. Se você adicionar uma cláusula WHERE de forma que a subconsulta produza 0 linhas, verá uma disparidade semelhante - as formas do plano podem mudar, mas você ainda verá uma busca dupla+pesquisa ou varredura para o caso COALESCE. Aqui está um exemplo ligeiramente diferente:
SELECT COALESCE((SELECT TOP (1) name FROM sys.objects
WHERE name = N'no way this exists'), N'foo');
SELECT ISNULL((SELECT TOP (1) name FROM sys.objects
WHERE name = N'no way this exists'), N'foo');
O plano para a versão COALESCE desta vez - novamente você pode ver todo o branch que representa a subconsulta repetida literalmente:
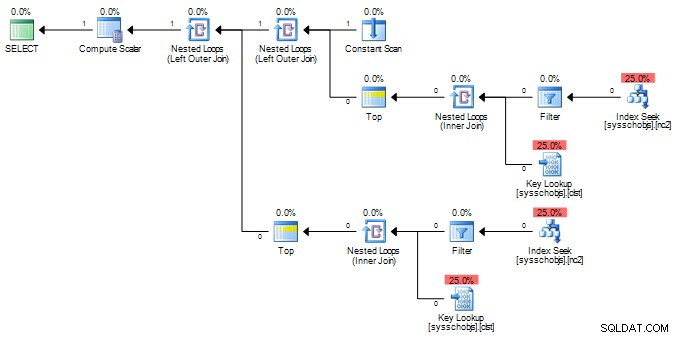
E novamente um plano muito mais simples, fazendo aproximadamente metade do trabalho, usando ISNULL:

Você também pode ver esta pergunta no dba.se para mais discussão:
Minha sugestão é esta (e você pode ver meus motivos na dica e na pergunta acima):confie, mas verifique. Eu sempre uso COALESCE (porque é padrão ANSI, suporta mais de dois argumentos e não faz coisas tão complicadas com precedência de tipo de dados) a menos que Eu sei que estou usando uma subconsulta como uma das expressões (que não me lembro de ter feito fora do trabalho teórico como este) ou estou enfrentando um problema real de desempenho e só quero comparar para ver se COALESCE vs. diferença de desempenho substancial (que fora do caso da subconsulta, ainda não encontrei). Como quase sempre estou usando o COALESCE com argumentos de tipos de dados semelhantes, raramente preciso fazer qualquer teste além de analisar o que disse sobre isso no passado (também fui o autor de o artigo aspfaq que xQbert apontou , 7 anos atrás).