O SQL Server 2014 CTP1 foi lançado há algumas semanas e você provavelmente já viu um pouco da imprensa sobre tabelas com otimização de memória e índices columnstore atualizáveis. Embora estes sejam certamente dignos de atenção, neste post eu queria explorar a nova melhoria do paralelismo SELECT … INTO. A melhoria é uma daquelas mudanças de prêt-à-porter que, pelo que parece, não exigirá mudanças significativas de código para começar a se beneficiar dela. Minhas explorações foram realizadas usando a versão Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
SELEÇÃO Paralela … INTO
SQL Server 2014 apresenta
SELECT ... INTO habilitado para paralelo para bancos de dados e para testar esse recurso usei o banco de dados AdventureWorksDW2012 e uma versão da tabela FactInternetSales que continha 61.847.552 linhas (eu fui responsável por adicionar essas linhas; elas não vêm com o banco de dados por padrão). Como esse recurso, a partir do CTP1, requer nível de compatibilidade de banco de dados 110, para fins de teste, configurei o banco de dados para nível de compatibilidade 100 e executei a seguinte consulta para meu primeiro teste:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; A duração da execução da consulta foi de 3 minutos e 19 segundos na minha VM de teste e o plano real de execução da consulta produzido foi o seguinte:

O SQL Server usou um plano serial, como eu esperava. Observe também que minha tabela tinha um índice columnstore não clusterizado que foi verificado (criei esse índice columnstore não clusterizado para uso com outros testes, mas também mostrarei o plano de execução da consulta de índice columnstore clusterizado posteriormente). O plano não usou paralelismo e o Columnstore Index Scan usou o modo de execução de linha em vez do modo de execução em lote.
Então, em seguida, modifiquei o nível de compatibilidade do banco de dados (e observe que ainda não há um nível de compatibilidade do SQL Server 2014 no CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Eliminei a tabela FactInternetSales_V2 e executei novamente meu
SELECT ... INTO original Operação. Desta vez, a duração da execução da consulta foi de 1 minuto e 7 segundos e o plano real de execução da consulta foi o seguinte: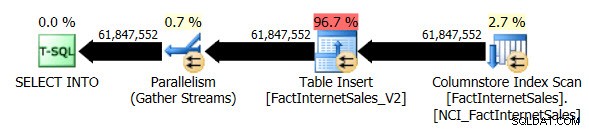
Agora temos um plano paralelo e a única mudança que tive que fazer foi no nível de compatibilidade do banco de dados para AdventureWorksDW2012. Minha VM de teste tem quatro vCPUs alocadas a ela e o plano de execução da consulta distribuiu linhas em quatro threads:

O Columnstore Index Scan não clusterizado, enquanto usava paralelismo, não usava o modo de execução em lote. Em vez disso, usou o modo de execução de linha.
Aqui está uma tabela para mostrar os resultados do teste até agora:
| Tipo de digitalização | Nível de compatibilidade | Seleção paralela … INTO | Modo de execução | Duração |
|---|---|---|---|---|
| Verificação de índice de armazenamento de colunas não clusterizado | 100 | Não | Linha | 3:19 |
| Verificação de índice de armazenamento de colunas não clusterizado | 110 | Sim | Linha | 1:07 |
Então, como próximo teste, eliminei o índice columnstore não clusterizado e executei novamente o
SELECT ... INTO consulta usando o nível de compatibilidade de banco de dados 100 e 110. O teste de compatibilidade nível 100 levou 5 minutos e 44 segundos para ser executado e o seguinte plano foi gerado:
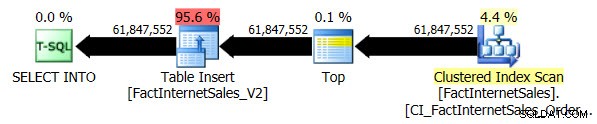
A varredura de índice clusterizado serial levou 2 minutos e 25 segundos a mais do que a varredura de índice Columnstore serial não clusterizada.
Usando o nível de compatibilidade 110, a consulta levou 1 minuto e 55 segundos para ser executada e o seguinte plano foi gerado:

Semelhante ao teste paralelo de verificação de índice Columnstore não clusterizado, a verificação paralela de índice clusterizado distribuiu linhas em quatro encadeamentos:
A tabela a seguir resume esses dois testes acima mencionados:
| Tipo de digitalização | Nível de compatibilidade | Seleção paralela … INTO | Modo de execução | Duração |
|---|---|---|---|---|
| Verificação de índice em cluster | 100 | Não | Linha (N/A) | 5:44 |
| Verificação de índice em cluster | 110 | Sim | Linha (N/A) | 1:55 |
Então, eu me perguntei sobre o desempenho de um índice columnstore clusterizado (novo no SQL Server 2014), então descartei os índices existentes e criei um índice columnstore clusterizado na tabela FactInternetSales. Eu também tive que descartar as oito restrições de chave estrangeira diferentes definidas na tabela antes que eu pudesse criar o índice columnstore clusterizado.
A discussão se torna um tanto acadêmica, pois estou comparando
SELECT ... INTO desempenho em níveis de compatibilidade de banco de dados que não ofereciam índices columnstore clusterizados em primeiro lugar – nem os testes anteriores para índices columnstore não clusterizados no nível de compatibilidade de banco de dados 100 – e ainda assim é interessante ver e comparar as características gerais de desempenho. CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Além disso, a operação para criar o índice columnstore clusterizado em uma tabela de 61.847.552 milhões de linhas levou 11 minutos e 25 segundos com quatro vCPUs disponíveis (das quais a operação aproveitou todas), 4 GB de RAM e armazenamento convidado virtual em SSDs OCZ Vertex. Durante esse tempo, as CPUs não estavam indexadas o tempo todo, mas exibiam picos e vales (uma amostragem de 60 segundos de atividade da CPU mostrada abaixo):
Após a criação do índice columnstore clusterizado, executei novamente os dois
SELECT ... INTO testes. O teste de nível de compatibilidade 100 levou 3 minutos e 22 segundos para ser executado, e o plano foi serial conforme o esperado (estou mostrando a versão SQL Server Management Studio do plano desde o Columnstore Index Scan clusterizado, a partir do SQL Server 2014 CTP1 , ainda não é totalmente reconhecido pelo Plan Explorer):
Em seguida, alterei o nível de compatibilidade do banco de dados para 110 e executei novamente o teste, que desta vez a consulta levou 1 minuto e 11 segundos e teve o seguinte plano de execução real:

O plano distribuiu linhas em quatro encadeamentos e, assim como o índice columnstore não clusterizado, o modo de execução do Columnstore Index Scan clusterizado era de linha e não de lote.
A tabela a seguir resume todos os testes neste post (em ordem de duração, de baixo para alto):
| Tipo de digitalização | Nível de compatibilidade | Seleção paralela … INTO | Modo de execução | Duração |
|---|---|---|---|---|
| Verificação de índice de armazenamento de colunas não clusterizado | 110 | Sim | Linha | 1:07 |
| Verificação de índice de armazenamento de colunas em cluster | 110 | Sim | Linha | 1:11 |
| Verificação de índice em cluster | 110 | Sim | Linha (N/A) | 1:55 |
| Verificação de índice de armazenamento de colunas não clusterizado | 100 | Não | Linha | 3:19 |
| Verificação de índice de armazenamento de colunas em cluster | 100 | Não | Linha | 3:22 |
| Verificação de índice em cluster | 100 | Não | Linha (N/A) | 5:44 |
Algumas observações:
- Não tenho certeza se a diferença entre um
SELECT ... INTOparalelo operação em relação a um índice columnstore não clusterizado versus índice columnstore clusterizado é estatisticamente significativo. Precisaria fazer mais testes, mas acho que esperaria para realizá-los até o RTM. - Posso dizer com segurança que o
SELECT ... INTOparalelo superou significativamente os equivalentes seriais em testes de índice clusterizado, armazenamento de colunas não clusterizado e armazenamento de colunas clusterizado.
Vale ressaltar que esses resultados são para uma versão CTP do produto, e meus testes devem ser vistos como algo que pode mudar o comportamento do RTM - então eu estava menos interessado nas durações independentes versus como essas durações comparadas entre serial e paralela condições.
Alguns recursos de desempenho exigem refatoração significativa - mas para o
SELECT ... INTO melhoria, tudo o que eu precisava fazer era aumentar o nível de compatibilidade do banco de dados para começar a ver os benefícios, o que definitivamente é algo que eu aprecio.