Na primeira parte desta série, apresentei a terminologia básica sobre registro, então recomendo que você leia isso antes de continuar com este post. Todo o resto que abordarei na série requer conhecer um pouco da arquitetura do log de transações, então é isso que vou discutir desta vez. Mesmo que você não vá acompanhar a série, vale a pena conhecer alguns dos conceitos que vou explicar abaixo para tarefas cotidianas que os DBAs lidam com a produção.
Hierarquia Estrutural
O log de transações é organizado internamente usando uma hierarquia de três níveis, conforme mostrado na figura 1 abaixo.
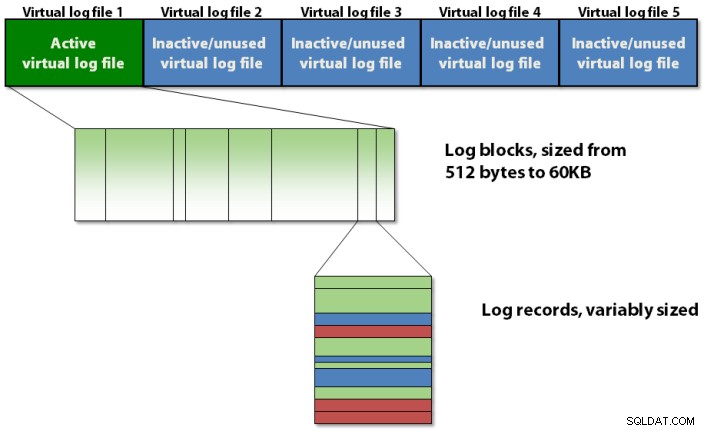 Figura 1:a hierarquia estrutural de três níveis do log de transações em>
Figura 1:a hierarquia estrutural de três níveis do log de transações em> O log de transações contém arquivos de log virtuais, que contêm blocos de log, que armazenam os registros de log reais.
Arquivos de registro virtuais
O log de transações é dividido em seções chamadas arquivos de log virtuais , comumente chamados de VLFs . Isso é feito para facilitar o gerenciamento de operações no log de transações para o gerenciador de logs no SQL Server. Você não pode especificar quantos VLFs são criados pelo SQL Server quando o banco de dados é criado pela primeira vez ou o arquivo de log cresce automaticamente, mas você pode influenciá-lo. O algoritmo para quantos VLFs são criados é o seguinte:
- Tamanho do arquivo de log menor que 64 MB:crie 4 VLFs, cada um com aproximadamente 16 MB de tamanho
- Tamanho do arquivo de log de 64 MB a 1 GB:crie 8 VLFs, cada um com aproximadamente 1/8 do tamanho total
- Tamanho do arquivo de log maior que 1 GB:crie 16 VLFs, cada um com aproximadamente 1/16 do tamanho total
Antes do SQL Server 2014, quando o arquivo de log cresce automaticamente, o número de novos VLFs adicionados ao final do arquivo de log é determinado pelo algoritmo acima, com base no tamanho do crescimento automático. No entanto, usando esse algoritmo, se o tamanho do crescimento automático for pequeno e o arquivo de log passar por muitos aumentos automáticos, isso poderá levar a um número muito grande de VLFs pequenos (chamado fragmentação de VLF ) que pode ser um grande problema de desempenho para algumas operações (veja aqui).
Devido a esse problema, no SQL Server 2014 o algoritmo foi alterado para o crescimento automático do arquivo de log. Se o tamanho de crescimento automático for menor que 1/8 do tamanho total do arquivo de log, apenas um novo VLF será criado, caso contrário, o algoritmo antigo será usado. Isso reduz drasticamente o número de VLFs para um arquivo de log que passou por uma grande quantidade de crescimento automático. Eu expliquei um exemplo da diferença neste post do blog.
Cada VLF tem um número de sequência que o identifica de maneira única e é usado em vários lugares, o que explicarei abaixo e em postagens futuras. Você pensaria que os números de sequência começariam em 1 para um banco de dados totalmente novo, mas esse não é o caso.
Em uma instância do SQL Server 2019, criei um novo banco de dados, sem especificar nenhum tamanho de arquivo, e verifiquei os VLFs usando o código abaixo:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB')); Observe o
sys.dm_db_log_info A DMV foi adicionada no SQL Server 2016 SP2. Antes disso (e hoje, porque ainda existe) você pode usar o não documentado DBCC LOGINFO comando, mas você não pode dar a ele uma lista de seleção - apenas faça DBCC LOGINFO(N'NewDB'); e os números de sequência VLF estão no FSeqNo coluna do conjunto de resultados. De qualquer forma, os resultados da consulta de
sys.dm_db_log_info estavam:file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Observe que o primeiro VLF começa no deslocamento de 8.192 bytes no arquivo de log. Isso ocorre porque todos os arquivos de banco de dados, incluindo o log de transações, têm uma página de cabeçalho de arquivo que ocupa os primeiros 8 KB e armazena vários metadados sobre o arquivo.
Então, por que o SQL Server escolhe 37 e não 1 para o primeiro número de sequência do VLF? Ele encontra o número de sequência VLF mais alto no
model banco de dados e, em seguida, para qualquer novo banco de dados, o primeiro VLF do log de transações usa esse número mais 1 para seu número de sequência. Não sei por que esse algoritmo foi escolhido nas brumas do tempo, mas tem sido assim desde pelo menos o SQL Server 7.0. Para provar isso, executei este código:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); E os resultados foram:
Max_VLF_SeqNo -------------------- 36
Então aí está.
Há mais para discutir sobre VLFs e como eles são usados, mas por enquanto basta saber que cada VLF tem um número de sequência, que aumenta em um para cada VLF.
Blocos de registro
Cada VLF contém um pequeno cabeçalho de metadados e o restante do espaço é preenchido com blocos de log. Cada bloco de log começa em 512 bytes e crescerá em incrementos de 512 bytes até um tamanho máximo de 60 KB, ponto em que deve ser gravado no disco. Um bloco de log pode ser gravado no disco antes de atingir seu tamanho máximo se ocorrer uma das seguintes situações:
- Uma transação é confirmada e a durabilidade atrasada não está sendo usada para essa transação, portanto, o bloco de log deve ser gravado em disco para tornar a transação durável
- A durabilidade atrasada está em uso, e a tarefa de timer de 1 ms em segundo plano "liberar o bloco de log atual para o disco" é acionada
- Uma página de arquivo de dados está sendo gravada no disco por um ponto de verificação ou gravador lento, e há um ou mais registros de log no bloco de log atual que afetam a página que está prestes a ser gravada (lembre-se que o log de gravação antecipada deve ser garantido)
Você pode considerar um bloco de log como algo como uma página de tamanho variável que armazena registros de log na ordem em que são criados por transações que alteram o banco de dados. Não há um bloco de log para cada transação; os registros de log para várias transações simultâneas podem ser misturados em um bloco de log. Você pode pensar que isso apresentaria dificuldades para operações que precisam encontrar todos os registros de log para uma única transação, mas isso não acontece, como explicarei quando abordar como as reversões de transação funcionam em uma postagem posterior.
Além disso, quando um bloco de log é gravado em disco, é perfeitamente possível que ele contenha registros de log de transações não confirmadas. Isso também não é um problema devido à maneira como a recuperação de falhas funciona - o que é um bom número de postagens no futuro da série.
Números de sequência de log
Os blocos de log têm um ID dentro de um VLF, começando em 1 e aumentando em 1 para cada novo bloco de log no VLF. Os registros de log também têm um ID dentro de um bloco de log, começando em 1 e aumentando em 1 para cada novo registro de log no bloco de log. Assim, todos os três elementos na hierarquia estrutural do log de transações têm um ID e são reunidos em um identificador tripartido chamado número de sequência do log , mais comumente referido simplesmente como um LSN .
Um LSN é definido como
<VLF sequence number>:<log block ID>:<log record ID> (4 bytes:4 bytes:2 bytes) e identifica exclusivamente um único registro de log. É um identificador cada vez maior, porque os números de sequência VLF aumentam para sempre. Fundamentos concluídos!
Embora seja importante conhecer os VLFs, na minha opinião o LSN é o conceito mais importante a ser entendido em torno da implementação de log do SQL Server, pois os LSNs são a base sobre a qual a reversão de transações e a recuperação de falhas são construídas, e os LSNs surgirão repetidamente à medida que Eu progrido através da série. Na próxima postagem, abordarei o truncamento de log e a natureza circular do log de transações, que tem tudo a ver com VLFs e como eles são reutilizados.