Todos nós nos tornamos prejudicados pela capacidade dos mecanismos de pesquisa de “solucionar” coisas como erros de ortografia, diferenças de ortografia de nomes ou qualquer outra situação em que o termo de pesquisa possa corresponder em páginas cujos autores podem preferir usar uma grafia diferente de uma palavra. Adicionar esses recursos aos nossos próprios aplicativos baseados em banco de dados pode enriquecer e aprimorar nossos aplicativos de maneira semelhante e, embora as ofertas de sistemas de gerenciamento de banco de dados relacional comercial (RDBMS) forneçam suas próprias soluções personalizadas totalmente desenvolvidas para esse problema, os custos de licenciamento dessas ferramentas podem ser alcance para desenvolvedores menores ou pequenas empresas de desenvolvimento de software.
Pode-se argumentar que isso poderia ser feito usando um verificador ortográfico. No entanto, um verificador ortográfico normalmente não é útil ao combinar uma ortografia correta, mas alternativa, de um nome ou outra palavra. A correspondência por som preenche essa lacuna funcional. Esse é o tópico do tutorial de programação de hoje:como consultar sons com Python usando metafones.
O que é Soundex?
Soundex foi desenvolvido no início do século 20 como um meio para o Censo dos EUA combinar nomes com base em como eles soam. Foi então usado por várias companhias telefônicas para combinar os nomes dos clientes. Ele continua a ser usado para correspondência de dados fonéticos até hoje, apesar de estar limitado às grafias e pronúncias do inglês americano. Também é limitado a letras em inglês. A maioria dos RDBMS, como SQL Server e Oracle, juntamente com MySQL e suas variantes, implementam uma função Soundex e, apesar de suas limitações, continua a ser usada para combinar muitas palavras não inglesas.
O que é um Metafone Duplo?
O Metafone algoritmo foi desenvolvido em 1990 e supera algumas das limitações do Soundex. Em 2000, uma continuação melhorada, Double Metaphone , foi desenvolvido. Double Metaphone retorna um valor primário e secundário que corresponde a duas maneiras pelas quais uma única palavra pode ser pronunciada. Até hoje, esse algoritmo continua sendo um dos melhores algoritmos fonéticos de código aberto. O Metaphone 3 foi lançado em 2009 como uma melhoria do Double Metaphone, mas este é um produto comercial.
Infelizmente, muitos dos RDBMS proeminentes mencionados acima não implementam Double Metaphone, e a maioria linguagens de script proeminentes não fornecem uma implementação suportada de Double Metaphone. No entanto, o Python fornece um módulo que implementa o Double Metaphone.
Os exemplos apresentados neste tutorial de programação Python usam MariaDB versão 10.5.12 e Python 3.9.2, ambos rodando em Kali/Debian Linux.
Como adicionar metafone duplo ao Python
Como qualquer módulo Python, a ferramenta pip pode ser usada para instalar o Double Metaphone. A sintaxe depende da sua instalação do Python. Uma instalação típica do Double Metaphone se parece com o exemplo a seguir:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Observe que a capitalização extra é intencional. O código a seguir é um exemplo de como usar o Double Metaphone em Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
O script Python acima fornece a seguinte saída quando executado em seu ambiente de desenvolvimento integrado (IDE) ou editor de código:
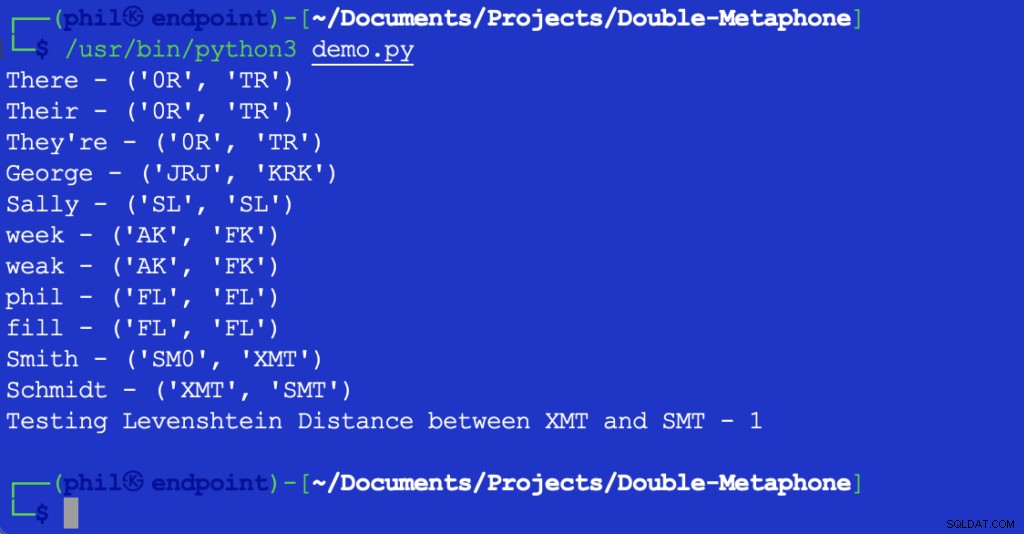
Figura 1 – Saída do script de demonstração
Como pode ser visto aqui, cada palavra tem um valor fonético primário e secundário. As palavras que correspondem em valores primários ou secundários são chamadas de correspondências fonéticas. Palavras que compartilham pelo menos um valor fonético, ou que compartilham o primeiro par de caracteres em qualquer valor fonético, são ditas foneticamente próximas umas das outras.
A maioria letras exibidas correspondem às suas pronúncias em inglês. X pode corresponder a KS , SH , ou C . 0 corresponde ao th som no o ou lá . As vogais são combinadas apenas no início de uma palavra. Por causa do número incontável de diferenças nos sotaques regionais, não é possível dizer que as palavras podem ser uma correspondência objetivamente exata, mesmo que tenham os mesmos valores fonéticos.
Comparando valores fonéticos com Python
Existem vários recursos online que podem descrever o funcionamento completo do algoritmo Double Metaphone; no entanto, isso não é necessário para usá-lo porque estamos mais interessados em comparar os valores calculados, mais do que estamos interessados em calcular os valores. Como dito anteriormente, se houver pelo menos um valor em comum entre duas palavras, pode-se dizer que esses valores são correspondências fonéticas , e valores fonéticos que são semelhantes são foneticamente próximos .
Comparar valores absolutos é fácil, mas como as strings podem ser determinadas como semelhantes? Embora não haja limitações técnicas que impeçam você de comparar sequências de várias palavras, essas comparações geralmente não são confiáveis. Atenha-se a comparar palavras isoladas.
Quais são as distâncias de Levenshtein?
A Distância Levenshtein entre duas strings é o número de caracteres únicos que devem ser alterados em uma string para que ela corresponda à segunda string. Um par de cordas que tem uma distância Levenshtein mais baixa são mais semelhantes entre si do que um par de cordas que tem uma distância Levenshtein mais alta. A distância de Levenshtein é semelhante à distância de Hamming , mas este último é limitado a strings de mesmo comprimento, como os valores fonéticos do Double Metaphone podem variar em comprimento, faz mais sentido compará-los usando a Distância de Levenshtein.
Biblioteca de distâncias Python Levenshtein
Python pode ser estendido para suportar cálculos de distância Levenshtein por meio de um módulo Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Observe que, como na instalação do DoubleMetaphone acima, a sintaxe da chamada para pip pode variar. O módulo python-Levenshtein fornece muito mais funcionalidades do que apenas cálculos de distância de Levenshtein.
O código abaixo mostra um teste para o cálculo da distância Levenshtein em Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
A execução desse script fornece a seguinte saída:
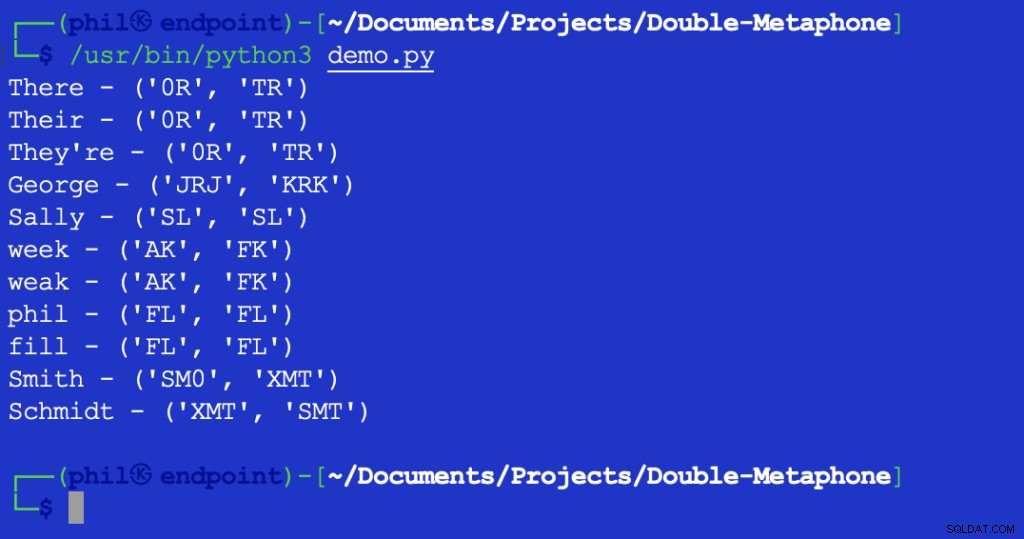
Figura 2 – Resultado do teste de distância de Levenshtein
O valor retornado de 1 indica que existe um caractere entre XMT e SMT isso é diferente. Nesse caso, é o primeiro caractere em ambas as strings.
Comparando Metafones Duplos em Python
O que se segue não é a base das comparações fonéticas. É simplesmente uma das muitas maneiras de realizar tal comparação. Para comparar efetivamente a proximidade fonética de quaisquer duas strings, cada valor fonético Double Metaphone de uma string deve ser comparado ao valor fonético Double Metaphone correspondente de outra string. Como ambos os valores fonéticos de uma determinada string recebem peso igual, a média desses valores de comparação fornecerá uma aproximação razoavelmente boa da proximidade fonética:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Onde:
- DM1(1) :primeiro valor de metafone duplo da string 1,
- DM1(2) :Segundo valor de metafone duplo da string 1
- DM2(1) :Primeiro valor de metafone duplo da string 2
- DM2(2) :Segundo valor de metafone duplo da string 2
- PN :Proximidade fonética, com valores mais baixos sendo mais próximos do que valores mais altos. Um valor zero indica similaridade fonética. O valor mais alto para isso é o número de letras na string mais curta.
Esta fórmula é dividida em casos como Schmidt (XMT, SMT) e Smith (SM0, XMT) onde o primeiro valor fonético da primeira string corresponde ao segundo valor fonético da segunda string. Em tais situações, tanto Schmidt e Smith podem ser considerados foneticamente semelhantes por causa do valor compartilhado. O código para a função de proximidade deve aplicar a fórmula acima somente quando todos os quatro valores fonéticos forem diferentes. A fórmula também tem pontos fracos ao comparar strings de diferentes comprimentos.
Observe que não há uma maneira singularmente eficaz de comparar cordas de diferentes comprimentos, embora o cálculo da Distância Levenshtein entre duas cordas seja fator de diferenças no comprimento da corda. Uma solução possível seria comparar ambas as strings até o comprimento da mais curta das duas strings.
Abaixo está um snippet de código de exemplo que implementa o código acima, juntamente com alguns exemplos de teste:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
O código Python de amostra fornece a seguinte saída:
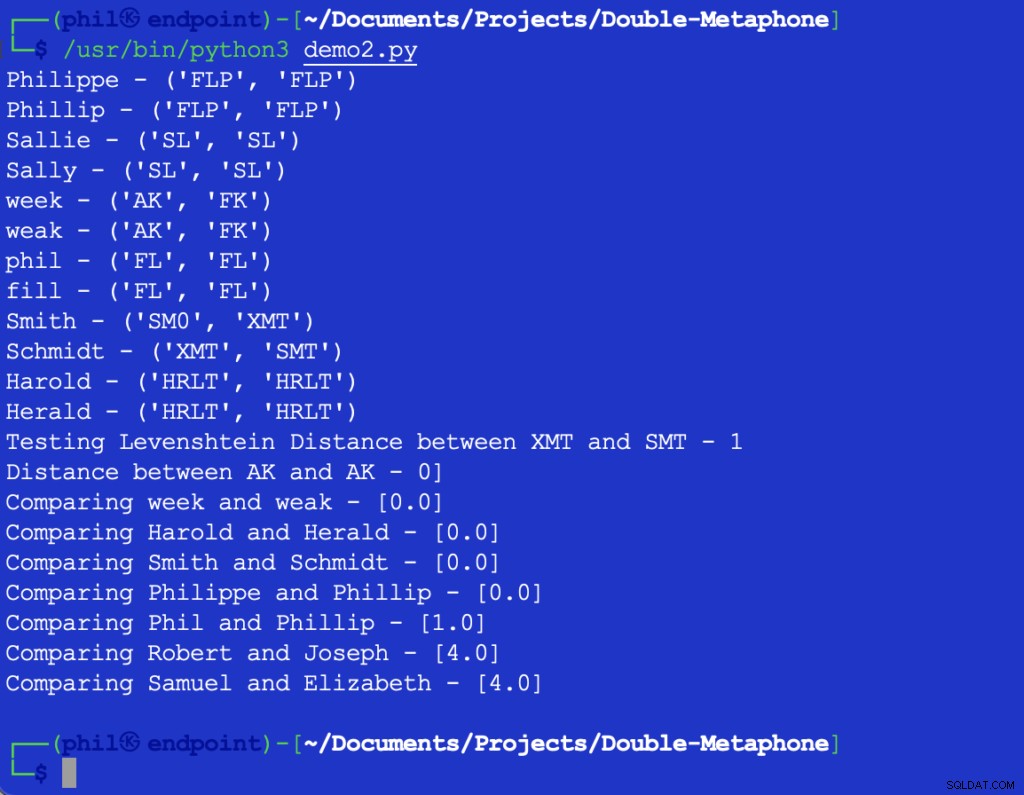
Figura 3 – Saída do algoritmo de proximidade
O conjunto de amostras confirma a tendência geral de que quanto maiores as diferenças nas palavras, maior a saída do Proximidade função.
Integração de banco de dados em Python
O código acima viola a lacuna funcional entre um determinado RDBMS e uma implementação de Double Metaphone. Além disso, implementando a Proximidade função em Python, torna-se fácil substituir se um algoritmo de comparação diferente for preferido.
Considere a seguinte tabela MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Na maioria dos aplicativos controlados por banco de dados, o middleware compõe as instruções SQL para gerenciar os dados, inclusive inseri-los. O código a seguir inserirá alguns nomes de amostra nessa tabela, mas, na prática, qualquer código de um aplicativo da Web ou de desktop que coleta esses dados pode fazer a mesma coisa.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
A execução desse código não imprime nada, mas preenche a tabela de teste no banco de dados para a próxima listagem a ser usada. Consultar a tabela diretamente no cliente MySQL pode verificar se o código acima funcionou:
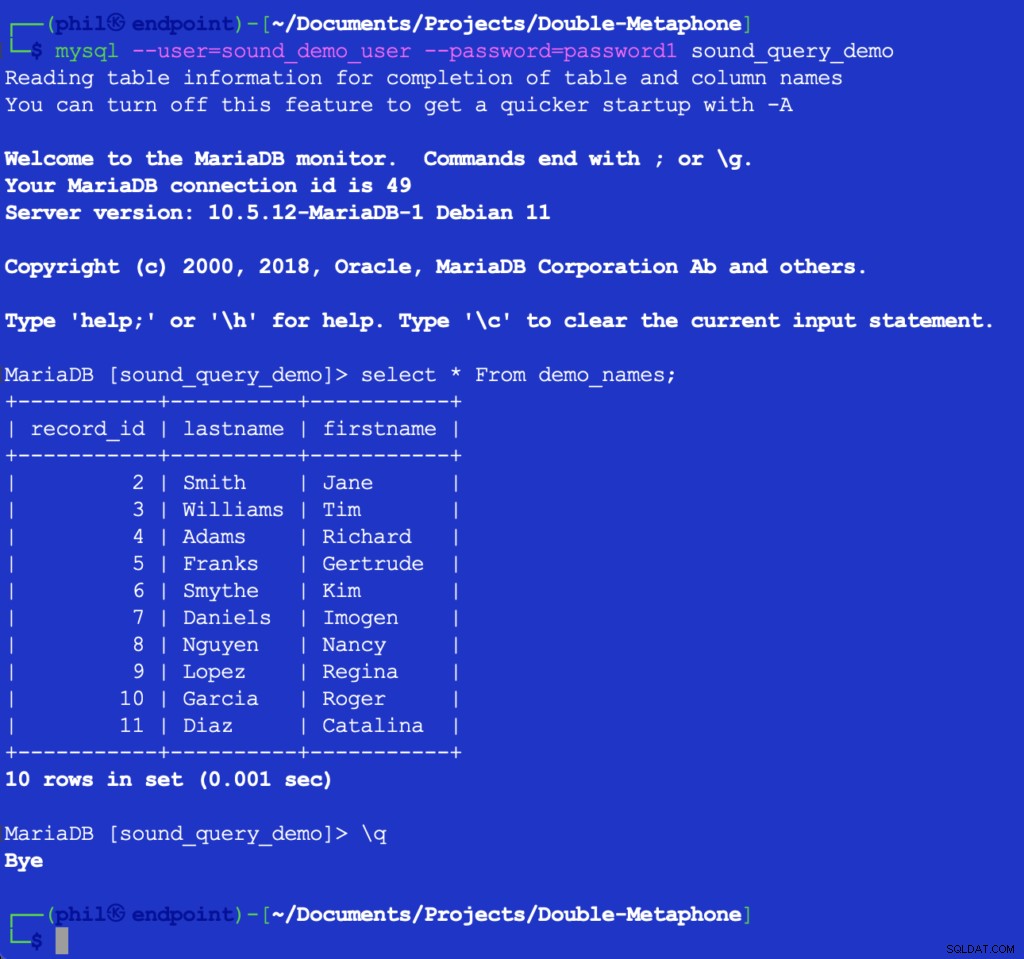
Figura 4- Os dados da tabela inserida
O código abaixo alimentará alguns dados de comparação nos dados da tabela acima e realizará uma comparação de proximidade com eles:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
A execução deste código nos dá a saída abaixo:
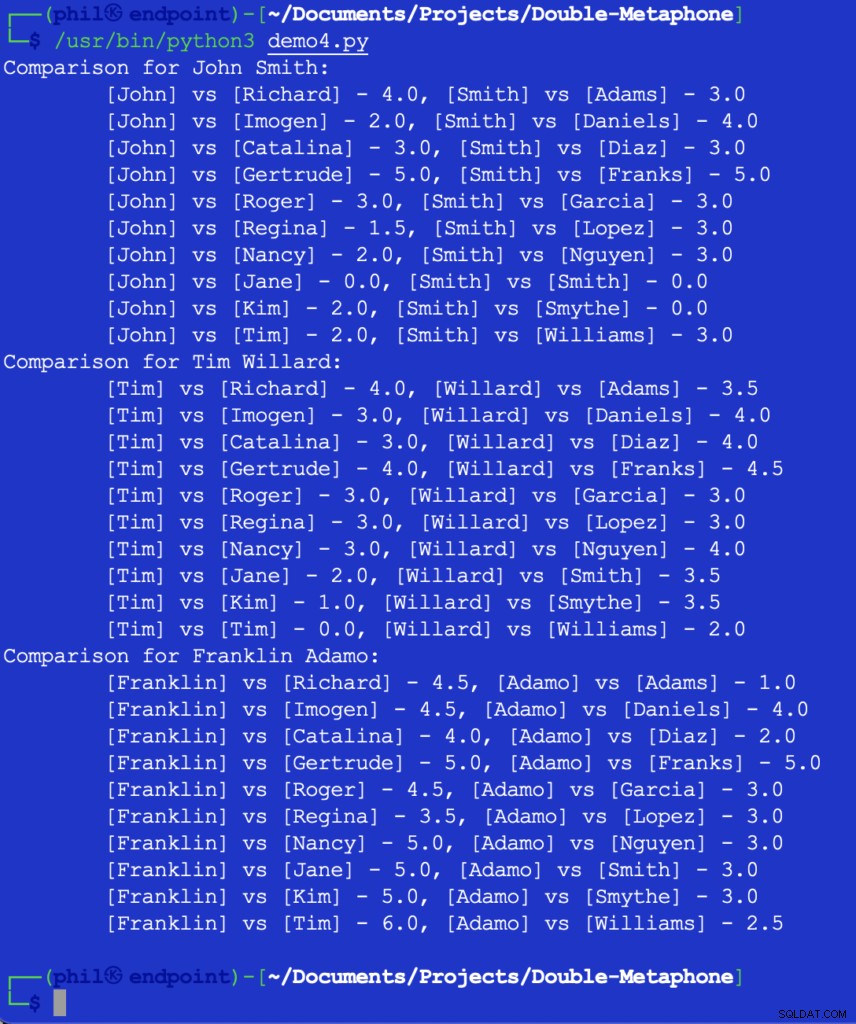
Figura 5 – Resultados da comparação de proximidade
Neste ponto, caberia ao desenvolvedor decidir qual seria o limite para o que constitui uma comparação útil. Alguns dos números acima podem parecer inesperados ou surpreendentes, mas uma possível adição ao código pode ser um SE instrução para filtrar qualquer valor de comparação maior que 2 .
Pode valer a pena notar que os próprios valores fonéticos não são armazenados no banco de dados. Isso ocorre porque eles são calculados como parte do código Python e não há uma necessidade real de armazená-los em qualquer lugar, pois são descartados quando o programa sai, no entanto, um desenvolvedor pode encontrar valor em armazená-los no banco de dados e depois implementar a comparação função dentro do banco de dados um procedimento armazenado. No entanto, a principal desvantagem disso é a perda de portabilidade de código.
Considerações finais sobre como consultar dados por som com Python
A comparação de dados por som não parece obter o “amor” ou a atenção que a comparação de dados por análise de imagem pode obter, mas se um aplicativo tiver que lidar com várias variantes de palavras com sons semelhantes em vários idiomas, pode ser uma ferramenta extremamente útil. ferramenta. Uma característica útil desse tipo de análise é que um desenvolvedor não precisa ser um especialista em linguística ou fonética para fazer uso dessas ferramentas. O desenvolvedor também tem grande flexibilidade na definição de como esses dados podem ser comparados; as comparações podem ser ajustadas com base nas necessidades do aplicativo ou da lógica de negócios.
Espera-se que este campo de estudo receba mais atenção na esfera da pesquisa e haja ferramentas de análise mais capazes e robustas daqui para frente.