Ao executar uma consulta, o otimizador do SQL Server tenta encontrar o melhor plano de consulta com base nos índices existentes e nas estatísticas mais recentes disponíveis por um tempo razoável, é claro, se esse plano ainda não estiver armazenado no cache do servidor. Se não, a consulta é executada de acordo com este plano e o plano é armazenado no cache do servidor. Se o plano já foi construído para esta consulta, a consulta é executada de acordo com o plano existente.
Estamos interessados na seguinte questão:
Durante a compilação de um plano de consulta, ao classificar possíveis índices, se o servidor não encontrar o melhor índice, o índice ausente é marcado no plano de consulta e o servidor mantém estatísticas sobre tais índices:quantas vezes o servidor usaria esse índice e quanto custaria essa consulta.
Neste artigo, vamos analisar esses índices ausentes – como lidar com eles.
Vamos considerar isso em um exemplo particular. Crie algumas tabelas em nosso banco de dados em um servidor local e de teste:
[expandir título =”Código”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expandir]
A estrutura é simples e consiste em duas tabelas. A primeira tabela é chamada de pedidos com campos como identificador, data de venda e vendedor. A segunda são os detalhes do pedido, onde algumas mercadorias são especificadas com preço e quantidade.
Veja uma consulta simples e seu plano:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
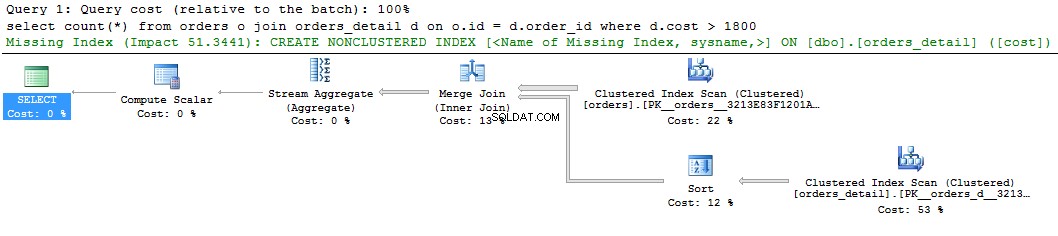
Podemos ver uma dica verde sobre o índice ausente na exibição gráfica do plano de consulta. Se você clicar com o botão direito do mouse e selecionar “Missing Index Details ..”, haverá o texto do índice sugerido. A única coisa a fazer é remover os comentários no texto e dar um nome ao índice. O script está pronto para ser executado.
Não construiremos o índice que recebemos da dica fornecida pelo SSMS. Em vez disso, veremos se esse índice será recomendado por visualizações dinâmicas vinculadas a índices ausentes. As vistas são as seguintes:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
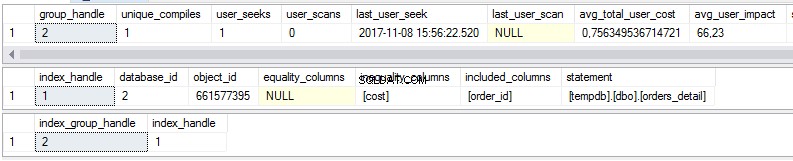
Como podemos ver, existem algumas estatísticas sobre índices ausentes na primeira visualização:
- Quantas vezes uma pesquisa seria realizada se o índice sugerido existisse?
- Quantas vezes uma verificação seria executada se o índice sugerido existisse?
- Última data e hora em que usamos o índice
- O custo real atual do plano de consulta sem o índice sugerido.
A segunda visão é o corpo do índice:
- Banco de dados
- Objeto/tabela
- Colunas classificadas
- Colunas adicionadas para aumentar a cobertura do índice
A terceira vista é a combinação da primeira e da segunda vista.
Assim, não é difícil obter um script que gere um script para criar índices ausentes dessas visualizações dinâmicas. O roteiro é o seguinte:
[expandir título=”Código”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expandir]
Para eficiência do índice, os índices ausentes são gerados. A solução perfeita é quando esse conjunto de resultados não retorna nada. Em nosso exemplo, o conjunto de resultados retornará pelo menos um índice:

Quando não há tempo e você não tem vontade de lidar com os bugs do cliente, executei a consulta, copiei a primeira coluna e executei no servidor. Depois disso, tudo funcionou bem.
Eu recomendo tratar as informações sobre esses índices de forma consciente. Por exemplo, se o sistema recomendar os seguintes índices:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
E esses índices são usados para a pesquisa, é bastante óbvio que é mais lógico substituir esses índices por um que cubra todos os três sugeridos:
create index ix_1 on tbl1 (a,b) include (c,d)
Assim, fazemos uma revisão dos índices ausentes antes de implantá-los no servidor de produção. Embora…. Novamente, por exemplo, implantei os índices perdidos no servidor TFS, aumentando assim o desempenho geral. Levou um tempo mínimo para realizar essa otimização. No entanto, ao mudar do TFS 2015 para o TFS 2017, enfrentei o problema de não haver atualização devido a esses novos índices. No entanto, eles podem ser facilmente encontrados pela máscara
select * from sys.indexes where name like 'ix[_]2017%'
Ferramenta útil:
dbForge Index Manager – suplemento SSMS útil para analisar o status de índices SQL e corrigir problemas com fragmentação de índice.