Não sei sobre os componentes internos do Microsoft SQL Server, mas posso responder pelo MySQL, que você marcou para sua pergunta. Os detalhes podem variar para outras implementações.
T1. Certo, nenhum espaço extra é necessário para o índice clusterizado.
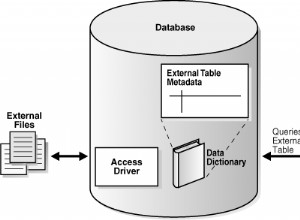
O que acontece se você descartar o índice clusterizado? O mecanismo InnoDB do MySQL sempre usa a chave primária (ou a primeira chave exclusiva não nula) como o índice clusterizado. Se você definir uma tabela sem chave primária ou descartar a chave primária de uma tabela existente, O InnoDB gera uma chave artificial interna para o índice clusterizado . Essa chave interna não tem coluna lógica para fazer referência a ela.
Q2. Uma ordem de linhas retornadas por uma consulta que usa um índice não clusterizado não é garantida. Na prática, é a ordem em que as linhas foram acessadas. Se você precisar que as linhas sejam retornadas em uma ordem específica, use
ORDER BY em sua consulta. Se o otimizador puder inferir que a ordem desejada é a mesma na qual ele acessará as linhas (ordem do índice, seja por índice clusterizado ou não clusterizado), ele poderá pular a etapa de classificação. T3. O índice não clusterizado do InnoDB não possui um ponteiro para a linha correspondente em uma folha do índice, ele possui o valor da chave primária. Portanto, uma pesquisa em um índice não clusterizado é, na verdade, duas pesquisas em árvore B, a primeira para encontrar a folha do índice não clusterizado e, em seguida, uma segunda pesquisa no índice clusterizado.
Isso é o dobro do custo de uma única pesquisa em árvore B (mais ou menos), então o InnoDB tem um recurso extra chamado Índice de hash adaptável . Os valores pesquisados com frequência são armazenados em cache no AHI e, na próxima vez que uma consulta pesquisar um valor armazenado em cache, ela poderá fazer uma pesquisa O(1). No cache AHI, ele encontra um ponteiro diretamente para a folha do índice clusterizado, eliminando ambos Pesquisas em árvores B, parte do tempo.
O quanto isso melhora o desempenho total depende da frequência com que você pesquisa os mesmos valores que foram pesquisados antes. Na minha experiência, é típico que a proporção de pesquisas de hash versus pesquisas sem hash seja de cerca de 1:2.
Q4. Construa os índices para atender as consultas que você precisa para otimizar. Normalmente, um índice clusterizado é uma chave primária ou exclusiva e, pelo menos no caso do InnoDB, isso é necessário. Nem
age nem salary é provável que seja único. Você pode gostar da minha apresentação, Como criar índices, realmente .
Q5. O InnoDB cria automaticamente um índice quando você declara uma restrição exclusiva. Você não pode ter a restrição sem um índice existente para ela. Se você não tivesse um índice, como o mecanismo garantiria a exclusividade ao inserir um valor? Seria necessário pesquisar em toda a tabela um valor duplicado nessa coluna. O índice ajuda a tornar as verificações exclusivas muito mais eficientes.