Seu "problema" é o
utf8_unicode_ci agrupamento. Esse agrupamento faz "expansões de caracteres", o que significa que os tremas e seus caracteres básicos são tratados como o mesmo mesmo em um = comparação :A = Ä
O = Ö
...
O segundo exemplo nesta página de manual do mySQL explica o problema:9.1.7.8. Exemplos do efeito do agrupamento
O que você teria que fazer é alternar para um agrupamento que distinga entre trema e caractere base (por exemplo,
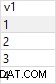
utf8_general_ci ou utf8_general_bin ) ou alterne para um agrupamento diferente apenas ao fazer a comparação:select * from users where username like 'Björn' COLLATE utf8_general_ci;
isso é obviamente mais lento, porque a conversão de agrupamento deve ser feita para cada registro durante a consulta.