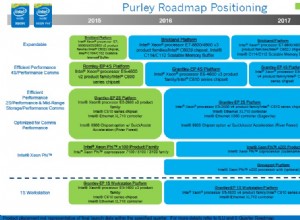
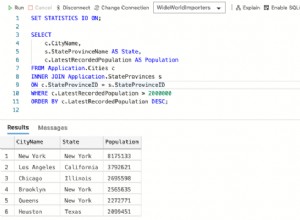
Você pode querer um índice calculado.
Vamos criar uma tabela:
create table sales(day date, amount real);
E preenchê-lo com algumas coisas aleatórias:
insert into sales
select current_date + s.a as day, random()*100 as amount
from generate_series(1,20);
Indexe por dia, nada de especial aqui:
create index sales_by_day on sales(day);
Crie uma função de posição de linha. Existem outras abordagens, esta é a mais simples:
create or replace function sales_pos (date) returns bigint
as 'select count(day) from sales where day <= $1;'
language sql immutable;
Verifique se funciona (embora não chame assim em grandes conjuntos de dados):
select sales_pos(day), day, amount from sales;
sales_pos | day | amount
-----------+------------+----------
1 | 2011-07-08 | 41.6135
2 | 2011-07-09 | 19.0663
3 | 2011-07-10 | 12.3715
..................
Agora a parte complicada:adicione outro índice calculado nos valores da função sales_pos:
create index sales_by_pos on sales using btree(sales_pos(day));
Aqui está como você usá-lo. 5 é o seu "offset", 10 é o "limite":
select * from sales where sales_pos(day) >= 5 and sales_pos(day) < 5+10;
day | amount
------------+---------
2011-07-12 | 94.3042
2011-07-13 | 12.9532
2011-07-14 | 74.7261
...............
É rápido, pois quando você chama assim, o Postgres usa valores pré-calculados do índice:
explain select * from sales
where sales_pos(day) >= 5 and sales_pos(day) < 5+10;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using sales_by_pos on sales (cost=0.50..8.77 rows=1 width=8)
Index Cond: ((sales_pos(day) >= 5) AND (sales_pos(day) < 15))
Espero que ajude.