Seus dados são provavelmente os ativos mais valiosos da empresa, portanto, você deve ter um Plano de Recuperação de Desastres (DRP) para evitar a perda de dados em caso de acidente ou falha de hardware. Um backup é a forma mais simples de DR. Pode nem sempre ser suficiente para garantir um objetivo de ponto de recuperação (RPO) aceitável, mas é uma boa primeira abordagem. Além disso, você deve definir um Objetivo de Tempo de Recuperação (RTO) de acordo com os requisitos da sua empresa. Existem muitas maneiras de atingir o valor RTO, depende dos objetivos da empresa.
Neste blog, veremos como usar o pgBackRest para fazer backup de PostgreSQL e TimescaleDB e como usar um dos recursos mais importantes dessa ferramenta de backup, a combinação de backups completos, incrementais e diferenciais, para minimizar o tempo de inatividade.
O que é pgBackRest?
Existem diferentes tipos de backups para bancos de dados:
- Lógico:o backup é armazenado em um formato legível como SQL.
- Físico:o backup contém dados binários.
- Completo/Incremental/Diferencial:A definição desses três tipos de backup está implícita no nome. O backup completo é uma cópia completa de todos os seus dados. O backup incremental faz backup apenas dos dados que foram alterados desde o backup anterior e o backup diferencial contém apenas os dados que foram alterados desde o último backup completo executado. Os backups incrementais e diferenciais foram introduzidos como uma forma de diminuir o tempo e o uso do espaço em disco necessários para realizar um backup completo.
pgBackRest é uma ferramenta de backup de código aberto que cria backups físicos com algumas melhorias em comparação com a ferramenta clássica pg_basebackup. Podemos usar pgBackRest para executar uma cópia inicial do banco de dados para Streaming Replication usando um backup existente ou podemos usar a opção delta para reconstruir um servidor em espera antigo.
Alguns dos recursos mais importantes do pgBackRest são:
- Backup e restauração paralelos
- Operação local ou remota
- Backups completos, incrementais e diferenciais
- Rotação de backup e expiração do arquivo
- Verificação de integridade do backup
- Currículo de backup
- Restauração Delta
- Criptografia
Agora, vamos ver como podemos usar o pgBackRest para fazer backup de nossos bancos de dados PostgreSQL e TimescaleDB.
Como usar o pgBackRest
Para este teste, usaremos o CentOS 7 como SO e o PostgreSQL 11 como servidor de banco de dados. Vamos supor que você tenha o banco de dados instalado, caso contrário, você pode seguir esses links para implantar o PostgreSQL ou o TimescaleDB de maneira fácil usando o ClusterControl.
Primeiro, precisamos instalar o pacote pgbackrest.
$ yum install pgbackrestO pgBackRest pode ser usado a partir da linha de comando ou de um arquivo de configuração localizado por padrão em /etc/pgbackrest.conf no CentOS7. Este arquivo contém as seguintes linhas:
[global]
repo1-path=/var/lib/pgbackrest
#[main]
#pg1-path=/var/lib/pgsql/10/dataVocê pode verificar este link para ver qual parâmetro podemos adicionar neste arquivo de configuração.
Vamos adicionar as seguintes linhas:
[testing]
pg1-path=/var/lib/pgsql/11/dataCertifique-se de ter a seguinte configuração adicionada no arquivo postgresql.conf (essas alterações requerem uma reinicialização do serviço).
archive_mode = on
archive_command = 'pgbackrest --stanza=testing archive-push %p'
max_wal_senders = 3
wal_level = logicalAgora, vamos fazer um backup básico. Primeiro, precisamos criar uma “estrofe”, que defina a configuração de backup para um cluster de banco de dados PostgreSQL ou TimescaleDB específico. A seção de sub-rotina deve definir o caminho do cluster de banco de dados e o host/usuário se o cluster de banco de dados for remoto.
$ pgbackrest --stanza=testing --log-level-console=info stanza-create
2019-04-29 21:46:36.922 P00 INFO: stanza-create command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:46:37.475 P00 INFO: stanza-create command end: completed successfully (554ms)E então, podemos executar o comando check para validar a configuração.
$ pgbackrest --stanza=testing --log-level-console=info check
2019-04-29 21:51:09.893 P00 INFO: check command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:51:12.090 P00 INFO: WAL segment 000000010000000000000001 successfully stored in the archive at '/var/lib/pgbackrest/archive/testing/11-1/0000000100000000/000000010000000000000001-f29875cffe780f9e9d9debeb0b44d945a5165409.gz'
2019-04-29 21:51:12.090 P00 INFO: check command end: completed successfully (2197ms)Para fazer o backup, execute o seguinte comando:
$ pgbackrest --stanza=testing --type=full --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=full
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 15:43:21": backup begins after the next regular checkpoint completes
INFO: backup start archive = 000000010000000000000006, lsn = 0/6000028
WARN: aborted backup 20190429-215508F of same type exists, will be cleaned to remove invalid files and resumed
INFO: backup file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: full backup size = 31.8MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 000000010000000000000006, lsn = 0/6000130
INFO: new backup label = 20190429-215508F
INFO: backup command end: completed successfully (12810ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (10ms)Agora, temos o backup finalizado com a saída “concluído com sucesso”, então, vamos restaurá-lo. Pararemos o serviço postgresql-11.
$ service postgresql-11 stop
Redirecting to /bin/systemctl stop postgresql-11.serviceE deixe o datadir vazio.
$ rm -rf /var/lib/pgsql/11/data/*Agora, execute o seguinte comando:
$ pgbackrest --stanza=testing --log-level-stderr=info restore
INFO: restore command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
INFO: restore backup set 20190429-215508F
INFO: restore file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: write /var/lib/pgsql/11/data/recovery.conf
INFO: restore global/pg_control (performed last to ensure aborted restores cannot be started)
INFO: restore command end: completed successfully (10819ms)Em seguida, inicie o serviço postgresql-11.
$ service postgresql-11 stopE agora temos nosso banco de dados funcionando.
$ psql -U app_user world
world=> select * from city limit 5;
id | name | countrycode | district | population
----+----------------+-------------+---------------+------------
1 | Kabul | AFG | Kabol | 1780000
2 | Qandahar | AFG | Qandahar | 237500
3 | Herat | AFG | Herat | 186800
4 | Mazar-e-Sharif | AFG | Balkh | 127800
5 | Amsterdam | NLD | Noord-Holland | 731200
(5 rows)Agora, vamos ver como podemos fazer um backup diferencial.
$ pgbackrest --stanza=testing --type=diff --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=diff
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: last backup label = 20190429-215508F, version = 2.13
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 21:22:58": backup begins after the next regular checkpoint completes
INFO: backup start archive = 00000002000000000000000B, lsn = 0/B000028
WARN: a timeline switch has occurred since the last backup, enabling delta checksum
INFO: backup file /var/lib/pgsql/11/data/base/16429/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/16429/2608 (448KB, 8%) checksum 53bd7995dc4d29226b1ad645995405e0a96a4a7b
. . .
INFO: diff backup size = 40.1MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 00000002000000000000000B, lsn = 0/B000130
INFO: new backup label = 20190429-215508F_20190430-212258D
INFO: backup command end: completed successfully (23982ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (14ms)Para backups mais complexos, você pode seguir o guia do usuário pgBackRest.
Como mencionamos anteriormente, você pode usar a linha de comando ou os arquivos de configuração para gerenciar seus backups.
Como usar pgBackRest no ClusterControl
Desde a versão 1.7.2, ClusterControl adicionou suporte para pgBackRest para fazer backup de bancos de dados PostgreSQL e TimescaleDB, então vamos ver como podemos usá-lo no ClusterControl.
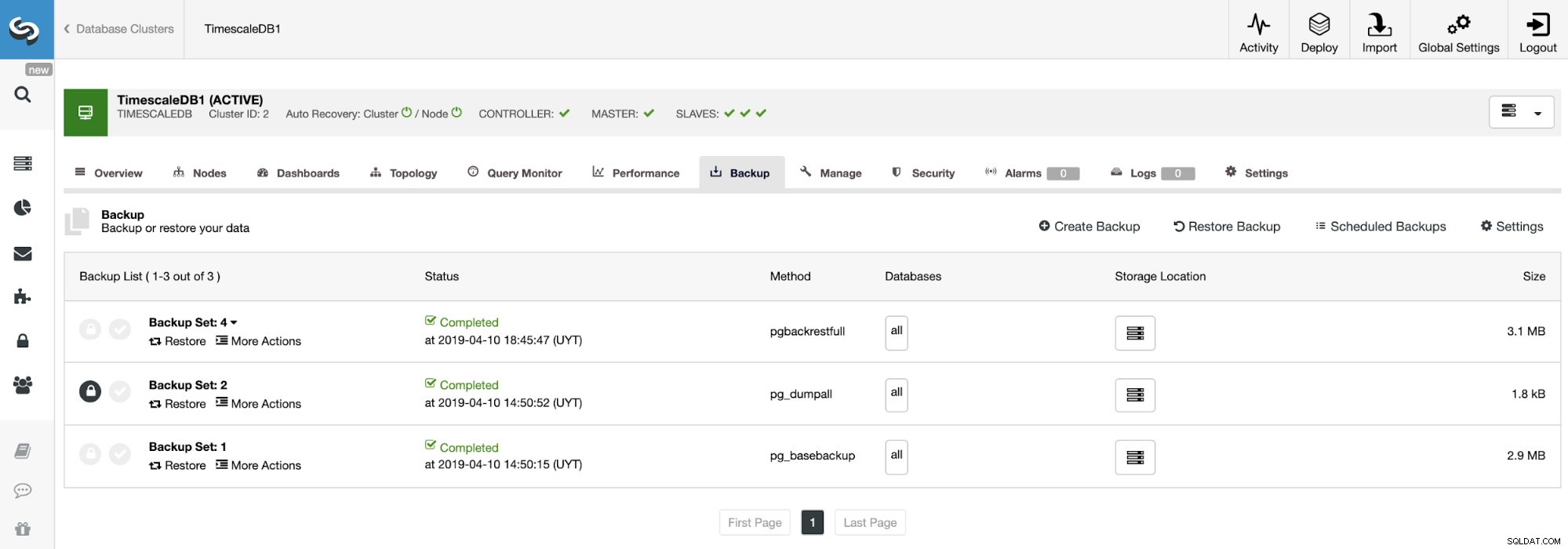
Criando um backup
Para esta tarefa, vá para ClusterControl -> Select Cluster -> Backup -> Create Backup.
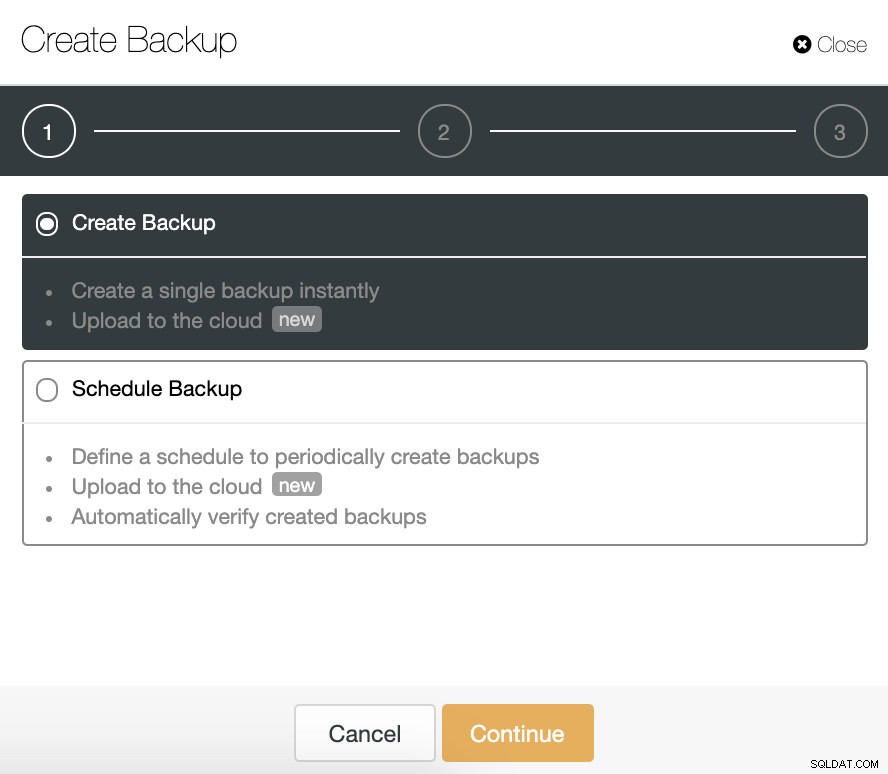
Podemos criar um novo backup ou configurar um agendado. Para o nosso exemplo, criaremos um único backup instantaneamente.
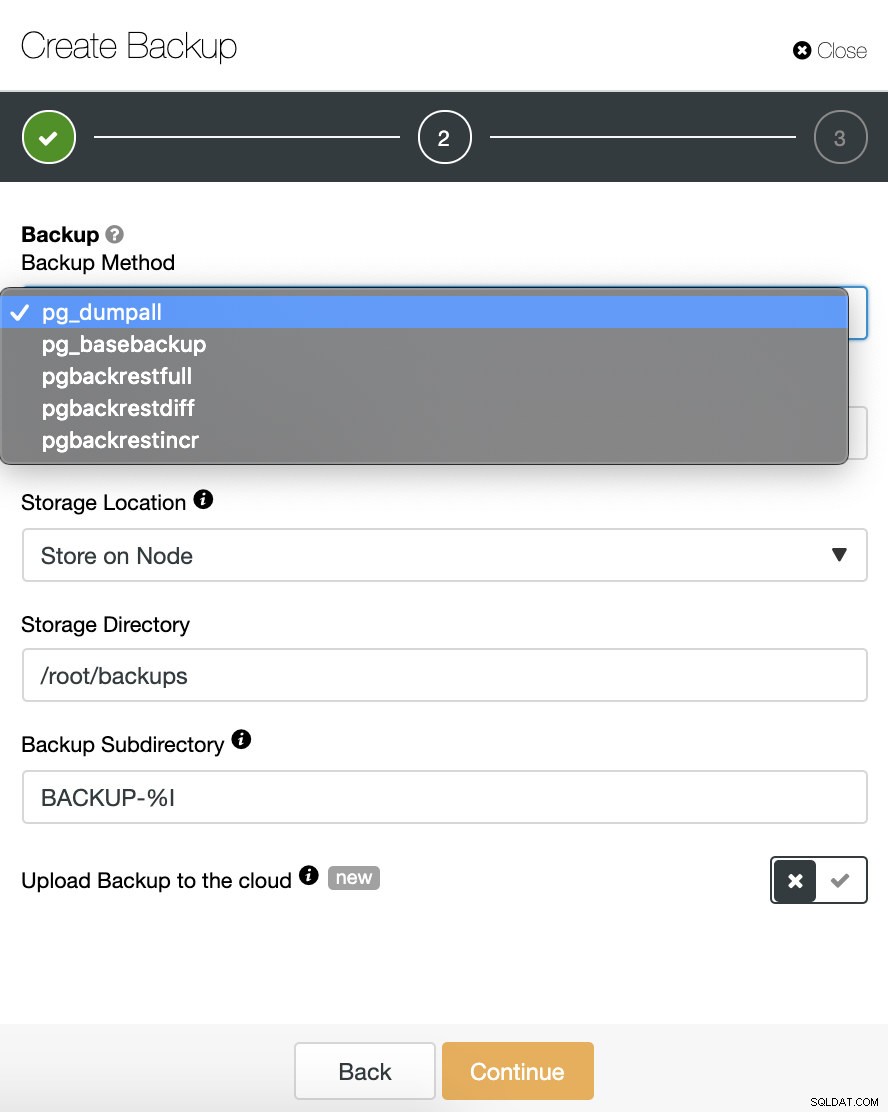
Devemos escolher um método, o servidor do qual o backup será feito e onde queremos armazenar o backup. Também podemos enviar nosso backup para a nuvem (AWS, Google ou Azure) ativando o botão correspondente.
Nesse caso, escolheremos o método pgbackrestfull para fazer um backup completo inicial. Ao selecionar esta opção, veremos a seguinte nota vermelha:
“Durante a primeira tentativa de fazer backup do pgBackRest, o ClusterControl reconfigurará o nó (implanta e configura o pgBackRest) e depois disso o nó db precisa ser reiniciado primeiro.”
Então, por favor, leve isso em consideração na primeira tentativa de backup.
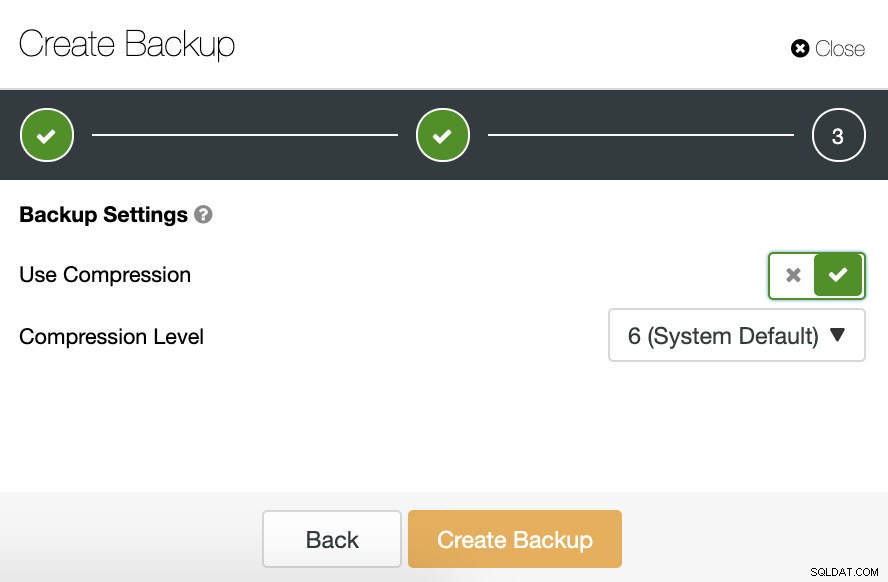
Em seguida, especificamos o uso da compactação e o nível de compactação para nosso backup.
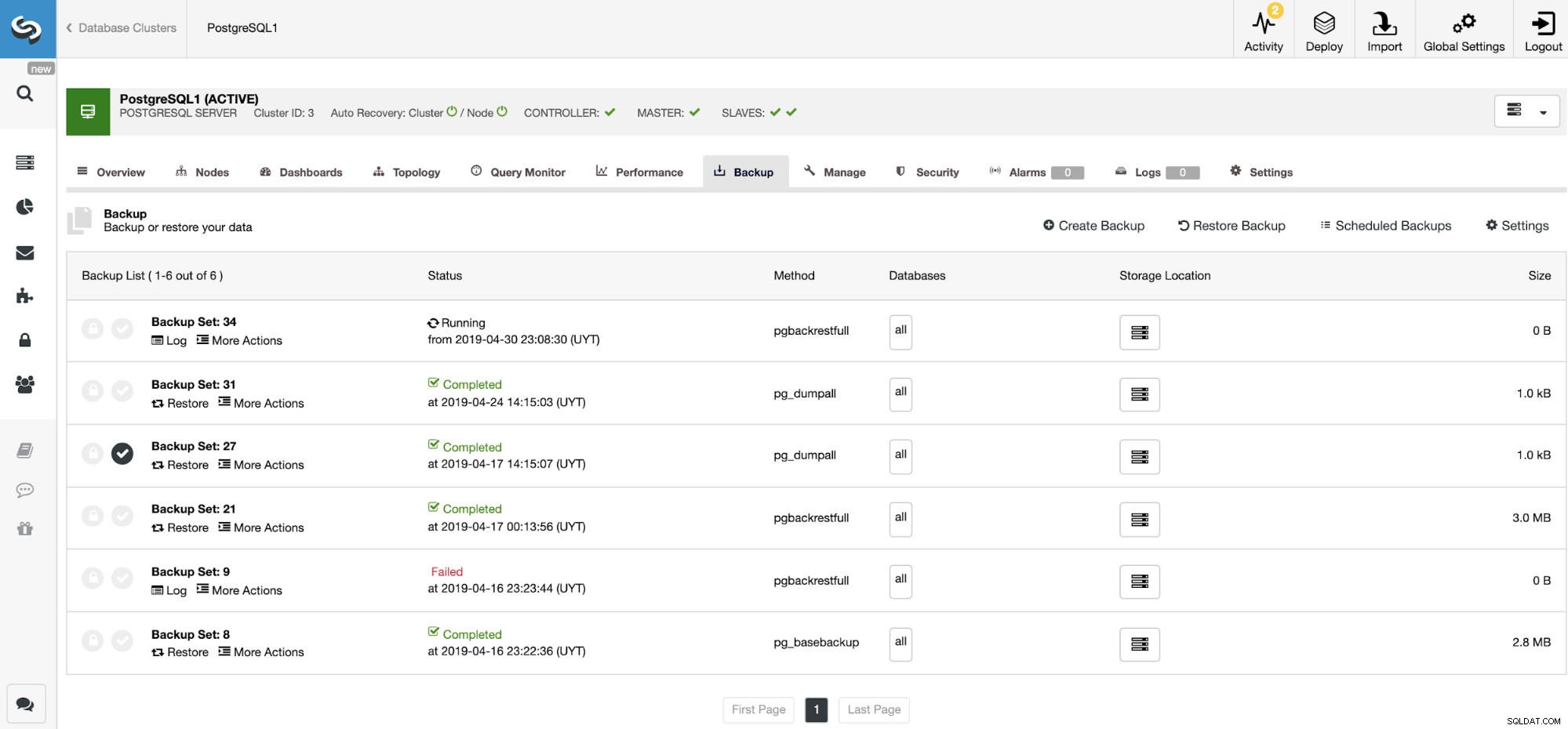
Na seção de backup, podemos ver o andamento do backup e informações como método, tamanho, local e muito mais.
As etapas são as mesmas para criar um diferencial de backup incremental. Só precisamos escolher o método desejado durante a criação do backup.
Restaurando um backup
Quando o backup estiver concluído, podemos restaurá-lo usando o ClusterControl. Para isso, em nossa seção de backup (ClusterControl -> Select Cluster -> Backup), podemos selecionar "Restaurar Backup", ou diretamente "Restaurar" no backup que desejamos restaurar.
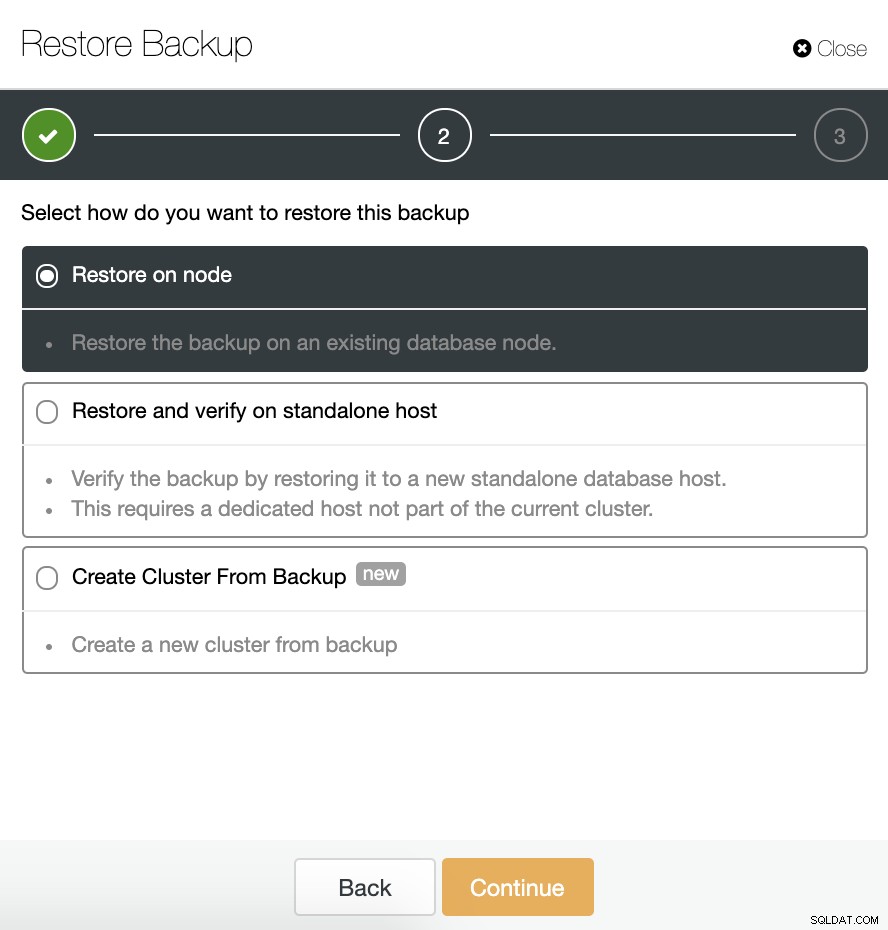
Temos três opções para restaurar o backup. Podemos restaurar o backup em um nó de banco de dados existente, restaurar e verificar o backup em um host autônomo ou criar um novo cluster a partir do backup.
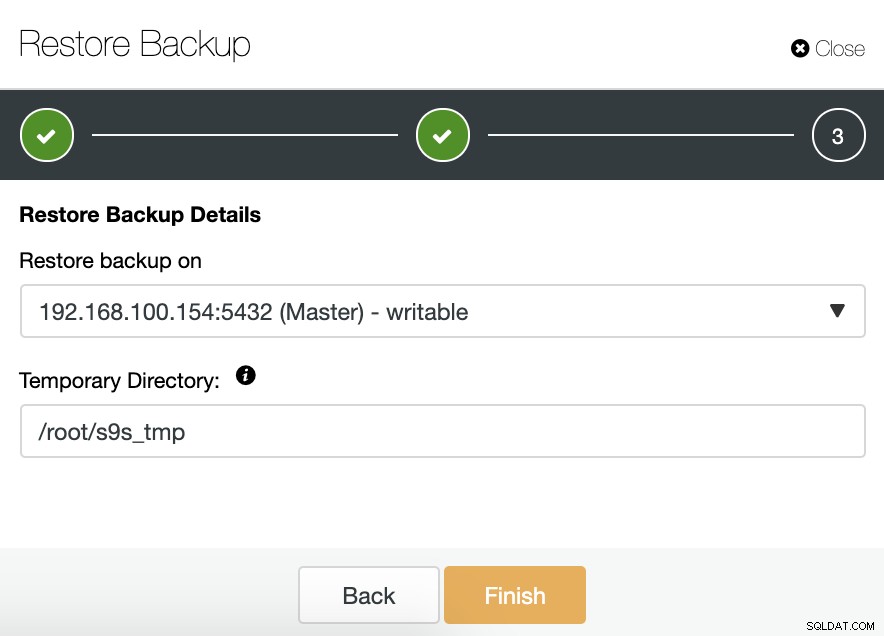
Se escolhermos a opção Restore on Node, devemos especificar o nó Master, pois é o único gravável no cluster.
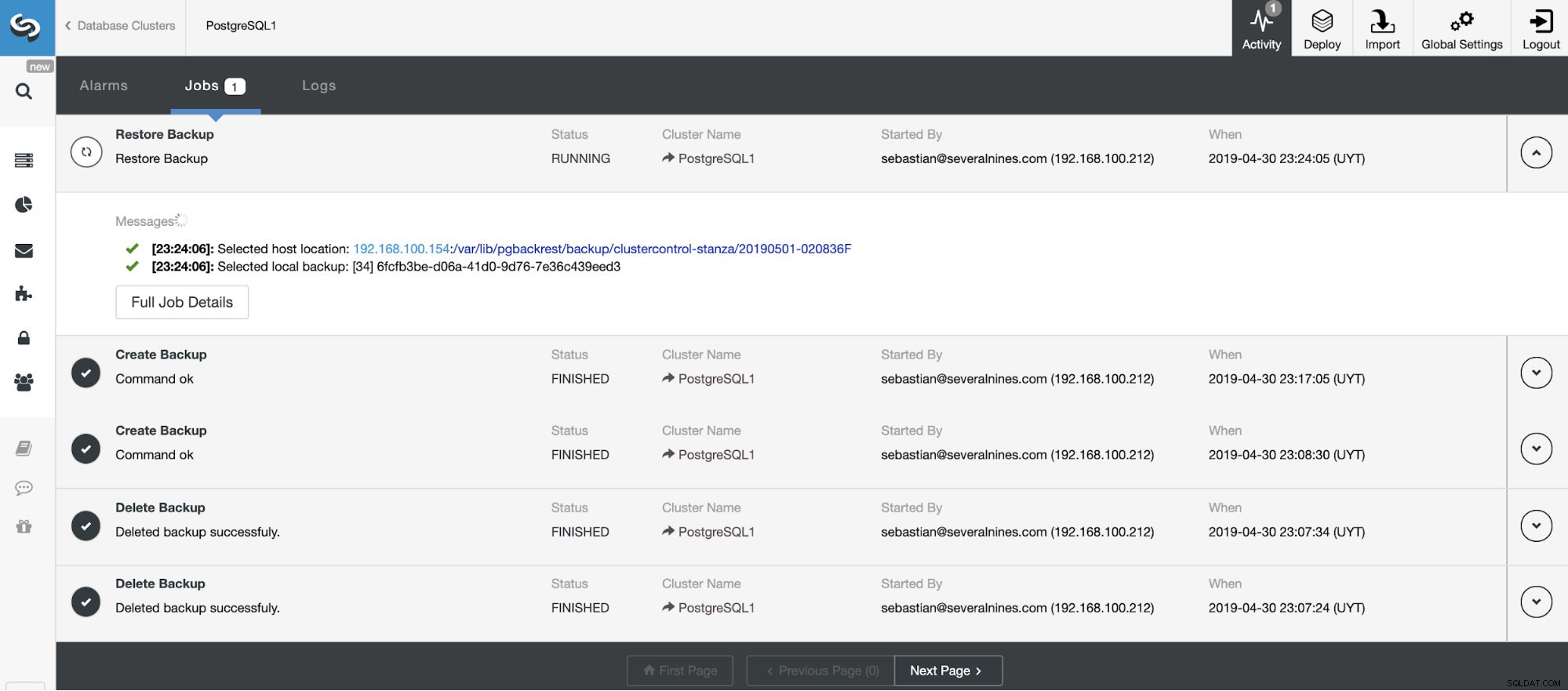
Podemos monitorar o progresso de nossa restauração na seção Activity em nosso ClusterControl.
Verificação automática de backup
Um backup não é um backup se não for restaurável. Verificar backups é algo que geralmente é negligenciado por muitos. Vamos ver como o ClusterControl pode automatizar a verificação de backups PostgreSQL e TimescaleDB e ajudar a evitar surpresas.
No ClusterControl, selecione seu cluster e vá para a seção "Backup" e, em seguida, selecione "Criar Backup".
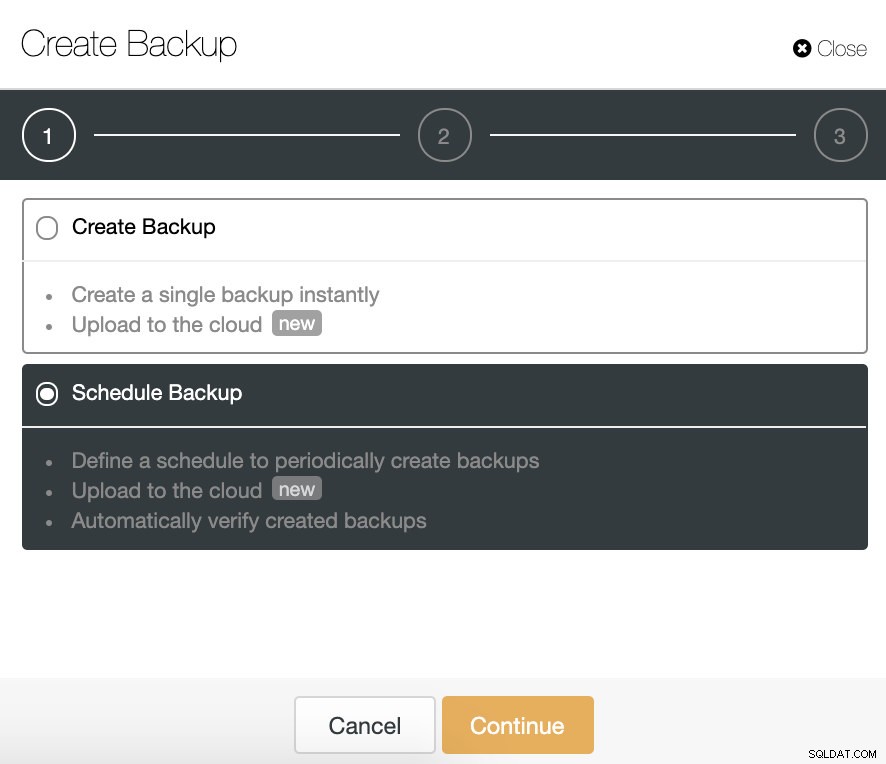
O recurso de backup de verificação automática está disponível para os backups agendados. Então, vamos escolher a opção “Agendar Backup”.
Ao agendar um backup, além de selecionar as opções comuns como método ou armazenamento, também precisamos especificar agendamento/frequência.
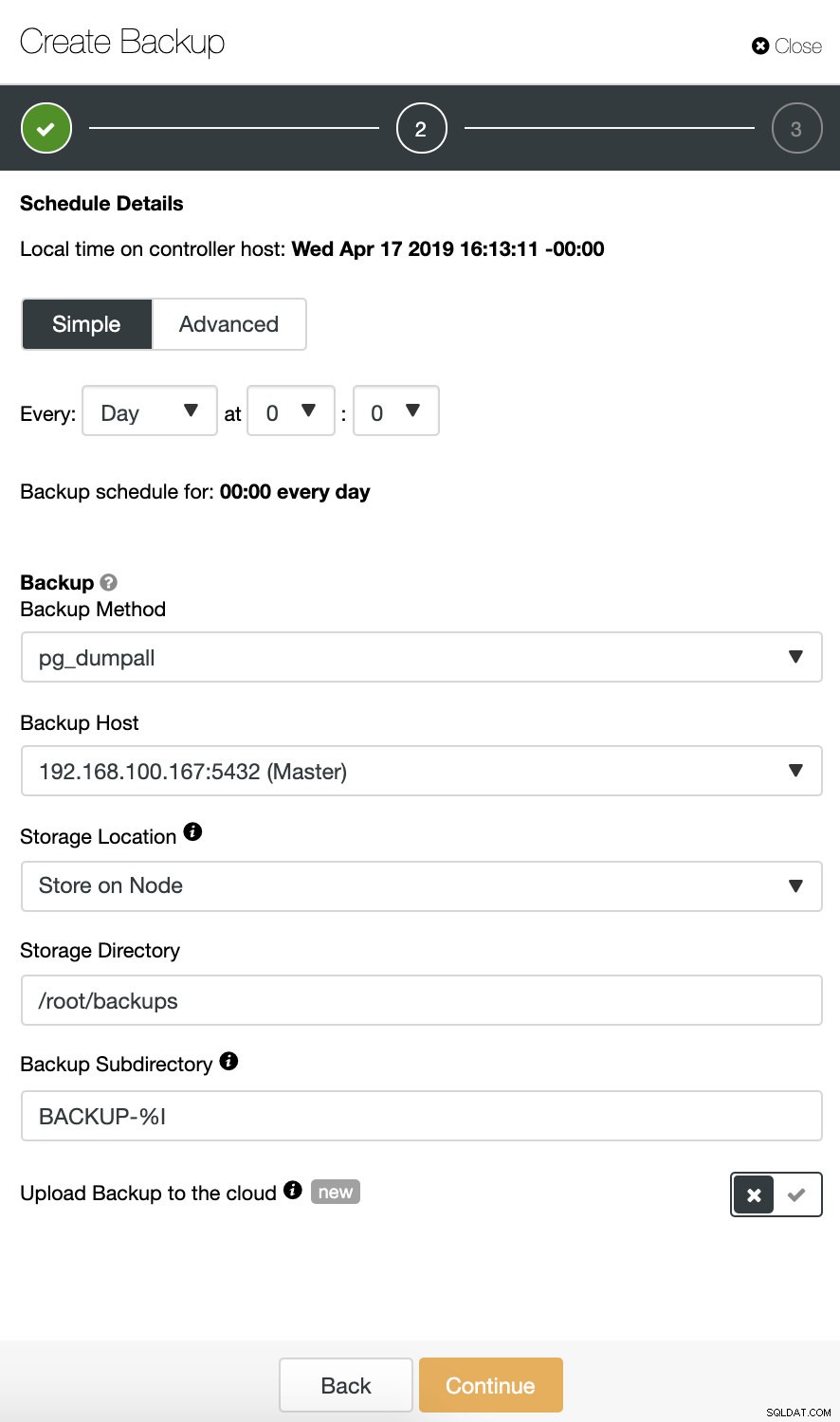
Na próxima etapa, podemos compactar nosso backup e ativar o recurso “Verificar backup”.
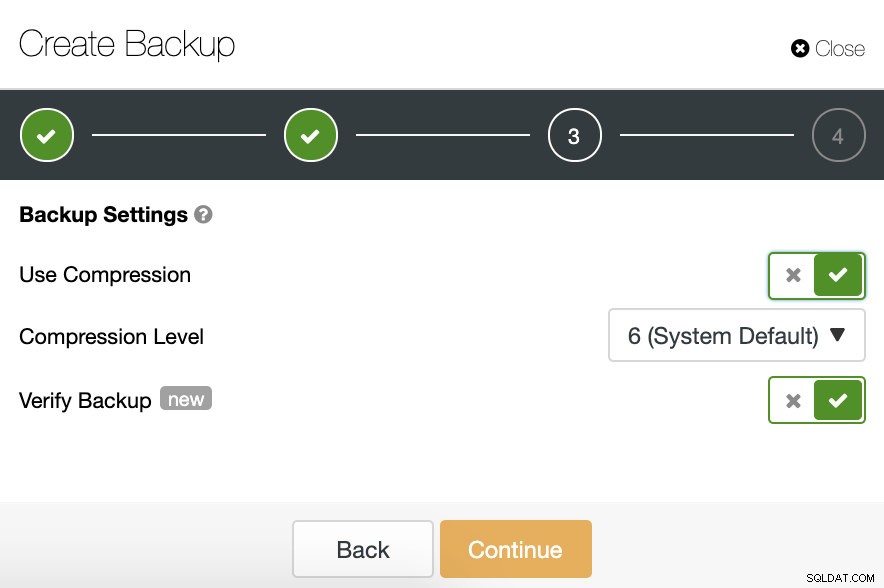
Para usar esse recurso, precisamos de um host dedicado (ou VM) que não faça parte do cluster.
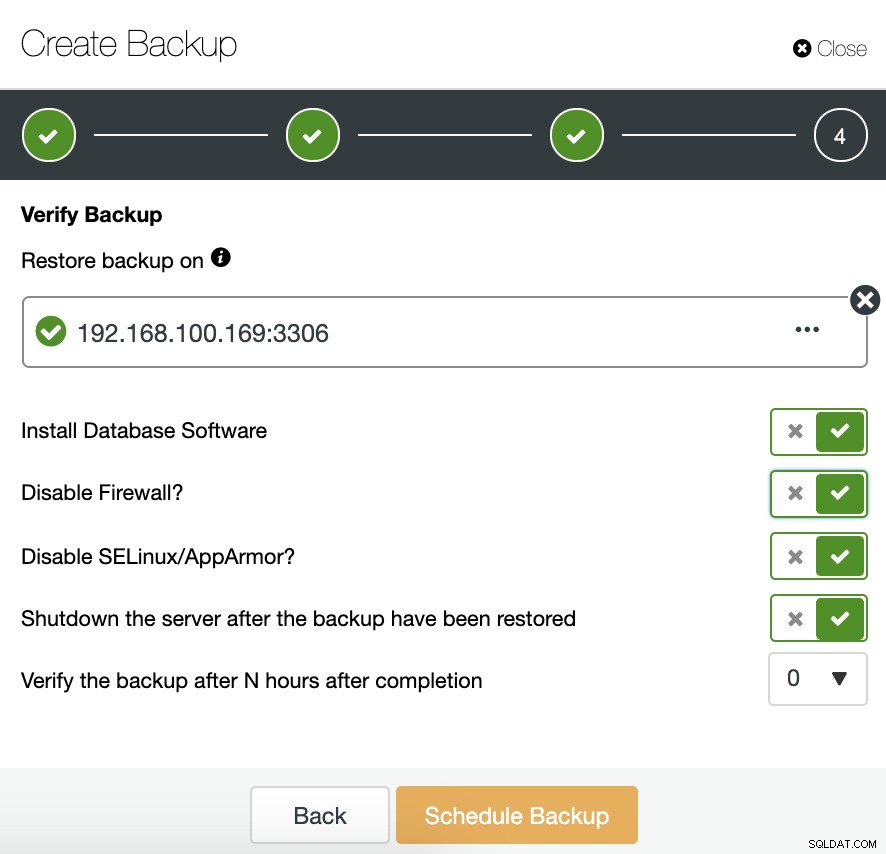
O ClusterControl instalará o software e restaurará o backup neste host. Após a restauração, podemos ver o ícone de verificação na seção Backup do ClusterControl.
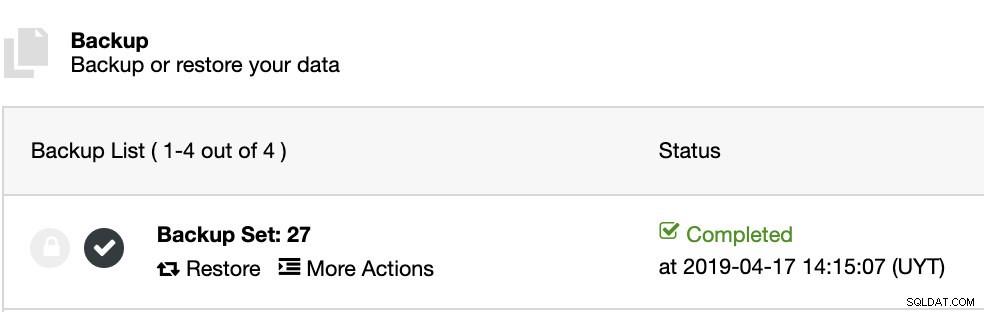
Recomendações
Existem também algumas dicas que podemos levar em consideração ao criar nossos backups:
- Armazenar o backup em um local remoto:não devemos armazenar o backup no servidor de banco de dados. Em caso de falha do servidor, podemos perder o banco de dados e o backup ao mesmo tempo.
- Mantenha uma cópia do backup mais recente no servidor de banco de dados:isso pode ser útil para uma recuperação mais rápida.
- Use backups incrementais/diferenciais:para reduzir o tempo de recuperação do backup e o uso do espaço em disco.
- Fazer backup dos WALs:se precisarmos restaurar um banco de dados do último backup, se você apenas restaurá-lo, perderá as alterações desde que o backup foi feito até o momento da restauração, mas se tivermos os WALs podemos aplicar as alterações e podemos usar PITR.
- Usar backups lógicos e físicos:ambos são necessários por motivos diferentes, por exemplo, se queremos restaurar apenas um banco de dados/tabela, não precisamos do backup físico, precisamos apenas do backup lógico e ele ser ainda mais rápido do que restaurar todo o servidor.
- Fazer backup dos nós em espera (se possível):para evitar carga extra no nó principal, é uma boa prática fazer o backup do servidor em espera.
- Teste seus backups:a confirmação de que o backup foi feito não é suficiente para garantir que o backup esteja funcionando. Devemos restaurá-lo em um servidor autônomo e testá-lo para evitar uma surpresa em caso de falha.
Conclusão
Como vimos, o pgBackRest é uma boa opção para melhorar nossa estratégia de backup. Ele ajuda você a proteger seus dados e pode ser útil alcançar o RTO reduzindo o tempo de inatividade em caso de falha. Os backups incrementais podem ajudar a reduzir o tempo e o espaço de armazenamento usados para o processo de backup. O ClusterControl pode ajudar a automatizar o processo de backup de seus bancos de dados PostgreSQL e TimescaleDB e, em caso de falha, restaurá-lo com apenas alguns cliques.



