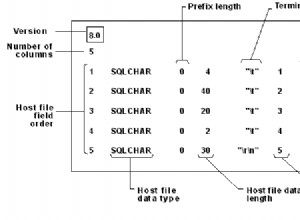
Um grande
OFFSET sempre vai ser lento. O Postgres tem que ordenar todas as linhas e contar o visível aqueles até o seu deslocamento. Para pular todas as linhas anteriores diretamente você pode adicionar um row_number indexado para a tabela (ou crie uma MATERIALIZED VIEW incluindo o dito row_number ) e trabalhe com WHERE row_number > x em vez de OFFSET x . No entanto, essa abordagem só é sensata para dados somente leitura (ou principalmente). Implementando o mesmo para dados de tabela que podem mudar simultaneamente é mais desafiador. Você precisa começar definindo o comportamento desejado exatamente .
Sugiro uma abordagem diferente para paginação :
SELECT *
FROM big_table
WHERE (vote, id) > (vote_x, id_x) -- ROW values
ORDER BY vote, id -- needs to be deterministic
LIMIT n;
Onde
vote_x e id_x são do último linha da página anterior (para ambos DESC e ASC ). Ou desde o primeiro se estiver navegando para trás . A comparação de valores de linha é suportada pelo índice que você já possui - um recurso que está em conformidade com o padrão ISO SQL, mas nem todos os RDBMS o suportam.
CREATE INDEX vote_order_asc ON big_table (vote, id);
Ou para ordem decrescente:
SELECT *
FROM big_table
WHERE (vote, id) < (vote_x, id_x) -- ROW values
ORDER BY vote DESC, id DESC
LIMIT n;
Pode usar o mesmo índice.
Sugiro que você declare suas colunas
NOT NULL ou familiarize-se com o NULLS FIRST|LAST construir:- PostgreSQL classifica por datetime asc, null primeiro?
Observe duas coisas em particular:
-
AROWvalores emWHEREcláusula não pode ser substituída por campos de membro separados.WHERE (vote, id) > (vote_x, id_x)não pode ser substituído por:
WHERE vote >= vote_x AND id > id_x
Isso excluiria todos linhas comid <= id_x, enquanto queremos fazê-lo apenas para a mesma votação e não para a próxima. A tradução correta seria:
WHERE (vote = vote_x AND id > id_x) OR vote > vote_x
... que não funciona tão bem com os índices e fica cada vez mais complicado para mais colunas.
Seria simples para um único coluna, obviamente. Esse é o caso especial que mencionei no início.
-
A técnica não funciona para direções mistas emORDER BYComo:
ORDER BY vote ASC, id DESC
Pelo menos não consigo pensar em um genérico maneira de implementar isso com a mesma eficiência. Se pelo menos uma das duas colunas for um tipo numérico, você pode usar um índice funcional com um valor invertido em(vote, (id * -1))- e use a mesma expressão emORDER BY:
ORDER BY vote ASC, (id * -1) ASC
Relacionado:
- Termo de sintaxe SQL para 'WHERE (col1, col2) <(val1, val2)'
- Melhore o desempenho para ordenar com colunas de muitas tabelas
Observe em particular a apresentação de Markus Win e I vinculada a:
- "Paginação feita à maneira do PostgreSQL"